1 正则表达式概念
正则表达式(Regular Eexpressions)应用范围
- 字符串匹配操作和替换操作
- 例子:Linux中的vi, more, grep, yacc, lex, awk, sed
- 其他:VS, word等
注意事项
- 正则表达式规则与文件名通配符规则不同。正则表达式规则用于文本处理的场合;文件名匹配规则用于文件处理的场合。
- 不同软件对正则表达式的定义会有差异。
1.1 元字符和集合
6个元字符
. * [ \ ^ $
其他字符与其自身匹配(比如正则表达式a与字符串a匹配等)
转义字符
- 用反斜线可以取消特殊字符的特殊含义。
- 如:正则表达式 end\. 只与字符串 end. 匹配。正则表达式\*与字符串*匹配,与字符串\*不匹配。
- 转义字符串后除以上6个元字符之外,不会出现其他字符。
1.2 单字符正则表达式
转义字符(\)
圆点(.) # 匹配任意单字符
定义集合
- 在一对 [ ] 之间的字符为集合的内容。如:单字符正则表达式[abc]与a, b, c匹配
- . * \ 在方括号内时,代表它们自己。如:[\*.] 可以匹配三个单字符
减号 - 定义区间
- 用减号 - 定义一个区间。如:[a-z] [a-zA-Z0-9]
- [][] 集合含左右中括号两个字符
- 减号在最后,则失去表示区间的意义。[ad-] 只与3个字符匹配
用 ^ 表示补集
- ^在开头,表示与集合内字符之外的任意字符匹配。如:[^a-z]匹配任意一非小写字母。[^][]匹配任意一非中括号字符。
- ^不在开头,则失去其表示补集的意义。如:[a-z^]能匹配27个单字符(^失去含义)。
1.3 单字符正则表达式的组合
串接
如 [A-Z].[0-9] # 第一个字符为大写字符,第二个为任意字符,第三个为数字字符
星号(*)
单字符正则表达式后跟*,匹配此单字符正则表达式的0次或任意多次出现。

单字符表达式组合 应用实例

- :1,$s # 从第一行到最后一行替换
- :1,$s/[0-9]*/xx/g # 将一行中的所有数字均替换为xx,/g表示所有替换。
- 上述例3在执行中会出现错误,因为*有可能代表0次出现。
锚点 $ 与 ^
$ 在尾部时有特殊含义,否则与其自身匹配
- 例:123$ 匹配文件中行尾的123,不在行尾的123字符不匹配
- 例:$123与字符串$123匹配
- 例:.$ 匹配行尾的任意字符
^ 在首部时有特殊意义,否则与其自身匹配
- 例:^printf匹配行首的ptintf字符串,不在行首的。(也就是说p必须在一行的第一个字符)
- 例:Hel^lo与字符串Hel^lo匹配
- 例:在vi中使用 :10,50s/^ //g 删除10-50行的每行行首的4个空格
正则表达式扩展

1.4 正则表达式相关的处理命令
1.4.1 grep/egrep/fgrep 在文件中查找字符串(筛选)
grep 在文件中查找字符串 (global regular expression print)
grep 模式 文件名列表
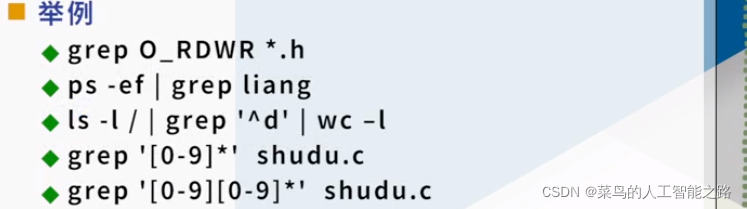
egrep 使用扩展正则表达式ERE描述模式
- 在指定模式方面比grep更灵活
fgrep 快速搜索指定字符串
- 按字符串搜索而不是按模式搜索



1.4.2 sed 流编辑(加工)
- sed '命令' 文件名列表
- sed -e '命令1' -e '命令2' -e '命令3' 文件名列表
- sed -f 命令文件 文件名列表

说明:tail -f 读取文件pppd.log中(尾部)新增加的内容,通过管道输送到后面sed的输入,s 是替换命令,末尾的 g 为全部替换(即一行中无论出现多少次IP都进行替换)。

替换文件中的 10-23-2013 的日期为 2013.10.23 的格式
- head -n 20 sort.c | sed 's/\([0-9][0-9]\)-\([0-9][0-9]\)-\([0-9][0-9]*\)/\3.\1.\2/'
上述命令后面 \3 表示前面命准的第一部分替换为第三部分。。。依次类推
1.4.3 awk 逐行扫描进行文本处理的语言(筛选与加工)
a.w.k 分别为该程序的三位设计者姓氏的第一个字母。


awk 描述条件的方法


awk 描述动作的方法

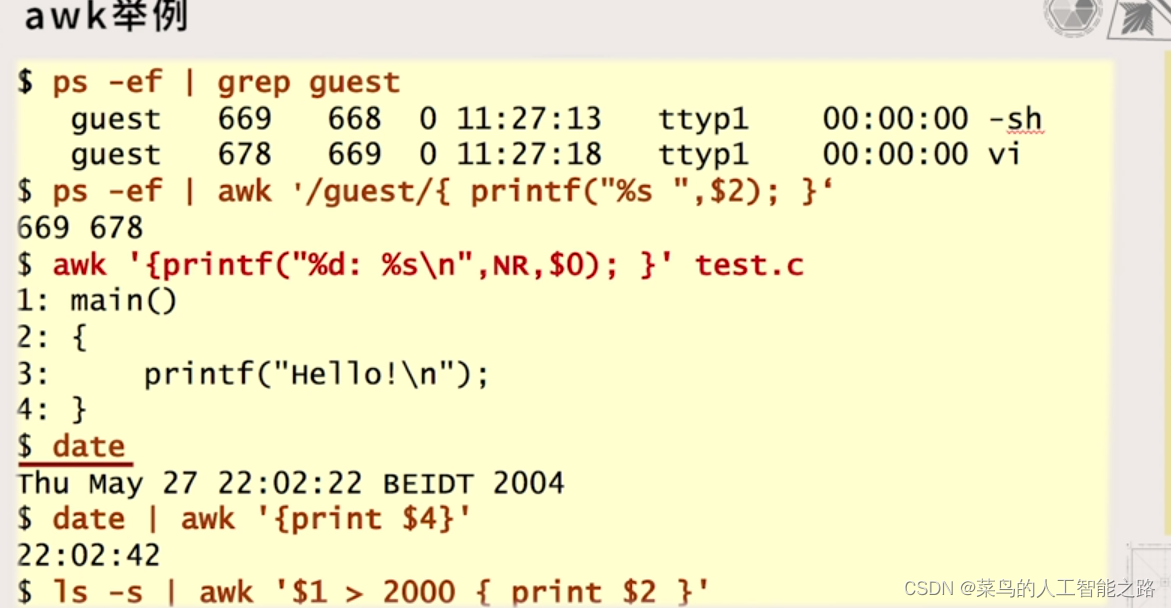
awk 举例
说明:
- 列出所有guest用户的进程,然后只打印第二列($2)的内容。
- 打印文件每一行增加行号,NR匹配行号,$0为整个这一行的内容,花括号前面没用符号表示全部文件匹配。
- 仅仅打印日期的第四列信息,即时间信息。
- 列出所有文件,只打印文件大小大于2M的文件的第二列信息。
2 正则表达式应用
2.1 例1 累加作品发行量

(1)去掉文件中的 “多” 字
- cat hh.txt | sed -e 's/多//g'
(2)将有 “x万” 的行进行替换(注意 “x万” 前面不为数字,且有可能数字后面有空格)
- cat hh.txt | sed -e 's/多//g' -e 's/.*[^0-9]\([0-9][0-9]*\) *万.*/\1/g'
(3)将每行开头为数字的行进行数字提取,然后进行累加
- cat hh.txt | sed -e 's/多//g' -e 's/.*[^0-9]\([0-9][0-9]*\) *万.*/\1/g' | awk '/^[0-9]/{sum+=$1}; END {print sum}'
2.2 例2 求一本书中出现频率最高的200个单词
(1)去除标点符号
- cat jian.txt | tr ';.?()-\047:' ' ' | more
- \047为单引号的8进制表示,为了防止和命令中的单引号冲突
(2)将空格替换为换行
- cat jian.txt | tr ';.?()-\047:' ' ' | tr ' ' '\012' | more
(3)过滤掉空行
- grep -v '^ *$' 删除所有的空行
- cat jian.txt | tr ';.?()-\047:' ' ' | tr ' ' '\012' | grep -v '^ *$' | more
(4)排序(相同的字符在一起)
- sort 排序
- cat jian.txt | tr ';.?()-\047:' ' ' | tr ' ' '\012' | grep -v '^ *$' | sort | more
(5)显示重复字符的计数
- uniq -c 显示重复字符的计数
- cat jian.txt | tr ';.?()-\047:' ' ' | tr ' ' '\012' | grep -v '^ *$' | sort | uniq -c
(6)再一次排序,同时留下最后200个字符
- cat jian.txt | tr ';.?()-\047:' ' ' | tr ' ' '\012' | grep -v '^ *$' | sort | uniq -c | sort -n | tail -n 200
2.3 例3 绘制旅客流量随时间变化的曲线
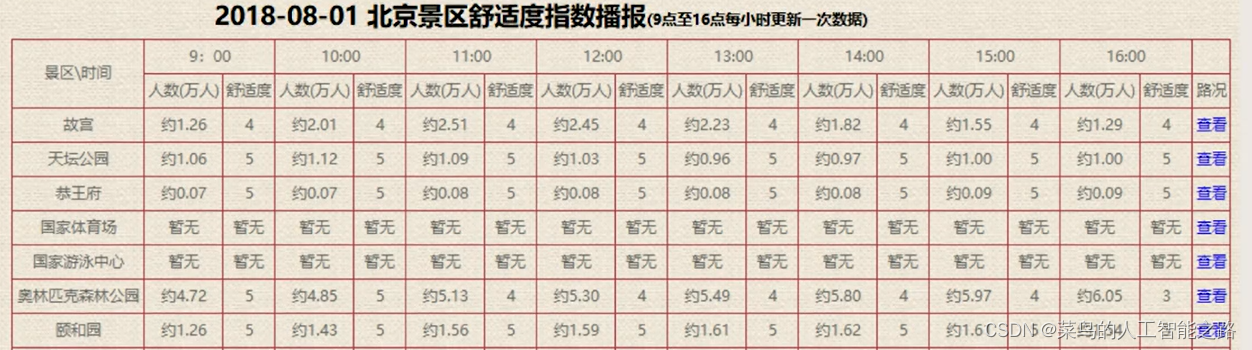
获取网页并修改文件名称。

具体实现参考《Linux开发环境及应用》蒋砚军