記事ディレクトリ:
-
MySQLとは何ですか?*
-
MySQLで一般的に使用されるストレージエンジンは何ですか?それらの違いは何ですか?***
-
データベースの3つのパラダイム**
-
MySQLのデータ型は何ですか**
-
索引***
-
インデックスとは何ですか?
-
インデックス作成の長所と短所は何ですか?
-
インデックスデータ構造?
-
ハッシュインデックスとB+ツリーの違いは?
-
インデックスの種類は何ですか?
-
インデックスの種類は何ですか?
-
BツリーとB+ツリーの違いは何ですか?
-
データベースがBツリーの代わりにB+ツリーを使用するのはなぜですか?
-
クラスター化インデックスとは何ですか?非クラスター化インデックスとは何ですか?
-
非クラスター化インデックスはテーブルに戻るクエリを実行しますか?
-
インデックスの使用シナリオは何ですか?
-
インデックスデザインの原則?
-
インデックスを最適化する方法は?
-
インデックスを作成/削除する方法は?
-
インデックスを使用してクエリを実行すると、パフォーマンスが確実に向上しますか?
-
プレフィックスインデックスとは何ですか?
-
左端の一致原理は何ですか?
-
インデックスはいつ失敗しますか?
-
-
データベーストランザクション***
-
データベーストランザクションとは何ですか?
-
トランザクションの4つの特徴は何ですか?
-
データベースの同時実行性の一貫性の問題
-
データベースの分離レベルはどれくらいですか?
-
分離レベルはどのように達成されますか?
-
MVCCとは何ですか?
-
-
データベースロック***
-
データベースロックとは何ですか?
-
データベースロックと分離レベルの関係は?
-
データベースロックの種類は何ですか?
-
MySQLのInnoDBエンジンの行ロックモードとそれはどのように実装されていますか?
-
データベースの楽観的ロックと悲観的ロックとは何ですか?また、それらを実装する方法は?
-
デッドロックとは何ですか?それを回避する方法は?
-
-
SQLステートメントの基本
-
SQLステートメントの主なカテゴリは何ですか?
-
SQLの制約は何ですか?****
-
サブクエリとは何ですか?****
-
MySQLのいくつかの接続クエリを知っていますか?***
-
との違いはmysqlにありますか?****
-
varcharとcharの違いは?***
-
MySQLのint(10)とchar(10)およびvarchar(10)の違いは?***
-
ドロップ、削除、切り捨ての違いは何ですか?****
-
UNIONとUNIONALLの違いは?****
-
一時テーブルとは何ですか?一時テーブルはいつ使用され、いつ削除されますか?*
-
大きなテーブルデータクエリを最適化する方法は?***
-
遅いログクエリについて知っていますか?統計はクエリには遅すぎますか?遅いクエリを最適化する方法は?***
-
なぜ主キーを設定するのですか?****
-
主キーは通常、自動インクリメントIDまたはUUIDを使用しますか?****
-
フィールドをnull以外に設定する必要があるのはなぜですか?**
-
クエリ中のデータアクセスを最適化する方法は?***
-
長くて難しいクエリを最適化する方法は?****
-
LIMITページネーションを最適化する方法は?****
-
UNIONクエリを最適化する方法**
-
WHERE句を最適化する方法***
-
SQLステートメントの実行が遅い理由は何ですか?***
-
SQLステートメントの実行順序?*
-
-
データベースの最適化
-
大きなテーブルを最適化する方法は?***
-
垂直サブテーブル、垂直サブライブラリ、水平サブテーブル、水平サブライブラリとは何ですか?***
-
サブデータベースとサブテーブルの後にIDキーを処理するにはどうすればよいですか?***
-
MySQLレプリケーションの原則とプロセス?マスタースレーブレプリケーションを実装する方法は?***
-
読み取りと書き込みの分離を理解していますか?***
-
MySQLとは何ですか?*
Baidu百科事典に関する説明:MySQLは、データベース管理に最も一般的に使用されるデータベース管理言語である構造化照会言語(SQL)を使用するオープンソースのリレーショナルデータベース管理システム(RDBMS)です。MySQLはオープンソースであるため、誰でもGeneral Public Licenseの下でダウンロードし、個々のニーズに応じて変更できます。
MySQLで一般的に使用されるストレージエンジンは何ですか?それらの違いは何ですか?***
-
InnoDB
InnoDBはMySQLのデフォルトのストレージエンジンであり、トランザクション、行ロック、外部キーなどの操作をサポートします。
-
MyISAM
MyISAMは、MySQL 5.1より前のデフォルトのストレージエンジンです。MyISAMは同時実行性が低く、トランザクションや外部キーなどの操作をサポートしていません。デフォルトのロックの粒度はテーブルレベルのロックです。
| InnoDB | MyISAM | |
|---|---|---|
| 外部キー | サポート | サポートしません |
| 事務 | サポート | サポートしません |
| ロック | テーブルロックと行ロックをサポート | テーブルロックをサポート |
| 回復可能性 | トランザクションログからの回復 | トランザクションログなし |
| テーブル構造 | データとインデックスは一元的に保存され、.ibdと.frm | データとインデックスは別々に保存されます、データ.MYD、インデックス.MYI |
| クエリのパフォーマンス | 一般的にMyISAMよりも悪い | 一般的にInnoDBよりも悪い |
| 索引 | クラスター化されたインデックス | 非クラスター化インデックス |
データベースの3つのパラダイム**
-
第一正規形:各列がアトミックのままであり、データテーブルのすべてのフィールド値が分解不可能なアトミック値であることを確認してください。
-
2番目の正規形:テーブルのすべての列が主キーに関連していることを確認してください
-
第3正規形:各列が間接的に関連するのではなく、主キー列に直接関連していることを確認します
MySQLのデータ型は何ですか**
-
整数
TINYINT、SMALLINT、MEDIUMINT、INT、およびBIGINTは、それぞれ8、16、24、32、および64ビットのストレージスペースを占有します。INT(10)の10は、表示される文字の数を表すだけであり、実用的な意味はないことに注意してください。UNSIGNED ZEROFILLと組み合わせて使用することは一般的に意味があります。たとえば、データ型はINT(3)で、属性はUNSIGNED ZEROFILLです。挿入されたデータが3の場合、実際に格納されるデータは003です。
-
浮動小数点数
FLOAT、DOUBLE、およびDECIMALは浮動小数点数であり、DECIMALは文字列によって処理され、正確な小数を格納できます。FLOATおよびDOUBLEと比較すると、DECIMALの効率は低くなります。FLOAT、DOUBLE、およびDECIMALはすべて列幅を指定できます。たとえば、FLOAT(5,2)は合計5ビットを意味し、2ビットは小数部分を格納し、3ビットは整数部分を格納します。
-
ストリング
一般的に使用される文字列はCHARとVARCHARです。VARCHARは主に可変長文字列を格納するために使用されるため、固定長CHARと比較してスペースを節約できます。CHARは固定長であり、定義された文字列長に従ってスペースを割り当てます。
アプリケーションシナリオ:頻繁に変更されるデータにはCHARを使用することをお勧めします。また、CHARは断片化する傾向がありません。非常に短い列の場合は、VARCHARよりも効率的なCHARを使用することをお勧めします。一般に、TEXT / BLOBなどのタイプの使用は避けてください。クエリ時に一時テーブルが使用され、パフォーマンスのオーバーヘッドが深刻になるためです。
-
日にち
より一般的に使用されるのは、年、時刻、日付、日時、タイムスタンプなどです。datetimeは、タイムゾーンに関係なく、8バイトのストレージスペースを使用して、1000から9999までの時間を秒単位の精度で保存します。タイムスタンプはUNIXタイムスタンプと同じで、1970年1月1日の深夜から2038年までの時間を秒単位の精度で保存し、4バイトのストレージスペースを使用し、タイムゾーンに依存します。
アプリケーションシナリオ:日時よりもスペース効率が高いタイムスタンプを使用してみてください。
索引***
インデックスとは何ですか?
Baidu百科事典の説明:インデックスは、データベーステーブルの1つ以上の列の値を並べ替える構造です。インデックスを使用すると、データテーブルの特定の情報にすばやくアクセスできます。
インデックス作成の長所と短所は何ですか?
アドバンテージ:
-
データ検索を大幅に高速化します。
-
ランダムI/OをシーケンシャルI/Oに変換します(B +ツリーの葉が相互に接続されているため)
-
テーブルとテーブル間の接続を加速します
欠点:
-
スペースの観点から、インデックスを作成するには物理的なスペースが必要です
-
時間の観点から、インデックスの作成と維持には時間がかかります。たとえば、データの追加、削除、変更を行う場合は、インデックスを維持する必要があります。
インデックスデータ構造?
インデックスのデータ構造には主にB+ツリーとハッシュテーブルが含まれ、対応するインデックスはそれぞれB+ツリーインデックスとハッシュインデックスです。InnoDBエンジンのインデックスタイプには、B+ツリーインデックスとハッシュインデックスが含まれます。デフォルトのインデックスタイプはB+ツリーインデックスです。
-
B+ツリーインデックス
データ構造に精通している学生は、B +ツリー、バランスの取れたバイナリツリー、および赤黒木がすべて古典的なデータ構造であることを知っています。次の図に示すように、B +ツリーでは、すべてのレコードノードがキー値の順序でリーフノードに配置されます。
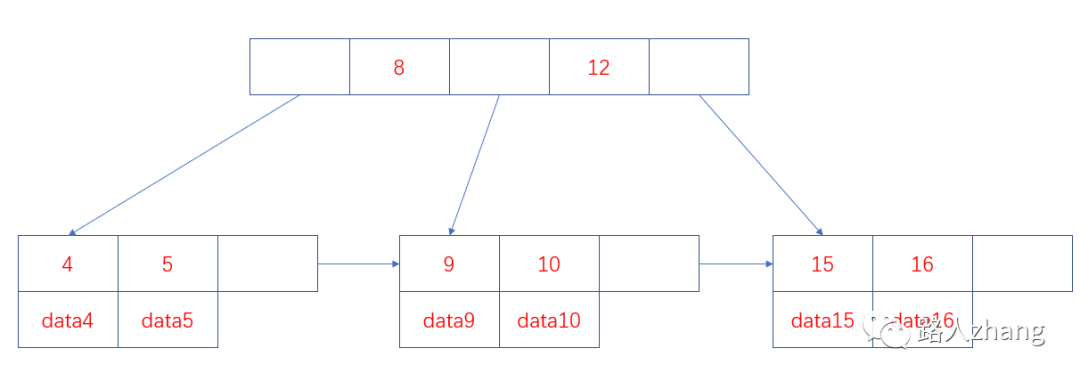
上の図からわかるように、B +ツリーが順序付けられ、すべてのデータがリーフノードに格納されるため、検索効率が非常に高く、並べ替えと範囲検索をサポートします。
B +ツリーのインデックスは、プライマリインデックスと補助インデックスに分けることができます。プライマリインデックスはクラスター化インデックスであり、セカンダリインデックスは非クラスター化インデックスです。クラスター化インデックスは、B +ツリーインデックスのキー値として主キーで構成されるB+ツリーインデックスです。クラスター化インデックスのリーフノードは完全なデータレコードを格納します。非クラスター化インデックスは、非主キー列をキーとして使用します。 B+ツリーインデックスの値。形成されたB+ツリーインデックス、非クラスター化インデックスのリーフノードは主キー値を格納します。したがって、非クラスター化インデックスを使用してクエリを実行する場合、最初に主キーの値が検出され、次にクラスター化インデックスに従って主キーに対応するデータフィールドが検出されます。上の図のリーフノードには、クラスター化インデックスの構造図であるデータレコードが格納されています。非クラスター化インデックスの構造は次のとおりです。
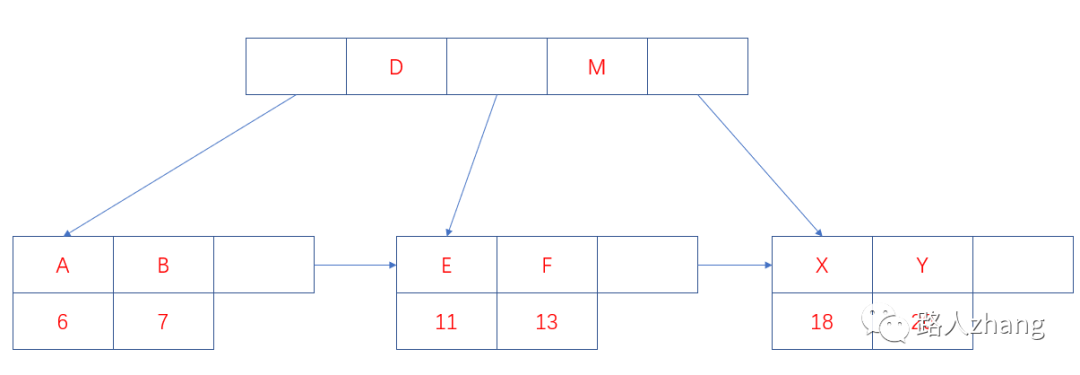
上図の文字は、データの非主キーの列値です。列値Bの情報を照会する場合は、最初に主キー7を検索してから、対応するデータフィールドを照会する必要があります。クラスタ化インデックスの主キー7に。
-
ハッシュインデックス
ハッシュインデックスはハッシュテーブルに基づいて実装されます。データの各行について、ストレージエンジンはインデックス列に対してハッシュ計算を実行してハッシュコードを取得します。ハッシュアルゴリズムは、異なる列値が確実に計算されるようにする必要があります。ハッシュコードの値が異なり、ハッシュコードの値がハッシュテーブルのキー値として使用され、データ行へのポインタがハッシュテーブルの値として使用されます。このように、データを見つける時間計算量はO(1)であり、これは一般に正確な検索に使用されます。
ハッシュインデックスとB+ツリーの違いは?
2つのデータ構造が異なるため、使用シナリオも異なります。ハッシュインデックスは通常、正確な同等の検索に使用され、B +インデックスは、正確な同等の検索を除く他の検索に主に使用されます。ほとんどの場合、B+ツリーインデックスを使用することを選択します。
-
ハッシュテーブルは順序付けされていないため、ハッシュインデックスは並べ替えをサポートしていません。
-
ハッシュインデックスは範囲ルックアップをサポートしていません。
-
ハッシュインデックスは、複数列インデックスのファジークエリと左端のプレフィックスマッチングをサポートしていません。
-
ハッシュテーブルでハッシュの競合が発生するため、ハッシュインデックスのパフォーマンスは不安定ですが、B +ツリーインデックスのパフォーマンスは比較的安定しており、各クエリはルートノードからリーフノードまでです。
インデックスの種類は何ですか?
MySQLの主なインデックスタイプは、FULLTEXT、HASH、BTREE、RTREEです。
-
全文
FULLTEXTはフルテキストインデックスです。MyISAMストレージエンジンとInnoDBストレージエンジンは、MySQL 5.6.4以降でフルテキストインデックスをサポートしています。これは通常、キーワードが等しいかどうかを直接比較するのではなく、テキスト内のキーワードを検索するために使用されます。 VARCHAR、TAXTおよびその他のデータタイプフルテキストインデックスを作成します。全文索引は主に、WHERE name LIKE "%zhang%"などのテキストに対するファジークエリの効率が低いという問題を解決するために使用されます。
-
ハッシュ
HASHはハッシュインデックスです。ハッシュインデックスは主に同等のクエリに使用されます。時間計算量はO(1)で、非常に効率的ですが、並べ替え、範囲クエリ、ファジークエリをサポートしていません。
-
BTREE
BTREEは、INnoDBストレージエンジンのデフォルトインデックスであるB +ツリーインデックスであり、並べ替え、グループ化、範囲クエリ、ファジークエリなどをサポートし、安定したパフォーマンスを発揮します。
-
RTREE
RTREEは、地理データの保存に主に使用される空間データインデックスです。他のインデックスと比較すると、空間データインデックスの利点は範囲検索にあります。
インデックスの種類は何ですか?
-
主キーインデックス:データ列を複製することはできません。NULLにすることはできません。また、テーブルに含めることができる主キーインデックスは1つだけです。
-
複合インデックス:複数の列値で構成されるインデックス。
-
一意のインデックス:データ列を繰り返すことはできず、NULLにすることができます。インデックス列の値は一意である必要があります。複合インデックスの場合、列値の組み合わせは一意である必要があります。
-
フルテキストインデックス:テキストのコンテンツを検索します。
-
通常のインデックス:基本的なインデックスタイプ、NULLにすることができます
BツリーとB+ツリーの違いは何ですか?
BツリーとB+ツリーには主に2つの違いがあります。
-
Bツリーの内部ノードとリーフノードは両方ともキーと値を格納しますが、B +ツリーの内部ノードにはキーのみがあり、値はありません。リーフノードはすべてのキーと値を格納します。
-
B +ツリーのリーフノードは、順次取得を容易にするために相互に接続されています。
2つの構造図は次のとおりです。
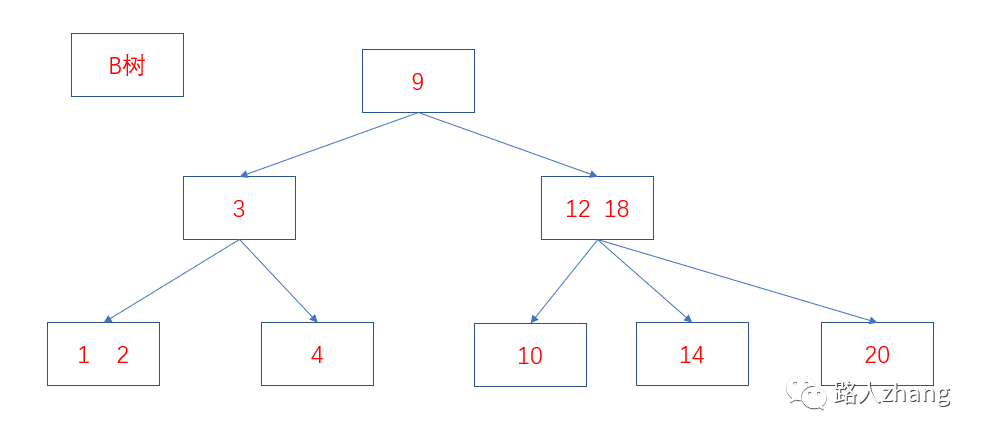
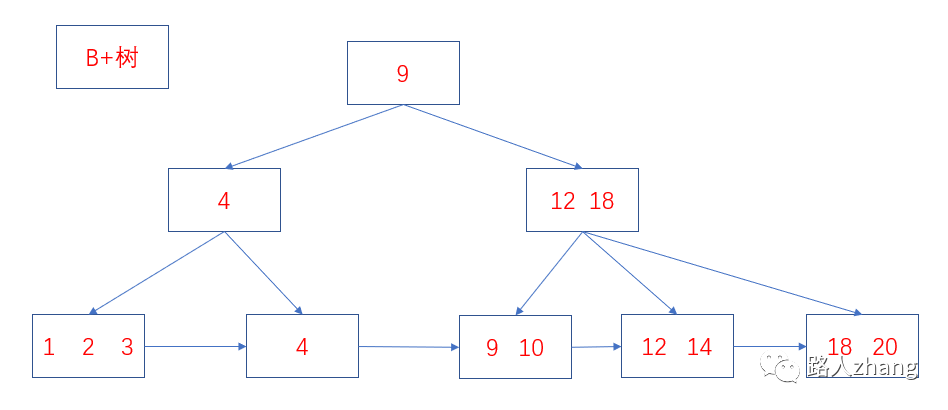
データベースがBツリーの代わりにB+ツリーを使用するのはなぜですか?
-
Bツリーはランダム検索に適しており、B+ツリーはランダムおよびシーケンシャル検索に適しています
-
Bツリーの各ノードはキーと値を格納する必要があるのに対し、B +ツリーの内部ノードはキーのみを格納する必要があるため、B +ツリーのスペース使用率は高くなります。これにより、B+ツリーのノードはより多くのインデックスを格納できます。ツリーの高さを低くすると、I / Oの数が減り、データの取得が速くなります。
-
B +ツリーのリーフノードはすべて相互に接続されているため、範囲検索と順次検索の方が便利です。
-
B +ツリーでは、各クエリがルートノードからリーフノードまでであるのに対し、Bツリーでは、クエリされる値がリーフノードにない可能性があるため、B+ツリーのパフォーマンスはより安定しています。内部ノードで見つかりました。
Bツリーの内部ノードも値を格納できるため、どのような状況でBツリーを使用するのが適していますか。そのため、頻繁にアクセスされる値をルートノードの近くに配置して、クエリの効率を向上させることができます。要約すると、B+ツリーのパフォーマンスはデータベースインデックスとしてより適しています。
クラスター化インデックスとは何ですか?非クラスター化インデックスとは何ですか?
クラスター化インデックスと非クラスター化インデックスの主な違いは、データとインデックスが別々に格納されるかどうかです。
-
クラスター化インデックス:データとインデックスは一緒に格納され、インデックス構造のリーフノードはデータ行を保持します。
-
非クラスター化インデックス:データエントリとインデックスは別々に保存され、インデックスリーフノードはデータ行を指すアドレスを保存します。
InnoDBストレージエンジンでは、デフォルトのインデックスはB +ツリーインデックスです。主キーを使用して作成されたインデックスは、クラスター化インデックスでもあるプライマリインデックスであり、プライマリインデックスで作成されたインデックスはセカンダリインデックスです。また、非クラスター化インデックス。セカンダリインデックスのリーフノードにプライマリキーが格納されているため、プライマリインデックスの上にセカンダリインデックスが作成されるのはなぜですか。
MyISAMストレージエンジンでは、デフォルトのインデックスもB +ツリーインデックスですが、プライマリインデックスとセカンダリインデックスはどちらも非クラスター化インデックスです。つまり、インデックス構造のリーフノードはデータ行を指すアドレスを格納します。また、セカンダリインデックスを使用して、プライマリキーへのアクセスを必要としないインデックスを取得します。
あなたは2つの非常に古典的な写真からそれらの違いを見ることができます(写真はインターネットからのものです):
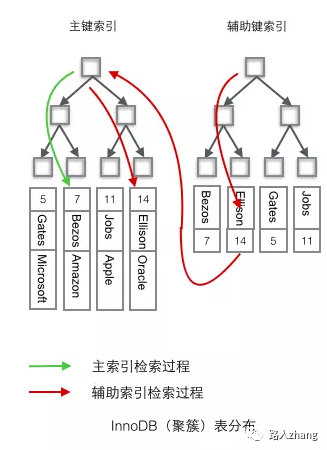
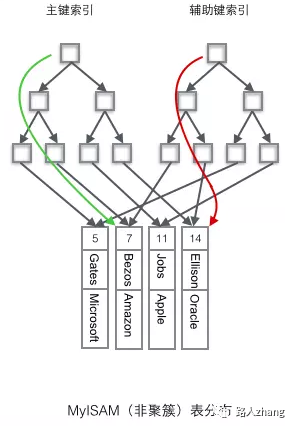
非クラスター化インデックスはテーブルに戻るクエリを実行しますか?
上記は、非クラスター化インデックスのリーフノードが主キーを格納することを意味します。つまり、主キーは非クラスター化インデックスを介して検索され、次に主キーに対応するデータはクラスタ化インデックス、次に主キーはクラスタ化インデックスから検出されます。対応するデータのプロセスはテーブルへのクエリバックであるため、非クラスタ化インデックスは間違いなくテーブルへのクエリバックを実行しますか?
答えは必ずしもそうではありません。これにはインデックスカバレッジの問題が含まれます。クエリされたデータが補助インデックスで完全に取得できる場合は、クエリのためにテーブルに戻る必要はありません。たとえば、id、name、ageなどのフィールドを含む個人情報を格納するテーブルがあります。クラスタ化インデックスがキー値としてIDで構築されたインデックスであり、非クラスタ化インデックスがキー値として名前で構築されたインデックスであると仮定するとselect id,name from user where name = 'zhangsan';、データは次のことができるため、このクエリはテーブルに戻るクエリを必要としません。非クラスター化インデックスを介して既に取得されています。これは、インデックスカバレッジの場合です。クエリステートメントがこのような場合select id,name,age from user where name = 'zhangsan';、ageの値は非クラスター化インデックスを介して取得できないため、バックテーブルクエリを実行する必要があります。それはどのように解決されるべきですか?インデックスをカバーし、年齢と名前の共同インデックスを作成し、それを使用select id,name,age from user where name = 'zhangsan';してクエリを実行するだけです。
したがって、インデックスカバレッジは、非クラスタ化インデックスのテーブルに戻るクエリの問題を解決できます。
インデックスの使用シナリオは何ですか?
-
中規模および大規模のテーブルのインデックスを作成することは非常に効果的です。非常に小さなテーブルの場合、全表スキャンは一般的に高速です。
-
非常に大きなテーブルの場合、インデックスの作成と保守のコストも高くなるため、現時点ではパーティション化テクノロジーを検討できます。
-
テーブルへの追加、削除、変更が多く、クエリの需要が非常に少ない場合は、インデックスを維持するために価格も必要になるため、インデックスを作成する必要はありません。
-
条件にインデックスを付ける必要がない場所には通常表示されないフィールド。
-
複数のフィールドが頻繁に照会される場合は、共同索引付けを検討できます。
-
多くのフィールドがあり、フィールド値が繰り返されていない場合は、一意のインデックスを検討してください。
-
フィールドが多く、繰り返しがある場合は、通常のインデックスを検討してください。
インデックスデザインの原則?
-
インデックス作成に最適な列は、SELECTキーワードの後に表示される選択リストの列ではなく、whereまたは結合文で指定された列の後に表示される列です。
-
インデックス列のカーディナリティが大きいほど、インデックスの効果が高くなります。つまり、インデックス列の識別度が高くなるほど、インデックスの効果が高くなります。たとえば、性別などの識別度の低い列を指標として使用すると、列のカーディナリティが最大3つであり、そのほとんどが男性または女性であるため、効果は非常に低くなります。
-
インデックスが小さいほどディスクI/Oが少なくなり、インデックスキャッシュ内のブロックがより多くを保持できるため、可能な限り短いインデックスを使用し、長い文字列にインデックスを付ける場合はプレフィックス長を短く指定します。キー値を使用すると、クエリが高速になります。
-
可能な限り左端のプレフィックスを使用してください。
-
インデックスを付けすぎないでください。各インデックスには追加の物理スペースが必要であり、メンテナンスにも時間がかかるため、インデックスが多いほどよいでしょう。
インデックスを最適化する方法は?
実際、インデックスを最適化するための鍵は、インデックスの設計原則とアプリケーションシナリオに準拠し、要件を満たさないインデックスをインデックス設計原則とアプリケーションシナリオに準拠するインデックスに最適化することです。
インデックスの設計原則とアプリケーションシナリオに加えて、次の2つの側面も考慮することができます。
-
インデックスを使用できないため、クエリを実行するときにインデックス列を関数の式またはパラメータの一部にすることはできません。例えば
select * from table_name where a + 1 = 2 -
最も識別力のあるインデックスを最初に置く
-
select*は慎重に使用してください
インデックスの使用シナリオ、インデックスの設計原則、およびインデックスを最適化する方法は、問題と見なすことができます。
インデックスを作成/削除する方法は?
インデックスを作成します。
-
CREATEINDEXステートメントの使用
CREATE INDEX index_name ON table_name (column_list); -
CREATETABLEで作成
CREATE TABLE user( id INT PRIMARY KEY, information text, FULLTEXT KEY (information) ); -
ALTERTABLEを使用してインデックスを作成する
ALTER TABLE table_name ADD INDEX index_name (column_list);
ドロップインデックス:
-
主キーインデックスを削除します
alter table 表名 drop primary key -
他のインデックスを削除する
alter table 表名 drop key 索引名
インデックスを使用してクエリを実行すると、パフォーマンスが確実に向上しますか?
インデックスの作成と維持にはスペースと時間のコストがかかるため、必ずしもインデックスの使用シナリオとインデックスの設計原則に合理的にインデックスを使用する方法が記載されています。インデックスを不当に使用すると、クエリのパフォーマンスが向上します。劣化する。
プレフィックスインデックスとは何ですか?
プレフィックスインデックスとは、テキストまたは文字列の最初の数文字にインデックスを付けることを指します。これにより、インデックスの長さが短くなり、クエリ速度が速くなります。
使用シナリオ:プレフィックス間の区別が比較的高い場合。
プレフィックスインデックスの作成方法
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
判別が難しいprefix_lengthパラメータがあります。このパラメータはプレフィックス長の意味です。通常、以下の方法を使用して、最初に列全体の識別度を決定します。
SELECT COUNT(DISTINCT column_name) / COUNT(*) FROM table_name;
次に、プレフィックスの長さを計算するとき、それは列全体の識別に最も似ています。
SELECT COUNT(DISTINCT LEFT(column_name, prefix_length)) / COUNT(*) FROM table_name;
列全体で計算された識別の程度に近づくまで、prefix_lengthの値を常に調整します。
左端の一致原理は何ですか?
左端のマッチングの原則:左端から開始点として連続マッチングを開始し、範囲クエリ(<、>、between、like)に遭遇したときにマッチングを停止します。
たとえば、インデックス(a、b、c)を作成するには、次の状況でインデックスが使用されているかどうかを推測できます。
-
最初
select * from table_name where a = 1 and b = 2 and c = 3 select * from table_name where b = 2 and a = 1 and c = 3インデックスは、上記の2つのクエリプロセスのすべての値に使用されます。MySQLのオプティマイザはクエリの順序を自動的に最適化するため、その後のフィールドの置換はクエリ結果に影響しません。
-
二番目
select * from table_name where a = 1 select * from table_name where a = 1 and b = 2 select * from table_name where a = 1 and b = 2 and c = 3答えは、3つのステートメントすべてが左端から一致するため、3つのクエリステートメントすべてがインデックスを使用するということです。
-
第3
select * from table_name where b = 1 select * from table_name where b = 1 and c = 2答えは、左端から一致しないため、これら2つのクエリステートメントのどちらもインデックスを使用しないということです。
-
第4
select * from table_name where a = 1 and c = 2このクエリステートメントは、列aのインデックスのみを使用し、列cのインデックスは使用しません。これは、列bが中央でスキップされ、左端から連続して一致しないためです。
-
5番目
select * from table_name where a = 1 and b < 3 and c < 1このクエリでは、列aとbのみがインデックスを使用し、列cはインデックスを使用しません。これは、左端の一致するクエリの原則に従って、範囲クエリが検出されると停止するためです。
-
6番目
select * from table_name where a like 'ab%'; select * from table_name where a like '%ab' select * from table_name where a like '%ab%'列が文字列の場合、プレフィックスマッチングのみがインデックスを使用でき、インフィックスマッチングとサフィックスマッチングは全表スキャンのみを実行できます。
インデックスはいつ失敗しますか?
上記では、左端の一致原則に準拠していないいくつかの状況では、インデックスが失敗します。さらに、次の状況でも、インデックスが失敗します。
-
ある、またはその状態にある、例えば
select * from table_name where a = 1 or b = 3 -
インデックスで計算を行うと、インデックスが無効になります。
select * from table_name where a + 1 = 2 -
インデックスの型でデータ型を非表示に変換すると、インデックスが失敗します。たとえば
select * from table_name where a = '1'、インデックスが使用されると仮定すると、文字列を引用符で囲む必要があり、書き込まれると、インデックスselect * from table_name where a = 1は無効になります。 -
インデックスで関数を使用すると、インデックスが無効になります。
select * from table_name where abs(a) = 1 -
%で始まると、同様のクエリを使用するときにインデックスが失敗します
-
インデックスで使用してください!、=、<>は、たとえば、判断時にインデックスが失敗する原因になります
select * from table_name where a != 1 -
たとえば、インデックスフィールドでis null / is not nullの判断を使用すると、インデックスが失敗します。
select * from table_name where a is null
データベーストランザクション***
データベーストランザクションとは何ですか?
....ブロガーが怠惰で、単語数が多すぎて、書きたくない....記事はPDFになっているので、困っている友達は私にメッセージを送ってもらうことができます。無料で!