MapReuduce
1、MapReduceのコンセプト
Mapreduceは、分散コンピューティングプログラムのプログラミングフレームワークです。そのコア機能は、ユーザーが作成したビジネスロジックコードと独自のデフォルトコンポーネントを、Hadoopクラスターで同時に実行される完全な分散コンピューティングプログラムに統合することです。
Mapreduceはプログラミングが簡単で、スケーラビリティが高く、ペタバイトレベルのデータの処理には適していますが、リアルタイムデータ、チャーンコンピューティング、および有向グラフコンピューティングの処理には適していません。
2.MapReduceのデザインコンセプト
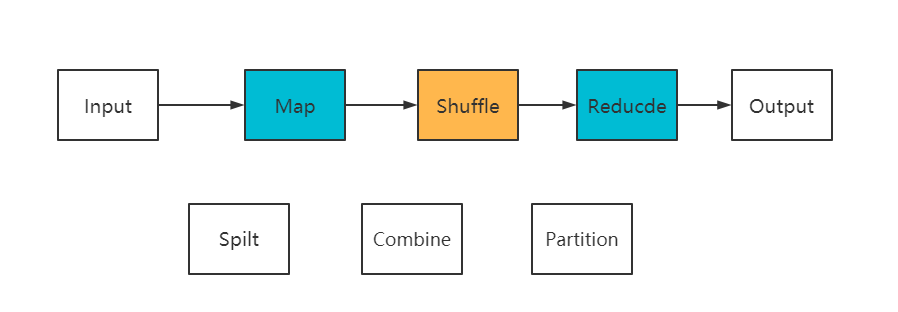
MapReduceの思考モジュールは主に次のように分けられますInput、Spilt、Map、Shuffle、Reduce。
Input:Readはデータを読み取ります。InputFormatはファイルを複数のInputSplitsに分割し、RecordReadersはInputSplitsをマップの出力として標準の<key、value>キーと値のペアに変換します。
Spilt:このプロセスでは、データを大まかに行に分割して、<Key、Value>タイプのデータを取得します。
マップ:<Key、List>タイプのデータを取得するためのきめ細かいセグメンテーション。リングバッファ内のファイルを並べ替えて分割します。データ量が多い場合は、ディスクに上書きされ、バッファのサイズによってMRタスクのパフォーマンス。デフォルトのサイズは100Mです。このプロセスでは、結合タスクを設定でき、同じキーに従って初期集計が実行されます(パーティション> 3が結合されます)。
結合:マージの予備的な集約。これには、主にパーティション番号や同じキーなどの戦略が含まれ、同じパーティション内のデータが順序付けられます。
Shuufle:シャッフル、つまり、各MapTaskの結果を組み合わせてReduceに出力します。このプロセスデータの出力はコピープロセスです。このプロセスには、時間のかかるプロセスでありコアプロセスであるネットワークIOが含まれます。
削減:分割されたデータフラグメントをマージします。マージソートが含まれます。
パーティション:カスタム出力パーティションをサポートします。デフォルトの分類子はHashPartitionです。式:(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
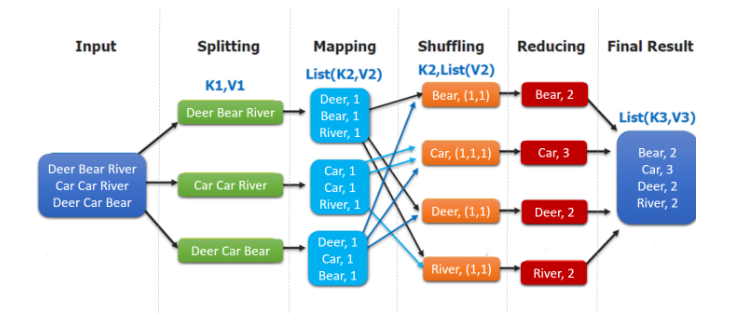
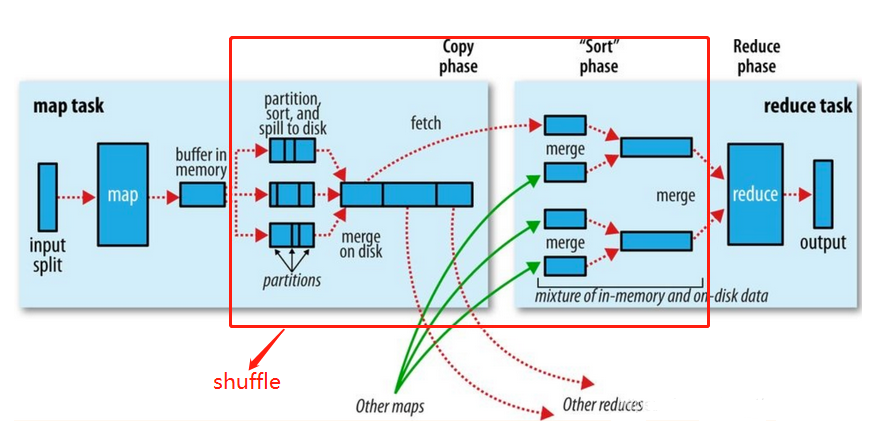
MapReduceの特定の実行プロセスを説明してみましょう:
- クライアントがタスクを送信する前に、(InputFormat)は構成戦略に従ってデータをスライスに分割し(SpiltSizeのデフォルトはblockSize 128M)、各スライスはMapTaskに送信されます(YARNが送信を担当します)。
- MapTaskは、タスクを実行し、map関数に従って<K、V>ペアを生成し、結果をリングバッファーに出力してから、パーティション分割、並べ替え、およびオーバーフローを実行します。
- シャッフル、つまり、マップ結果を複数のパーティションに分割し、それらを複数のリデュースタスクに割り当てます。このプロセスはシャッフルと呼ばれます。
- マップ後にパーティションのデータを縮小してコピーし(フェッチプロセス、コピーを実行するためのデフォルトの5スレッド)、すべてが完了した後にマージ操作を実行します。
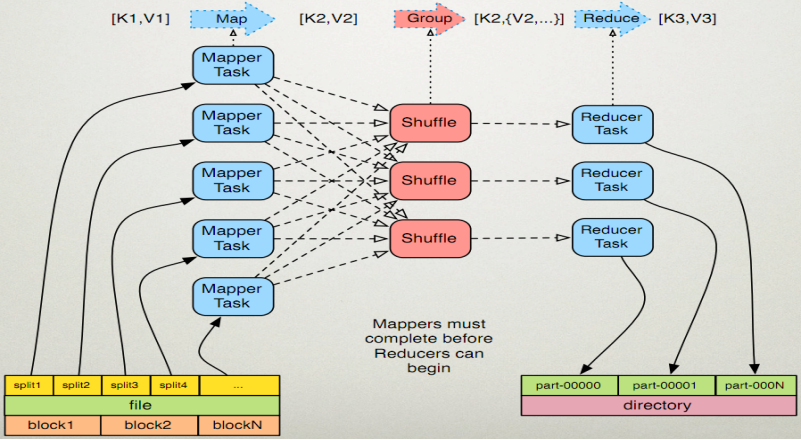
分散機能は、ジョブに複数のMapperTasks、Shuffles、およびReduceが含まれることです。次の図は、分散並列プロセスの良い例です。
3.mapreduceプログラムを作成します。
MRプログラミングフレームワーク:
1)マッパーステージ
(1)ユーザー定義のマッパーは独自の親クラスを継承する必要があります
(2)マッパーの入力データはKVペアの形式です(KVのタイプはカスタマイズ可能です)
(3)Mapperのビジネスロジックはmap()メソッドで記述されます
(4)マッパーの出力データはKVペアの形式です(KVのタイプはカスタマイズ可能です)
(5)map()メソッド(maptaskプロセス)は、<K、V>ごとに1回呼び出されます。
2)レデューサーステージ
(1)ユーザー定義のReducerは、独自の親クラスを継承する必要があります
(2)Reducerの入力データ型は、Mapperの出力データ型に対応します。これもKVです。
(3)Reducerのビジネスロジックはreduce()メソッドで記述されます
(4)Reducetaskプロセスは、同じkの<k、v>グループのグループごとにreduce()メソッドを1回呼び出します。
3)ドライバーステージ
プログラム全体でDrvierが提出する必要があり、提出はさまざまな必要な情報を説明するジョブオブジェクトです。
4、MapReduceの古典的な単語頻度統計の場合
次に、WordCountケースを実装する最初のMapReduceプログラムを作成します。
環境の準備:
IDEAは新しいMavenプロジェクトを作成し、対応するバージョンのHadoopのコア依存関係を導入し、構成ファイルをリソース管理に組み込みます。
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
1.マッププログラムを作成します
public class WordCountMap extends Mapper<LongWritable, Text,Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
//重写map方法,实现业务逻辑
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1,获取一行
String line = value.toString();
//2,切割
String[] words = line.split(" ");
for(String word:words){
k.set(word);
context.write(k,v);
}
}
}
2.リデュースプログラムを作成します
public class WordCountReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//子类构造方法中会有一个默认隐含的super()方法,用于调用父类构造
//super.reduce(key, values, context);
int sum = 0;
for(IntWritable count:values){
sum += count.get();
}
context.write(key,new IntWritable(sum));
}
}
3.ドライバークラスを作成します
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1,获取job
Configuration configuration = new Configuration();
Job job = Job.getInstance();
//2,设置jar加载路径
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
// 4 设置 map 输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置 Reduce 输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
次に、ツールを使用してメインファイルをjarパッケージにします。
project structre->結合で、Artifactsを選択From moudles from dependenciesし、独自のmainクラス、jarパッケージ出力ディレクトリを設定します。次に、ツールバーBuildから、を選択build Artifacts->buildしてjarパッケージを作成します。最後に、FTPツールを使用してjarパッケージをクラスター環境に送信し、次のコマンドを使用して実行します。
hadoop jar jar包名 main类的全类名 输入目录 输出目录

5.開発スキル
では、mapreduceプログラムか?
実際の本番開発では、プログラムをjarパッケージ化あります。
まず、mainクラスconfiguration、入力パラメータと出力パラメータを事前に追加する必要があります。
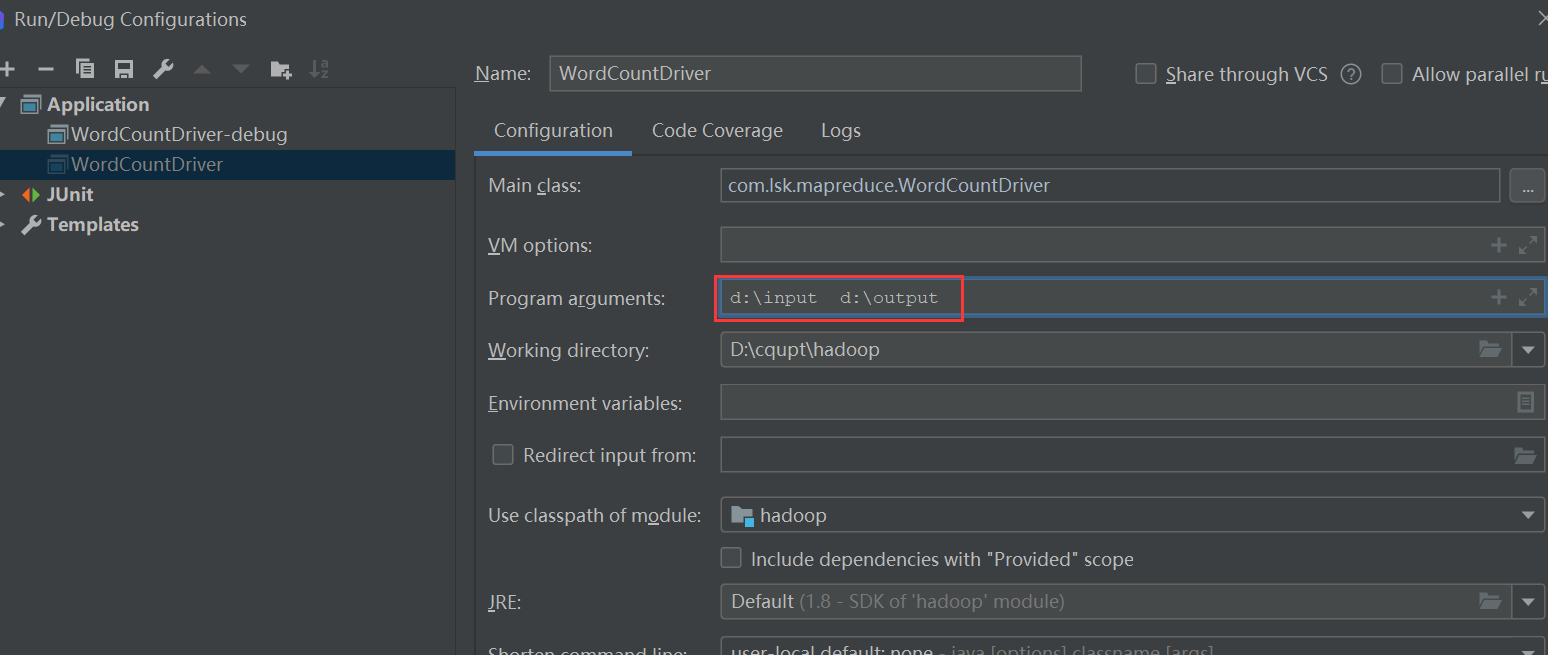
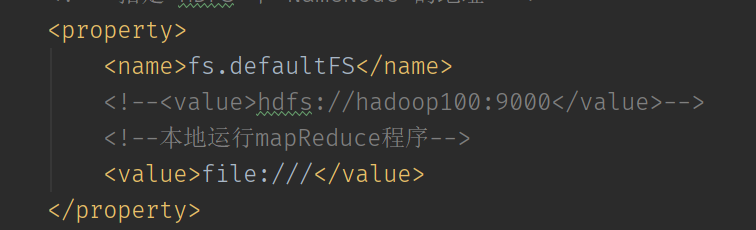
次に、ファイルシステムをローカル操作モードに変更するように設定します。
参照リンク