wallhaven壁纸网站改版后爬虫
新手上路,老司机绕路
最近学习python,尝试写一点小爬虫
这是改版后的wallhaven壁纸网站,爬取热门榜单。 首先对网站进行分析
首先对网站进行分析
 按F12启动开发者工具,对网页进行分析。
按F12启动开发者工具,对网页进行分析。
现在页面上的图片都是缩略图没有爬取的意义,需要对源图片进行爬取,定位到图片的位置上,图片属性中有一个href属性,这个属性是超链接,所以我们根据herf属性进一步爬取,打开其href属性中的网页。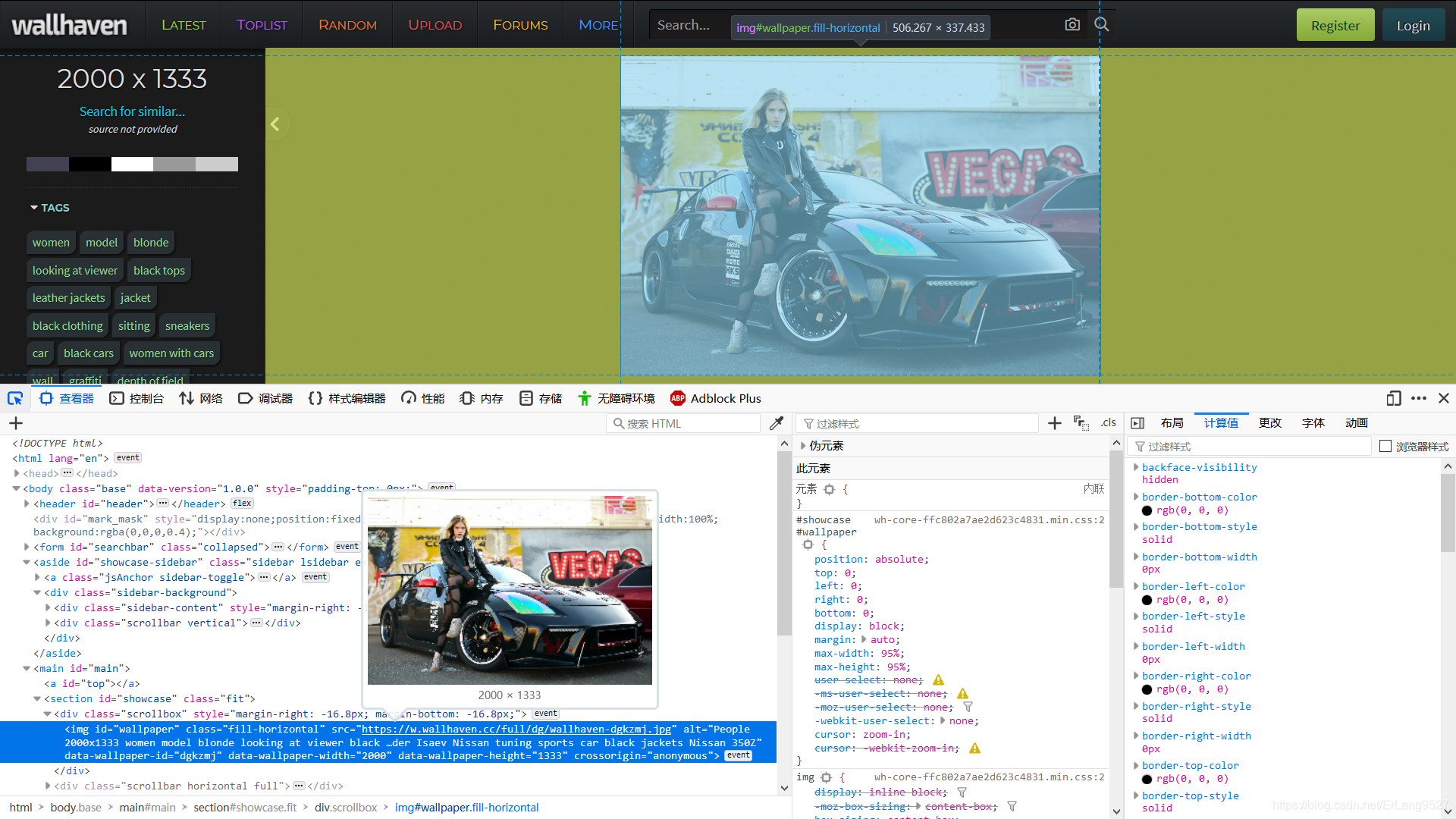
就得到了这张图片的源图片,而不是缩略图,然后使用爬虫对图片进行保存就可以了。
下面是对wallhaven网站的Toplist榜单进行爬取的小例子。
注意文件路径和获取范围根据个人调整
代码如下:
import requests
from lxml import etree
headers={
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0"
}
filepath="D:/Picture/wallhaven/" #文件路径
for i in range(1,11): #爬取页数
kv={"page":i}
url="https://wallhaven.cc/toplist"
try:
r=requests.get(url,headers=headers,params=kv,timeout=200)
#开始解析
html =etree.HTML(r.text)
srcs =html.xpath(".//li//a[@class='preview']/@href") #获取到跳转网页
for src in srcs :
r=requests.get(src,headers=headers,timeout=200)
html =etree.HTML(r.text)
img_src =html.xpath(".//img[@id='wallpaper']/@src")
for src in img_src :
filename_1= src.split('/')[-1] #获取文件名
response=requests.get(src,headers=headers)
with open(filepath+filename_1,'wb') as file:
file.write(response.content)
print(filename_1)
print("Succeed")
except:
continue
print("跳过")
print("Triumph")