コンテストの紹介
コンテストのタイトル:
テキスト文字ベースのキャプチャ認識コンテスト
質問ユニット:
興業銀行
コンテストの背景:
費用対効果の高いセキュリティ検証方法として、検証コードが多くの場面で広く使用されており、ロボットによるIDスプーフィングを効果的に防止しています。その中でも、テキスト文字に基づく静的検証コードが最も一般的です。使用が深まるにつれ、ノイズポイント、ノイズライン、オーバーラップ、変形、その他の干渉方法が無限の流れで出現し、セキュリティレベルは常に向上しています。企業のデジタルトランスフォーメーションの鍵として、RPAテクノロジは、その非侵入型の展開のために企業に支持されており、検証コードの認識率が低いため、RPAテクノロジの適用が制限されることがよくあります。複数の干渉を同時にフィルタリングできるCAPTCHAモデルには、関連する自動化テクノロジーの拡張と使用に一定の商業的価値があります。
コンテストのタスク:
このコンテストでは、文字情報がマークされた文字検証コード画像データの例をトレーニングサンプルとして使用します。参加者は、提供されたサンプルに基づいてモデルを構築し、テストセットで文字検証コード画像を識別し、有効な文字を抽出する必要があります。情報。トレーニングデータセットは、提供されたデータに限定されず、公開されているデータセットに追加できます。
データの紹介
このコンテストでは、15,000のトレーニングデータセットに注釈情報が提供されます。各トレーニングデータは、4桁のテキスト文字を含むキャプチャ画像であり、現在の画像のテキスト文字がマークされています。テストデータセットには、25,000のキャプチャ画像が含まれています。



苦情を言う
このゲームについて不満を言う人はたくさんいます!以下の点をまとめると:
1. AリストとBリストのデータ分布には大きなギャップがあり、多くの前列が後列に変化します。それは無数の専門家をお辞儀させました。
2.ゲームはほとんど意味がありません。これはゲームのためのゲームです。
解決
コンテストグループの大物のチャットを見て、誰もが使用する最高のスコアリング方法は、50倍の交差検証、CutOut、CutMix、MixUp、生成されたデータなどであることがわかりました。モデルは通常、EfficientNetV1およびV2を使用します。
また、上のサブセクションで上記のメソッドのいくつかを使用しました。私の解決策は、EfficientNetV1-B7 + MixUp+CutOutです。その後、CutMixが追加され、効果をテストする時間がありませんでした。検証コードの認識は、マルチラベル分類に従って行われます。
ソリューションリファレンスgithub:https://github.com/zyf-xtu/captcha_ocr
トレーニングスコア:0.9854、評価が終了したため、Aリストのスコアを知る方法はありません。
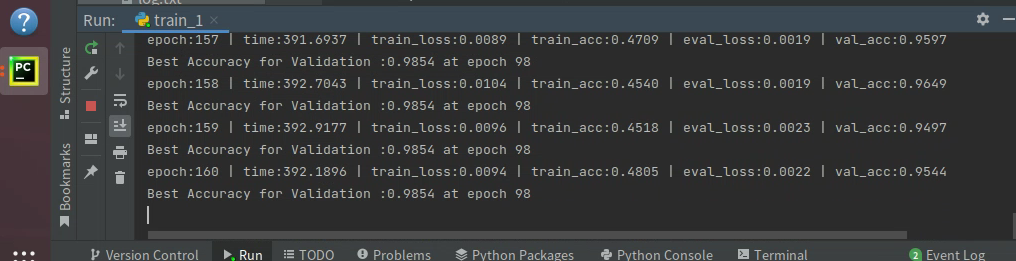
以下は私の計画の詳細な説明です。
データ
データセクションへの変更は、captcha_dataset.pyファイルにあります。geitemメソッドを変更しました:
def __getitem__(self, index):
img_path, target = self.samples[index]
# #print('target', target)
# #print('random_t', random_t)
img = img_loader(img_path)
if np.random.random() > 0.5 and self.train_type==True:
img_arr = np.array(img)
index_arr=np.random.permutation(img_arr.shape[2])
img_arr=img_arr[:,:,index_arr]
img = Image.fromarray(img_arr.astype('uint8')).convert('RGB')
if np.random.random() > 0.5 and self.train_type==True:
img_random_path, random_t = self.samples[np.random.randint(0, len(self.samples))]
img_random = img_loader(img_random_path)
img_arr = np.array(img)
img_random_arr = np.array(img_random)
img_arr[:, 50:100, :] = img_random_arr[:, 50:100, :]
img = Image.fromarray(img_arr.astype('uint8')).convert('RGB')
target = target[:124] + random_t[124:]
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, torch.Tensor(target)
この方法では、2つのデータ拡張機能を追加しました。1つはチャネルにランダム、つまりRGBのランダムです。もう1つはCutMixで、画像の前半と別の画像の後半をつなぎ合わせます。次に、Labelは対応するスプライシングも行います。
トレーニング
トレーニングは最も重要な部分です。これらの変更はtrain_1.pyにあります。変更した場所をリストします。
image_sizeh,image_sizew=240,600
画像のサイズ変更サイズを240×600に設定し、6倍に拡大します。
データ拡張私はCutOutを増やしました:
Cutoutはtorchtoolboxを使用します。torchtoolboxがない場合は、インストールする必要があります。
pip install torchtoolbox
インストール後にインポート:
from torchtoolbox.transform import Cutout
次に、それを変換で呼び出します。
# transform = [, transforms.GaussianBlur(21, 10)]
train_transform = transforms.Compose([
Cutout(),
transforms.Resize((image_sizeh, image_sizew)), # 图像放缩
transforms.RandomRotation((-5, 5)), # 随机旋转
# transforms.RandomVerticalFlip(p=0.2), # 随机旋转
transforms.ToTensor(), # 转化成张量
transforms.Normalize(
mean=train_mean,
std=train_std
)
])
データの読み込み部分を変更しました:
# 加载训练数据集,转化成标准格式
train_dataset = CaptchaData(train_paths,train_type=True, transform=train_transform)
# 加载验证集,转化成标准格式
val_dataset = CaptchaData(val_paths,train_type=False, transform=val_transform)
トレーニングであるかどうかを判断するためにtrain_typeフィールドが追加されます。トレーニングである場合はデータ拡張が実行され、そうでない場合はデータ拡張は実行されません。
# 如果是多个gpu,数据并行训练
device_ids = [0, 1]
model = torch.nn.DataParallel(model, device_ids=device_ids)
マルチGPUの並列処理を増やすために、私のローカル環境には2つの3090があるため、device_idsは0と1に設定されています。
cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-6)
レート調整の学習には、コサインアニーリングを使用します。学習率の初期値は1e-3で、最小設定は1e-6です。
inputs, labels_a, labels_b, lam = mixup_data(inputs, labels, 0.2)
# 预测输出
outputs = model(inputs)
# 计算MixUp loss
loss = mixup_criterion(loss_func, outputs, labels_a, labels_b, lam)
ミックスアップを追加しても、ミックスアップスコアはまだ比較的明白です。
このコンテストの別の大物もオープンソースのgithubアドレスを作成しました:https://github.com/xiaoxiaokuaile/2022DCIC_OCR
要約する
この大会は完璧ではありませんが、大会で多くのことを学びました。これが一番大事なことだと思います。
完全なコード:https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwwwww/85050647