Pythonk近傍アルゴリズムの回帰分析
基本コンセプト
機械学習の2つの概念を簡単に紹介します
1.分類と回帰
分類モデルの本質は回帰モデルと同じです。分類モデルは回帰モデルの出力を離散化します。
一般的に、回帰問題は住宅価格や将来の気象条件などの予測に使用されます。たとえば、製品の実際の価格は500元、回帰分析による予測値は499元です。これは比較の良い回帰分析だと思います。回帰は、真の値のおおよその予測です。
分類問題は、物にラベルを付けるために使用されます。通常、結果は離散値になります。たとえば、写真に写っている動物が猫か犬かを判断します。分類には近似の概念がありません。最終的に正しい結果は1つだけであり、間違った結果は間違っており、同様の概念はありません。
要するに:
定量的出力は回帰または連続変数予測と呼ばれ、明日の気温を予測します。これは回帰タスクです。
定性的出力は分類または離散変数予測と呼ばれます。明日が曇り、晴れ、雨のいずれになるかを予測することは、分類タスクの1つです。
2.フィッティングの
一般化:モデルがこれまでに見られなかった新しいデータに対して正確な予測を行うことができれば、トレーニングセットからテストセットのフィッティングまで一般化できると言えます:モデルがいくつかのサンプルをうまく記述できるかどうか、そして優れた一般化能力。アンダーフィッティング:テストサンプルの特性が学習されていないか、モデルが単純すぎてフィッティングできません。オーバーフィッティング:特性がトレーニングデータに近すぎます。これはトレーニングセットでは優れていますが、テストセットでは何もありません、一般化はありません
アルゴリズム入門
KNN回帰
KNNアルゴリズムは、分類だけでなく回帰にも使用できます。サンプルのk最近傍を見つけ、これらの近傍の特定の属性の平均値をサンプルに割り当てることにより、サンプルの対応する属性の値を取得できます。
Knn分類の実践はこの記事を参照できます:k近傍アルゴリズム-分類の実践
データソース
アボカドの単価予測(Kaggle):#https://www.kaggle.com/neuromusic/avocado-prices
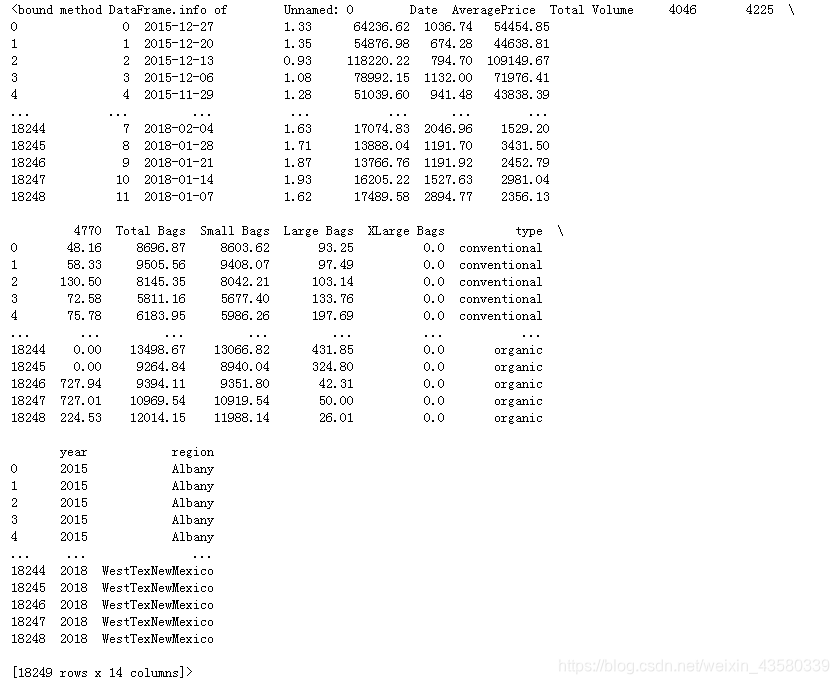
データには、2017年から2019年までのアボカドの単価、各販売の重量、アボカドの種類、原産地に関する情報が含まれています。

ヒント:4046、4225、4770は輸入果物のpluコードです。4桁のpluコードはアボカドの産地、種類、サイズ、その他の果物情報を表すため、4046、4225、4770は3種類のアボカドを表します。
一つ言いたいのは、普段果物を買うときは気づかないということです。少し役に立たない知識を知っています。
データマイニング
1.サードパーティライブラリをインポートします
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split#导入划分数据集的模块
from sklearn.neighbors import KNeighborsRegressor#导入knn回归算法
from sklearn.metrics import r2_score
古いルールでは、モデリングに必要なモジュールを順番にインポートします。データマイニングに必要なサードパーティライブラリである最初の4つのライブラリに加えて、r2_scoreに注目しましょう。
sklearn.metrics.r2_score(y_true、y_pred、sample_weight = None、multioutput = 'uniform_average')
y_true:観測値
y_pred:予測値
sample_weight:サンプルの重み、デフォルトなし
multioutput:多次元の入力と出力、オプションの 'raw_values'、 ' Uniform_average '、' variance_weighted 'またはNone。デフォルトは「
uniform_average 」です。raw_values:各ディメンションのスコアをそれぞれ返します。uniform_average:
各出力ディメンション
のスコアの平均variance_weighted:すべての出力のスコアを平均し、各出力の分散に従って重み付けします。
r2_scoreスコアは主要な回帰モデルのスコアリング方法であり、特定の原則は紹介されません。興味のある友人はこの記事を確認できます。詳細な調査:回帰モデルの評価指標R2_score
2.ファイルを読みます
import winreg
real_address = winreg.OpenKey(winreg.HKEY_CURRENT_USER,r'Software\Microsoft\Windows\CurrentVersion\Explorer\Shell Folders',)
file_address=winreg.QueryValueEx(real_address, "Desktop")[0]
file_address+='\\'
file_origin=file_address+"\\源数据-分析\\avocado.csv"#设立源数据文件的桌面绝对路径
glass=pd.read_csv(file_origin)#https://www.kaggle.com/neuromusic/avocado-prices
データをダウンロードするたびに、ファイルをpythonルートディレクトリに転送するか、ダウンロードフォルダで読み取る必要があるため、非常に面倒です。そこで、winregライブラリを介して絶対デスクトップパスを設定しました。これにより、データをデスクトップにダウンロードするか、デスクトップ上の特定のフォルダーに貼り付けるだけでデータを読み取ることができ、他のデータと混同されることはありません。
3.データをクリーンアップします
avocado.groupby(avocado["year"])["year"].count()
avocado_2017=avocado[avocado["year"]==2017].reset_index()
ここでは、モデリングデータとして2017年のデータを選択します。(データが多すぎると、ノイズ干渉が発生する場合があります)
avocado_2017=avocado_2017.replace({
"type":{
"conventional":0}})
avocado_2017=avocado_2017.replace({
"type":{
"organic":1}})
a=pd.DataFrame(avocado_2017.groupby(avocado_2017["region"])["region"].count())
a["replace_num"]=range(len(a.index))
for i in range(len(a.index)):
avocado_2017=avocado_2017.replace({
"region":{
a.index[i]:a.loc[a.index[i],"replace_num"]}})
###注意这里在利用.loc进行筛选时不能用数字索引进行筛选,因为当前a的行索引是一系列字符串
タイプと地域のテキストデータは少し複雑なので、replace関数を使用して、さまざまな種類と起源を表す番号を置き換えます。
実際、この置き換えは役に立たず、ブロガーがテキストデータに慣れることができないというだけです。
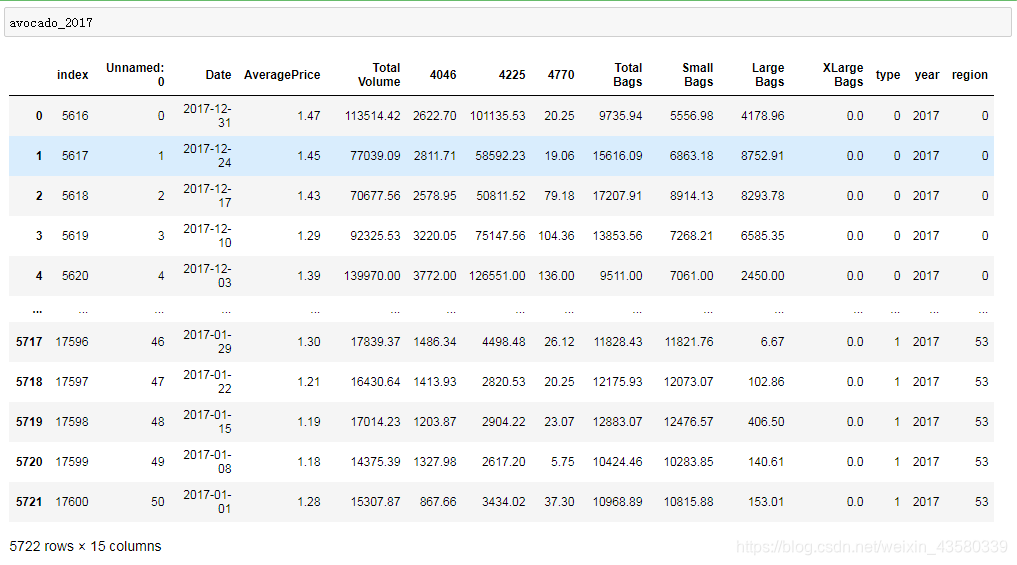
データTotalBags = Small Bags + Large Bags、XLarge Bags = 0、および地域とタイプの固有値はすべて4桁のpluコードに起因するため、過剰適合を回避するために、私は選択するだけです平均価格はこちら。総量、4046、4225、4770、小型バッグ、予測モデリング用の大型バッグ。
4.モデリング
X_train,X_test,y_train,y_test=train_test_split(avocado_2017[["Total Volume","4225","4046","4770","Small Bags","Large Bags"]],avocado_2017["AveragePrice"],random_state=24)
#注意特征值标签要放在前面,预测值标签要放在后面
#考虑到接下来可能需要进行其他的操作,所以定了一个随机种子,保证接下来的train和test是同一组数
列インデックスは特徴値と予測値に分割され、データはトレーニングセットとテストセットに分割されます。
knn=KNeighborsRegressor(n_neighbors=1)
knn.fit(X_train,y_train)
prediction=knn.predict(X_test)
r2_score(y_test,prediction)
knnアルゴリズムが導入され、アルゴリズムの近傍値が1に設定されます。モデリング後、テストセットの精度がスコアリングされ、得られた結果は次のとおりです。

モデルの精度は約50であることがわかります。%。
5.簡単なチューニング
以前に設定されたネイバーパラメータは1です。次に、さまざまなパラメータが順番にテストされ、最適なネイバーパラメータが何であるかが確認されます。
result={
}
for i in range(100):#一般n_neighbors的选取低于样本总数的平方根
knn=KNeighborsRegressor(n_neighbors=(i+1))
knn.fit(X_train,y_train)
prediction=knn.predict(X_test)
score=r2_score(y_test,prediction)
result[i+1]=score*100
for i in result.keys():
if result[i]==max(result.values()):
print("最佳邻近数:"+str(i))
print("模型评分:"+str(max(result.values())))
結果は次のとおりです
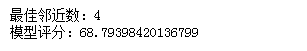
。1から100までのネイバー番号を順番に選択するプロセスでは、最適なネイバーパラメータは4であり、モデルの最高の精度スコアは68ポイントであることがわかります。(スコアが非常に低く、ブロガーはそれがアルゴリズム自体である可能性があると考えています。結局のところ、重みなどの他のパラメーターを調整できるフォレストまたはツリー回帰アルゴリズムとは異なり、これは単純なアルゴリズムです。 )
6.まとめ
1.隣接するパラメーターの変更に伴い、モデルの精度も変更され、特定の規則性が示されます。
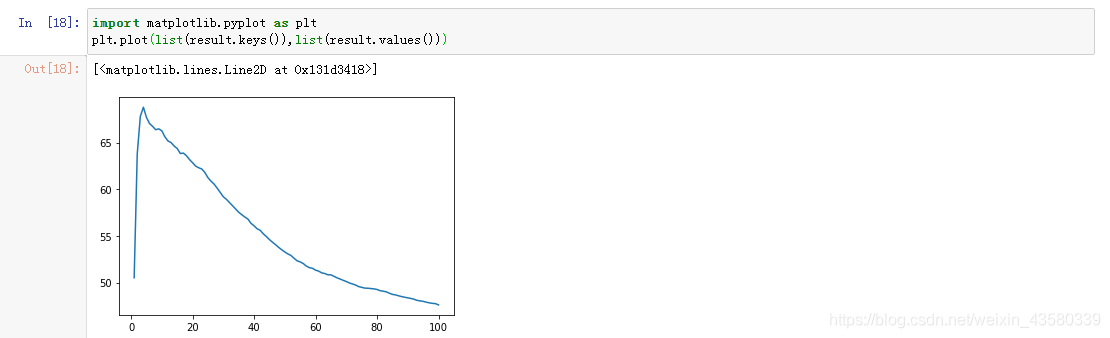
同じデータセットの場合、隣接するパラメーターが徐々に増加すると、モデルの精度が臨界点に達することが多く、その後徐々に低下します。他のknn回帰モデルもこの状況を示し、興味のある友人は自分でそれをチェックすることができます。
2.回帰アルゴリズムは、連続値を予測するためのアルゴリズムです。予測ラベル(pd.cut)をビニングして予測ラベルの変化範囲を予測する場合は、機能しません。ps:ブロガーはそれを試し、エラーを報告します。
3.データの種類ごとに異なる種類のアルゴリズムを選択する必要があります。各アルゴリズムには長所と短所があり、すべての問題を解決できるアルゴリズムはありません。したがって、将来のモデリングでは、気を悪くして注意を払う必要はありません。選択に。
うまくいかないところもたくさんありますが、ネチズンの方も大歓迎ですので、お友達とお会いして一緒に議論したいと思います。