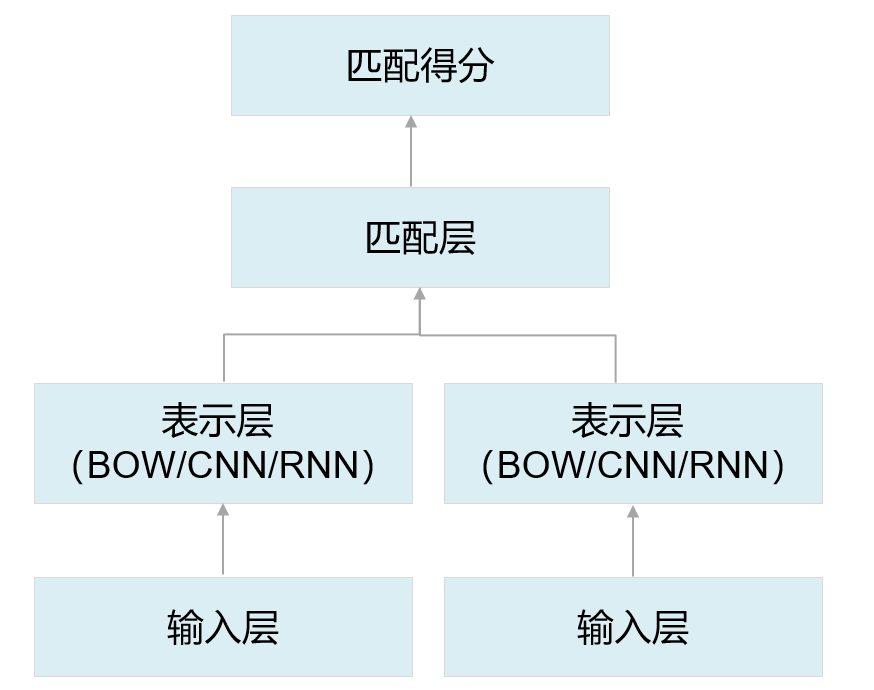
NLP自然言語処理の分野では、異なるテキスト間の類似性を計算し、異なるテキストをエンコードしてから、それらを埋め込み固定長表現ベクトルに処理し、LSTMを使用して出力テキスト表現を行い、複数の多入力を定義する必要がある場合があります。計算用のソースデータ。
文1:みじん切りのコショウで魚の頭を食べるのは好きではありませんが、魚の頭を食べるのは好きです
文2:私はジャガイモは好きですが、サツマイモは好きではありません
LSTMネットワークは、各文をベクトル表現に抽象化するためにも使用されます.2つのベクトル間の類似度を計算することにより、テキスト類似度計算タスクをすばやく完了することができます。実際のシナリオでは、通常、LSTMネットワークの最後のステップの隠された結果を使用して、文をベクトルに抽象化し、ベクトル内積または余弦の類似性によって2つの文の類似性を測定します。
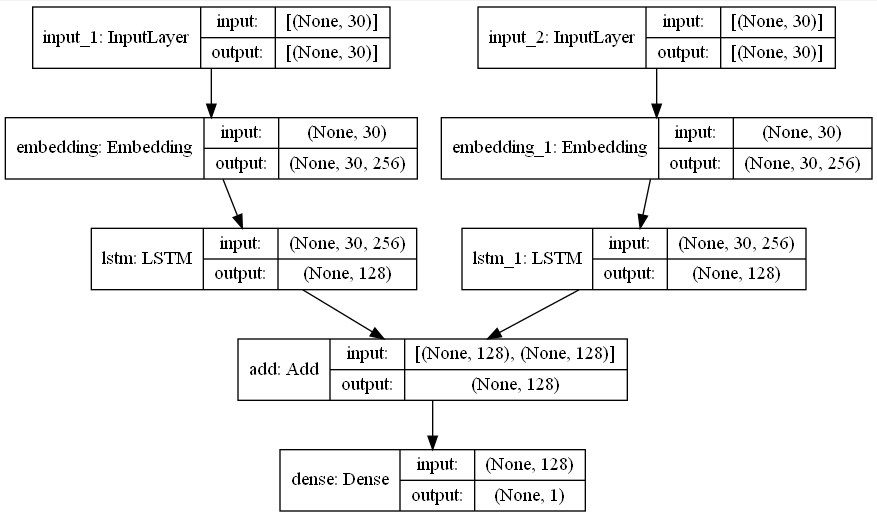
コードは次のように表示されます。
"""
* Created with PyCharm
* 作者: 阿光
* 日期: 2022/1/14
* 时间: 18:55
* 描述:
"""
import tensorflow as tf
from keras import Model
from tensorflow.keras.layers import *
def get_model():
x_input = Input(shape=30)
y_input = Input(shape=30)
x_embedding = Embedding(input_dim=252173,
output_dim=256)(x_input)
y_embedding = Embedding(input_dim=252173,
output_dim=256)(y_input)
x_lstm = LSTM(128)(x_embedding)
y_lstm = LSTM(128)(y_embedding)
def cosine_distance(x1, x2):
x1_norm = tf.sqrt(tf.reduce_sum(tf.square(x1), axis=1))
x2_norm = tf.sqrt(tf.reduce_sum(tf.square(x2), axis=1))
x1_x2 = tf.reduce_sum(tf.multiply(x1, x2), axis=1)
cosin = x1_x2 / (x1_norm * x2_norm)
return tf.reshape(cosin, shape=(-1, 1))
score = cosine_distance(x_lstm, y_lstm)
output = Dense(1, activation='sigmoid')(score)
model = Model([x_input, y_input], output)
return model
model = get_model()
model.summary()