クローラーで遊ぶことが多い子供靴はCookieの重要性を知っています。これまでのところ、ほとんどのWebサイトはログインステータスを識別するためにCookieを使用しており、ログインステータスを記録するためにjwtを使用するようにアップグレードしたWebサイトはごくわずかです。
クッキーを抽出する機能は自明ですが、クッキーを抽出するためのハイエンドの操作は何ですか?見てください:
記事ディレクトリ
GoogleChromeCookieの純粋な手動抽出
これは、クローラーで遊んだことがある子供靴の解決策になるはずであり、クローラーをまったく知らない子供靴の最も難しい解決策かもしれません。
この方法では、最初にF12で開発者ツールを開き、次にCookieを抽出するWebサイトにアクセスしてから、ネットワークでアクセスしたばかりの要求を選択します。具体的な手順は次のとおりです。
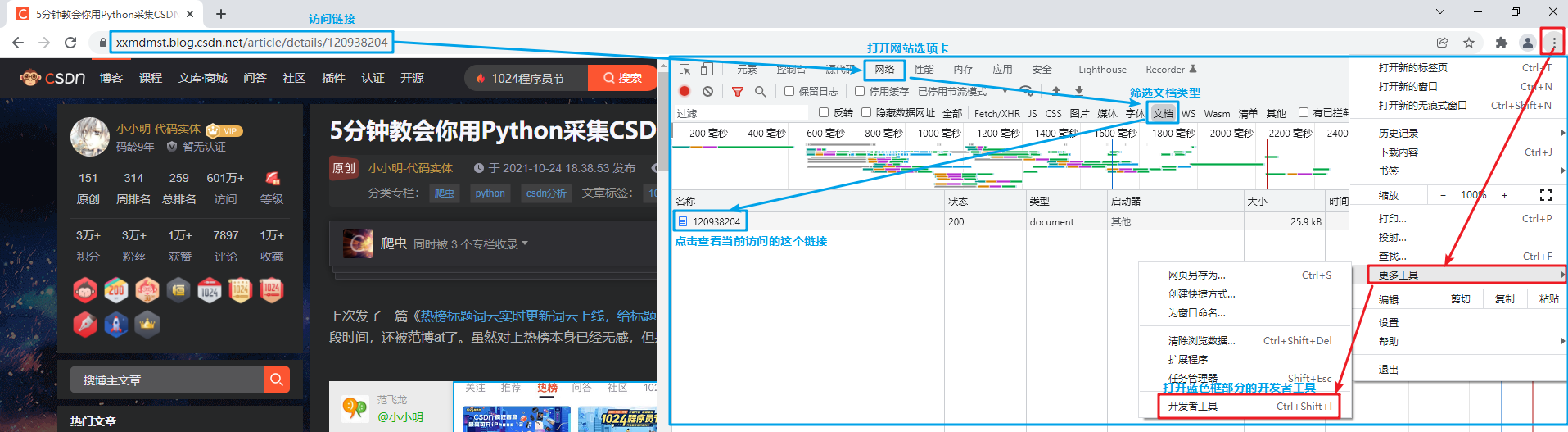
次に、リクエストヘッダーでCookieアイテムを見つけて、対応する値をコピーします。
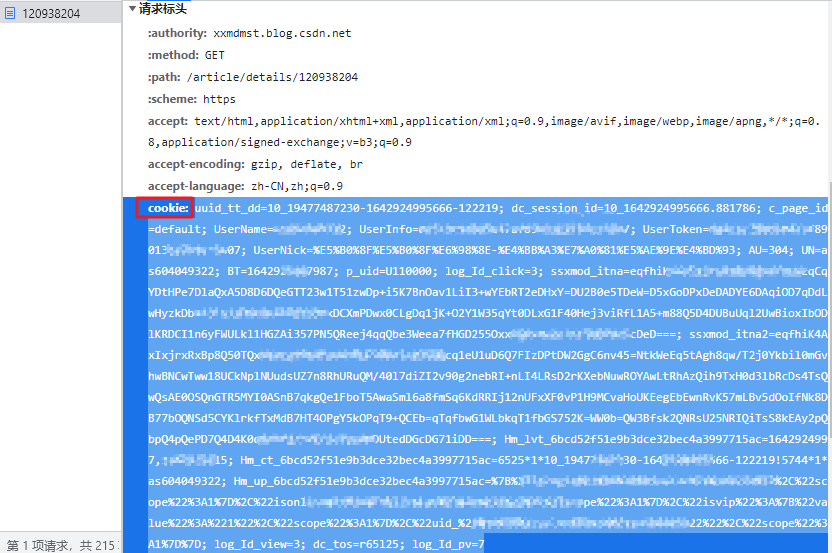
これは、クロールを学んだ子供靴の操作である必要があります。コードを使用して自動化の効果を高める方法はありますか?
私の解決策は、curlリクエストをコピーした直後にコードを使用して抽出することです。操作は次のとおりです。
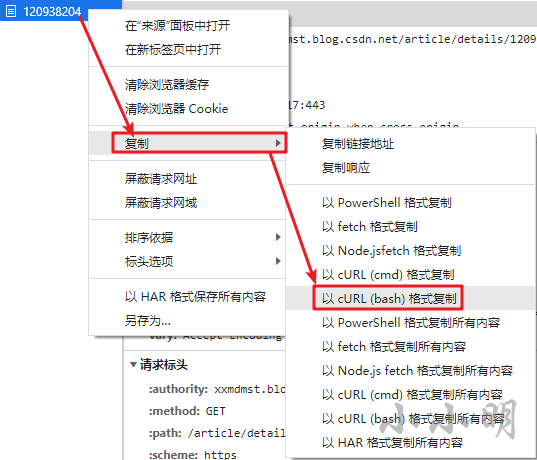
リクエストをcurlコマンドの形式でクリップボードにコピーした後、コードを介してCookieを直接抽出できます。コードは次のとおりです。
import re
import pyperclip
def extractCookieByCurlCmd(curl_cmd):
cookie_obj = re.search("-H \$?'cookie: ([^']+)'", curl_cmd, re.I)
if cookie_obj:
return cookie_obj.group(1)
cookie = extractCookieByCurlCmd(pyperclip.paste())
print(cookie)
比較したところ、印刷されたCookieは直接コピーされたCookieとまったく同じであることがわかりました。
セレンは手動でログインしてCookieを取得します
例として、ステーションBのログインCookieを保存します。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
import time
import json
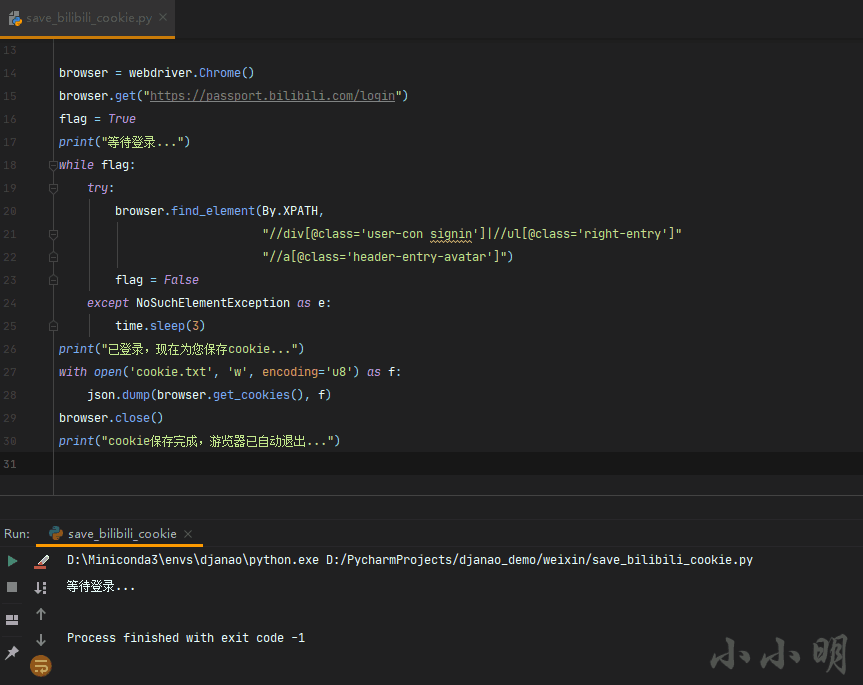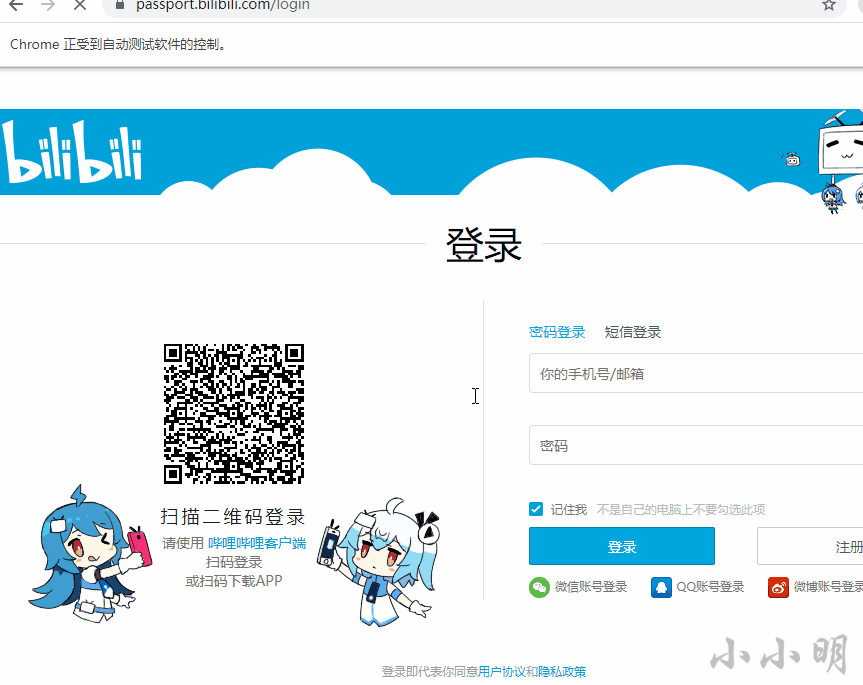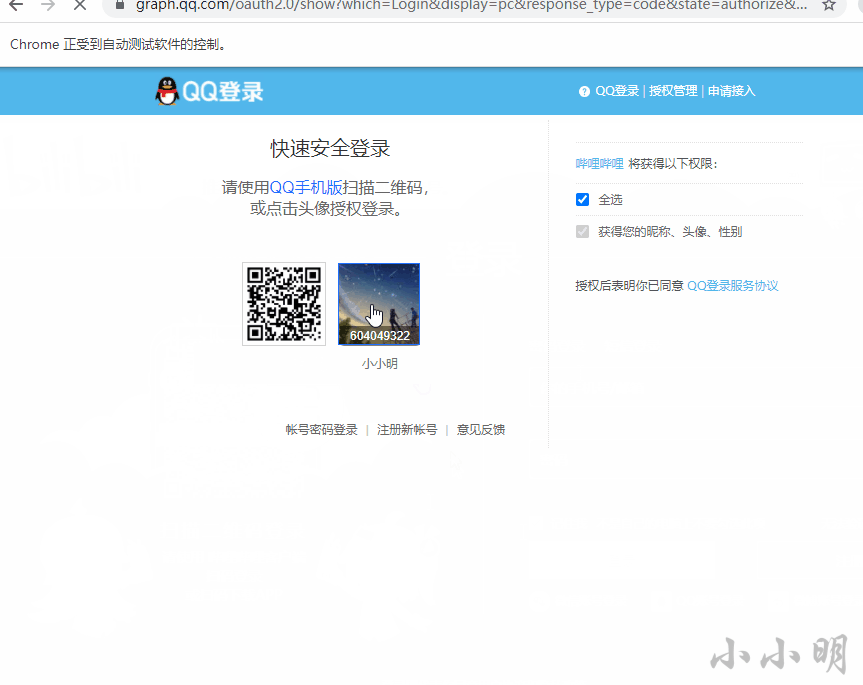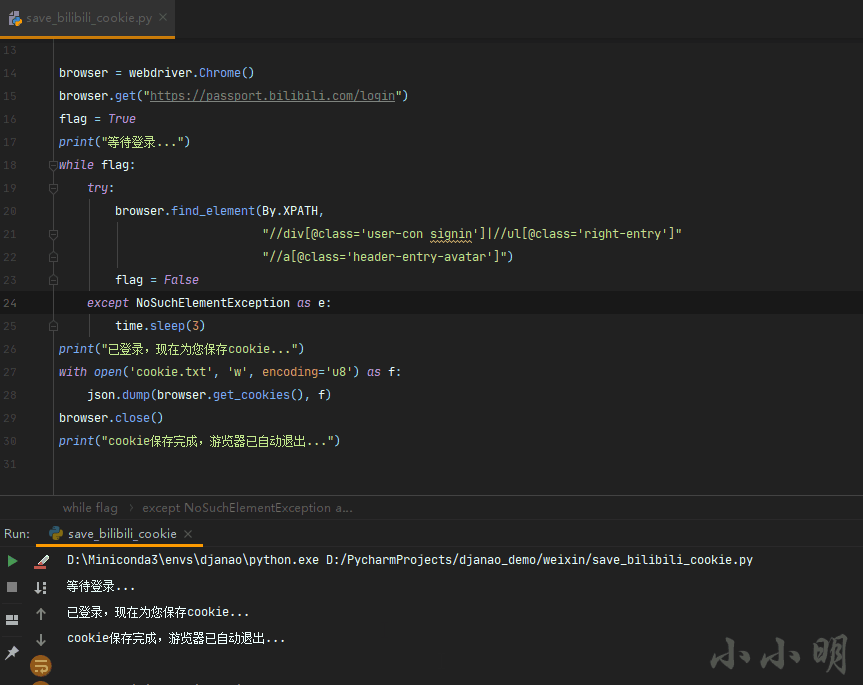
browser = webdriver.Chrome()
browser.get("https://passport.bilibili.com/login")
flag = True
print("等待登录...")
while flag:
try:
browser.find_element(By.XPATH,
"//div[@class='user-con signin']|//ul[@class='right-entry']"
"//a[@class='header-entry-avatar']")
flag = False
except NoSuchElementException as e:
time.sleep(3)
print("已登录,现在为您保存cookie...")
with open('cookie.txt', 'w', encoding='u8') as f:
json.dump(browser.get_cookies(), f)
browser.close()
print("cookie保存完成,游览器已自动退出...")
上記のコードを実行すると、seleniumはGoogleブラウザを制御してBステーションのログインページを開き、ユーザーがBステーションに手動でログインするのを待ち、ログイン後にCookieが自動的に保存されます。
では、後続のセレンプログラムが再度ログインせずに起動したときにCookieを直接使用するにはどうすればよいでしょうか。デモは次のとおりです。
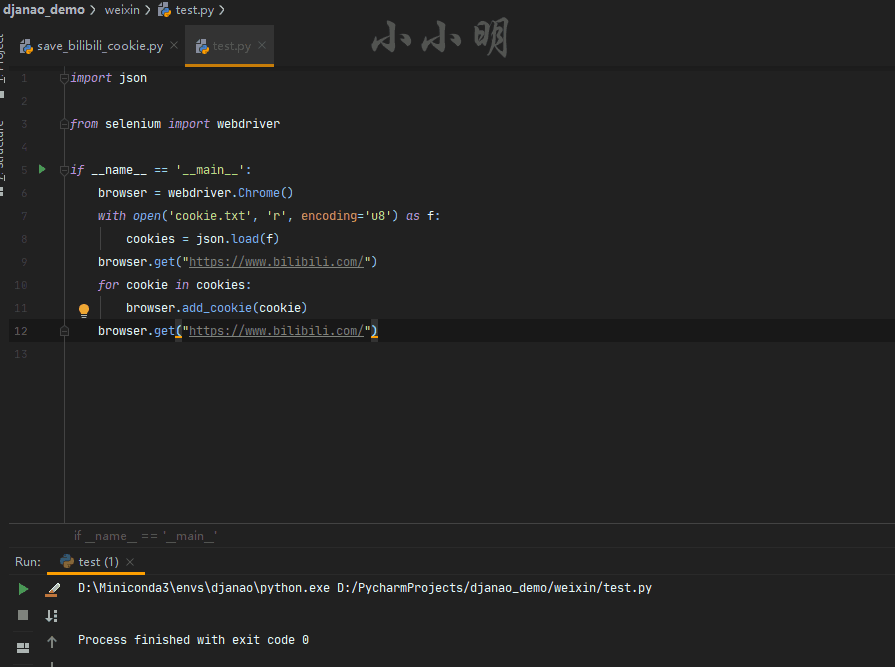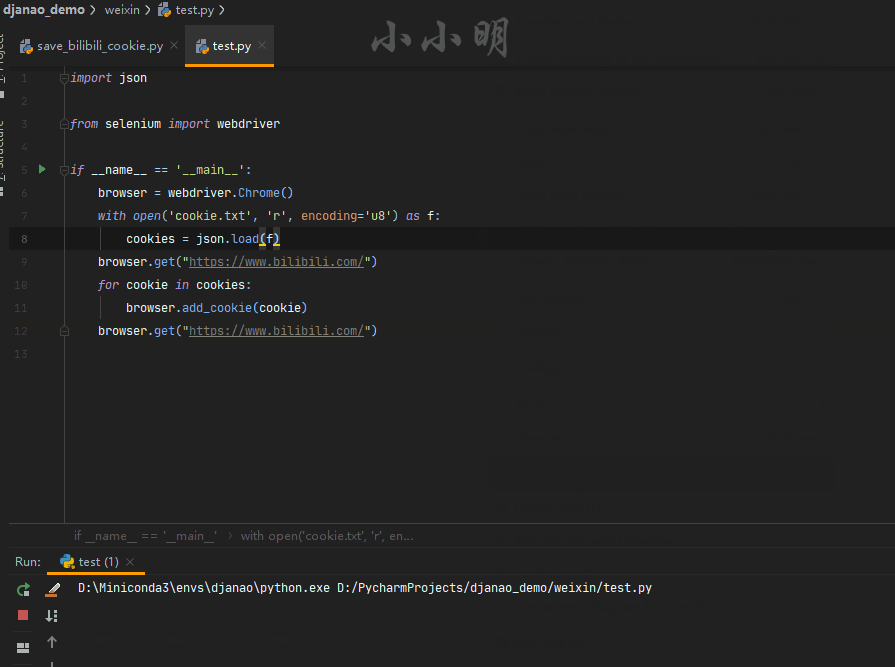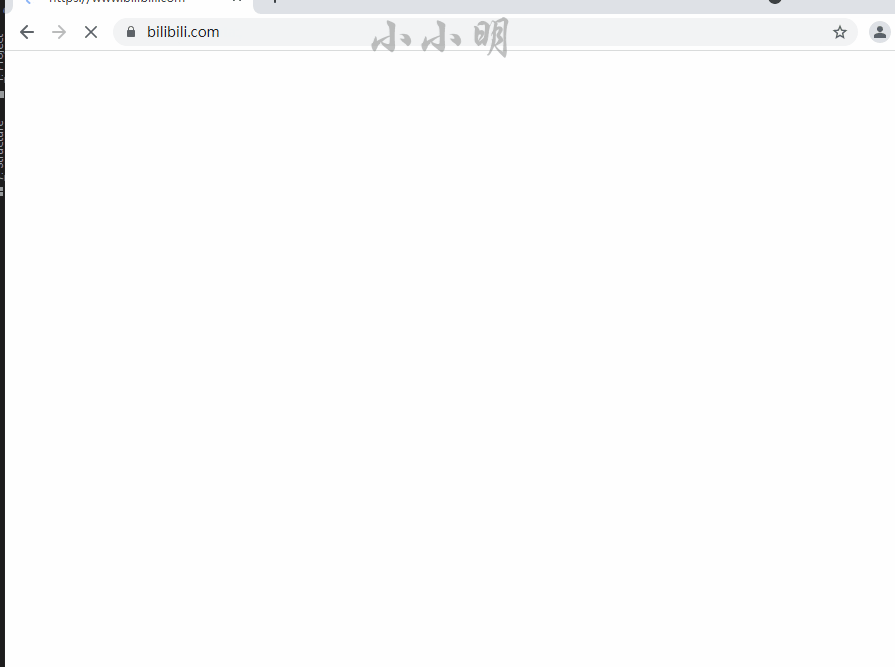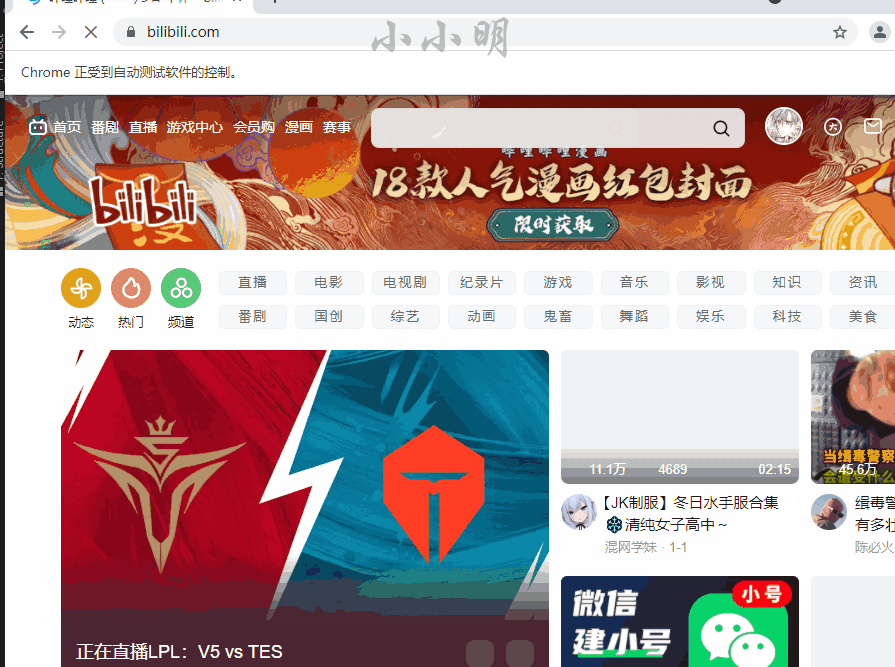
import json
from selenium import webdriver
browser = webdriver.Chrome()
with open('cookie.txt', 'r', encoding='u8') as f:
cookies = json.load(f)
browser.get("https://www.bilibili.com/")
for cookie in cookies:
browser.add_cookie(cookie)
browser.get("https://www.bilibili.com/")
このプロセスでは、最初にCookieをロードするWebサイトにアクセスし、次にCookieをすばやく追加してから、Webサイトに再度アクセスしてCookieをロードして有効にします。
セレンヘッドレスモードは非ログインCookieを取得します
たとえば、DouyinのようなWebサイトで動画をダウンロードする場合、最初のCookieが必要ですが、このCookieによって生成されるアルゴリズムはより複雑であり、純粋なリクエストをシミュレートすることは困難です。現時点では、次を使用できます。セレニウムを使用してWebページをロードし、Cookieを取得します。jsの分析にかかる時間を節約します。手動で操作する必要がないので、ヘッドレスモードを使用することをお勧めします。
以下は、ヘッドレスモードでDouyinWebサイトからCookieを取得する方法を示しています。
from selenium import webdriver
import time
def selenium_get_cookies(url='https://www.douyin.com'):
"""无头模式提取目标链接对应的cookie,代码作者:小小明-代码实体"""
start_time = time.time()
option = webdriver.ChromeOptions()
option.add_argument("--headless")
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
option.add_argument(
'user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36')
option.add_argument("--disable-blink-features=AutomationControlled")
print("打开无头游览器...")
browser = webdriver.Chrome(options=option)
print(f"访问{
url} ...")
browser.get(url)
cookie_list = browser.get_cookies()
# 关闭浏览器
browser.close()
cost_time = time.time() - start_time
print(f"无头游览器获取cookie耗时:{
cost_time:0.2f} 秒")
return {
row["name"]: row["value"] for row in cookie_list}
print(selenium_get_cookies("https://www.douyin.com"))
印刷結果は次のとおりです。
打开无头游览器...
访问https://www.douyin.com ...
无头游览器获取cookie耗时:3.28 秒
{'': 'douyin.com', 'ttwid': '1%7CZn_LJdPjHKdCy4jtBoYWL_yT3NMn7OZVTBStEzoLoQg%7C1642932056%7C80dbf668fd283c71f9aee1a277cb35f597a8453a3159805c92dfee338e70b640', 'AB_LOGIN_GUIDE_TIMESTAMP': '1642932057106', 'MONITOR_WEB_ID': '651d9eca-f155-494b-a945-b8758ae948fb', 'ttcid': 'ea2b5aed3bb349219f7120c53dc844a033', 'home_can_add_dy_2_desktop': '0', '_tea_utm_cache_6383': 'undefined', '__ac_signature': '_02B4Z6wo00f01kI39JwAAIDBnlvrNDKInu5CB.AAAPFv24', 'MONITOR_DEVICE_ID': '25d4799c-1d29-40e9-ab2b-3cc056b09a02', '__ac_nonce': '061ed27580066860ebc87'}
ローカルのグーグルクロームでクッキーを取得する
セレンを介してGoogleブラウザを直接制御すると、元のGoogleブラウザのCookieが読み込まれないことがわかっています。Google ChromeがログインしたCookieを直接取得する方法はありますか?
実際、デバッグリモートデバッグモードを使用してローカルのGoogleブラウザーを実行し、セレン制御を使用して以前にログインしたCookieを抽出する限り、これは非常に簡単です。
import os
import winreg
from selenium import webdriver
import time
def get_local_ChromeCookies(url, chrome_path=None):
"""提取本地谷歌游览器目标链接对应的cookie,代码作者:小小明-代码实体"""
if chrome_path is None:
key = winreg.OpenKey(winreg.HKEY_CLASSES_ROOT, r"ChromeHTML\Application")
path = winreg.QueryValueEx(key, "ApplicationIcon")[0]
chrome_path = path[:path.rfind(",")]
start_time = time.time()
command = f'"{
chrome_path}" --remote-debugging-port=9222'
# print(command)
os.popen(command)
option = webdriver.ChromeOptions()
option.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
browser = webdriver.Chrome(options=option)
print(f"访问{
url}...")
browser.get(url)
cookie_list = browser.get_cookies()
# 关闭浏览器
browser.close()
cost_time = time.time() - start_time
print(f"获取谷歌游览器cookie耗时:{
cost_time:0.2f} 秒")
return {
row["name"]: row["value"] for row in cookie_list}
print(get_local_ChromeCookies("https://www.douyin.com"))
上記のコードには、以前にGoogleChromeでアクセスしたWebサイトのCookieを直接取得する機能があります。Douyinの結果は次のとおりです。
DevTools listening on ws://127.0.0.1:9222/devtools/browser/9a9c19da-21fc-42ba-946d-ff60a91aa9d2
访问https://www.douyin.com...
获取谷歌游览器cookie耗时:4.62 秒
{'THEME_STAY_TIME': '10718', 'home_can_add_dy_2_desktop': '0', '_tea_utm_cache_1300': 'undefined', 'passport_csrf_token': 'c6bda362fba48845a2fe6e79f4d35bc8', 'passport_csrf_token_default': 'c6bda362fba48845a2fe6e79f4d35bc8', 'MONITOR_WEB_ID': 'd6e51b15-5276-41f3-97f5-e14d51242496', 'MONITOR_DEVICE_ID': 'd465b931-3a0e-45ba-ac19-263dd31a76ee', '': 'douyin.com', 'ttwid': '1%7CsXCoN0TQtHpKYiRoZnAKyqNJhOfkdJjNEJIdPPAibJw%7C1642915541%7C8a3308d87c6d2a38632bbfe4dfc0baae75162cedf6d63ace9a9e2ae4a13182d2', '__ac_signature': '_02B4Z6wo00f01I50-sQAAIDADnYAhr3RZZCOUP5AAEJ0f7', 'msToken': 'mUYtlAj8qr_9fuTIekLmAThy9N_ltbh0NJo05ns14o3X5As496_O5n7XT4-I81npZuGrIxt0V3JadDZlznmwgzwxqT6GZdIOBozEPC-WAZawQR-teML5984=', '__ac_nonce': '061ed25850009be132678', '_tea_utm_cache_6383': 'undefined', 'AB_LOGIN_GUIDE_TIMESTAMP': '1642915542503', 'ttcid': '3087b27658f74de9a4dae240e7b3930726'}
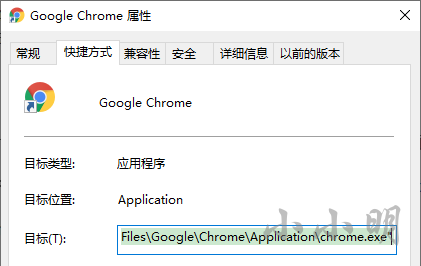
上記のコードは、レジストリエントリを読み取ることにより、GoogleChromeのパスを取得します。

個人は、Google Chromeの場所が他のコンピューターのレジストリからも取得できることを確認できないため、アクティブな着信パスのパラメーターが提供されます。
--remote-debugging-port =9222をGoogleChromeの起動パラメーターに追加してリモートデバッグモードを有効にすると、seleniumはdebuggerAddressパラメーターを介してリモートデバッグモードを有効にして既存のGoogleブラウザーに接続できます。
そのため、以前にGoogleChromeにログインしたことのあるWebサイトのCookieを正常に取得できます。
ただし、Google Chromeを実行するための毎日のショートカットに
--user-data-dirパラメータがある場合、上記のコードでもこのパラメータを追加する必要がありますが、ホストマシン上のGoogleChromeには次のパラメータは追加されません。
GoogleChromeのCookieデータを保存しているファイルを解析して抽出します
最後に、Cookieファイルを直接復号化するという究極のトリックを紹介します。97より前のバージョンのGoogleChromeでは、Cookie保存ファイルはに保存されていました%LOCALAPPDATA%\Google\Chrome\User Data\Default\Cookies。バージョン97以降は、に移動されました%LOCALAPPDATA%\Google\Chrome\User Data\Default\Network\Cookies。
ただし、97を超える将来のバージョンで、保存場所と暗号化方法が引き続き変更されるかどうかは不明です。これまでのところ、重要なデータは常に%LOCALAPPDATA%\Google\Chrome\User Data\Local Stateファイルに保存されてきました。(バージョン80より前では、win32crypt.CryptUnprotectData(encrypted_value_bytes、None、None、None、0)[1]を使用して直接復号化します。キーは必要ありません)
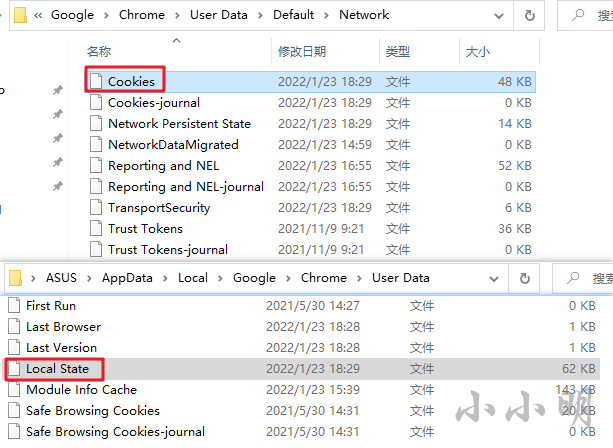
実際、CookiesファイルはNavicatPremium15で直接表示できるSQLliteデータベースです。
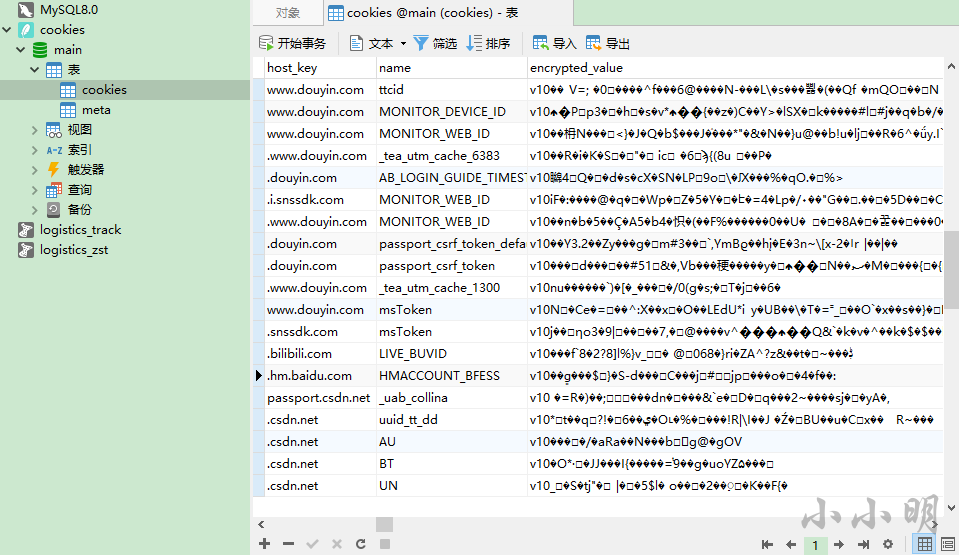
ただし、値は暗号化されています。バージョン80以降の暗号化アルゴリズムを参照してください:https ://github.com/chromium/chromium/blob/master/components/os_crypt/os_crypt_win.cc
キーストレージの復号化に関係するファイルLocalStateはJSONファイルです。
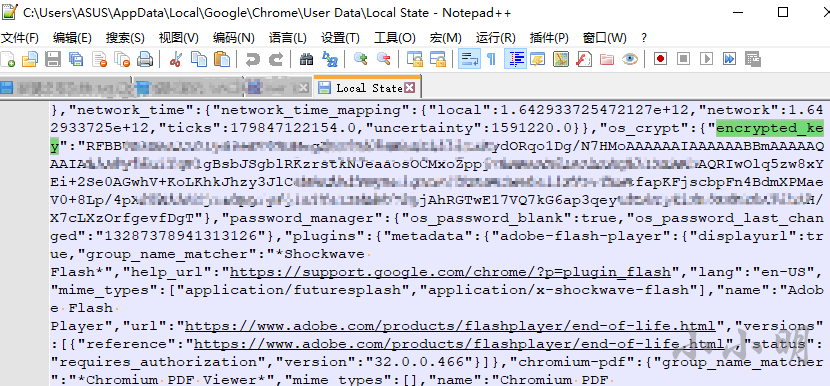
完全な抽出コードは次のとおりです。
"""
小小明的代码
CSDN主页:https://blog.csdn.net/as604049322
"""
__author__ = '小小明'
__time__ = '2022/1/23'
import base64
import json
import os
import sqlite3
import win32crypt
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
def load_local_key(localStateFilePath):
"读取chrome保存在json文件中的key再进行base64解码和DPAPI解密得到真实的AESGCM key"
with open(localStateFilePath, encoding='u8') as f:
encrypted_key = json.load(f)['os_crypt']['encrypted_key']
encrypted_key_with_header = base64.b64decode(encrypted_key)
encrypted_key = encrypted_key_with_header[5:]
key = win32crypt.CryptUnprotectData(encrypted_key, None, None, None, 0)[1]
return key
def decrypt_value(key, data):
"AESGCM解密"
nonce, cipherbytes = data[3:15], data[15:]
aesgcm = AESGCM(key)
plaintext = aesgcm.decrypt(nonce, cipherbytes, None).decode('u8')
return plaintext
def fetch_host_cookie(host):
"获取指定域名下的所有cookie"
userDataDir = os.environ['LOCALAPPDATA'] + r'\Google\Chrome\User Data'
localStateFilePath = userDataDir + r'\Local State'
cookiepath = userDataDir + r'\Default\Cookies'
# 97版本已经将Cookies移动到Network目录下
if not os.path.exists(cookiepath) or os.stat(cookiepath).st_size == 0:
cookiepath = userDataDir + r'\Default\Network\Cookies'
# print(cookiepath)
sql = f"select name,encrypted_value from cookies where host_key like '%.{
host}'"
cookies = {
}
key = load_local_key(localStateFilePath)
with sqlite3.connect(cookiepath) as conn:
cu = conn.cursor()
for name, encrypted_value in cu.execute(sql).fetchall():
cookies[name] = decrypt_value(key, encrypted_value)
return cookies
if __name__ == '__main__':
print(fetch_host_cookie("douyin.com"))
結果:
{'ttcid': '3087b27658f74de9a4dae240e7b3930726', 'MONITOR_DEVICE_ID': 'd465b931-3a0e-45ba-ac19-263dd31a76ee', 'MONITOR_WEB_ID': '70892127-f756-4455-bb5e-f8b1bf6b71d0', '_tea_utm_cache_6383': 'undefined', 'AB_LOGIN_GUIDE_TIMESTAMP': '1642915542503', 'passport_csrf_token_default': 'c6bda362fba48845a2fe6e79f4d35bc8', 'passport_csrf_token': 'c6bda362fba48845a2fe6e79f4d35bc8', '_tea_utm_cache_1300': 'undefined', 'msToken': 'e2XPeN9Oe2rvoAwQrIKLvpGYQTF8ymR4MFv6N8dXHhu4To2NlR0uzx-XPqxCWWLlO5Mqr2-3hwSIGO_o__heO0Rv6nxYXaOt6yx2eaBS7vmttb4wQSQcYBo=', 'THEME_STAY_TIME': '13218', '__ac_nonce': '061ed2dee006ff56640fa', '__ac_signature': '_02B4Z6wo00f01rasq3AAAIDCNq5RMzqU2Ya2iK.AAMxSb2', 'home_can_add_dy_2_desktop': '1', 'ttwid': '1%7CsXCoN0TQtHpKYiRoZnAKyqNJhOfkdJjNEJIdPPAibJw%7C1642915541%7C8a3308d87c6d2a38632bbfe4dfc0baae75162cedf6d63ace9a9e2ae4a13182d2'}
Cookieがローカルファイルから完全に抽出されていることがわかります。