1つは、文字列型の性質です。
1.文字列とオブジェクトの違い
文字列型とオブジェクトには3つの違いがあります。
- 文字アクセサメソッド(str.countなどの文字列アクセサメソッド)は、対応するデータのNullable型を返し、オブジェクトは、欠落している値が存在する場合に戻り値の型を変更します。
- 格納されている文字列がバイトではないため、一部のSeriesメソッドは文字列で使用できません。例:Series.str.decode()
- 文字列型に値の格納または操作がない場合、その型は浮動小数点np.nanではなくpd.NAとしてブロードキャストされます。
2.文字列型変換
別のタイプのコンテナが直接文字列型に変換される場合、それは間違っている可能性があります。2つの変換に分割し、最初にstr型オブジェクトに変換してから、文字列型に変換する必要があります。
#pd.Series([1,'1.']).astype('string') #报错
#pd.Series([1,2]).astype('string') #报错
#pd.Series([True,False]).astype('string') #报错
#正确的
pd.Series([1,'1.']).astype('str').astype('string')
pd.Series([1,2]).astype('str').astype('string')
pd.Series([True,False]).astype('str').astype('string')3.strとstringの違い
(A)str文字列を書く方法は3つあります。
一重引用符、二重引用符、三重引用符。
一重引用符と二重引用符は相互にネストでき、三重引用符は一重引用符と二重引用符の間にネストして、文字列を複数行に展開できます。ネストするには、円記号を使用して転送する必要があります。
注:2つの文字列リテラルの間にスペースしかない場合、それらは自動的に文字列に変換されます
第二に、分割とスプライシング
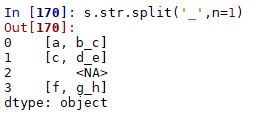
1.str.splitメソッド
(A)セパレーターとstrの位置要素の選択
s = pd.Series(['a_b_c', 'c_d_e', np.nan, 'f_g_h'], dtype="string")
s.str.split('_')
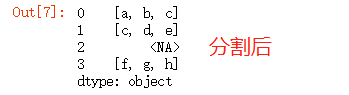
分割後の型はオブジェクトであることに注意してください。これは、シリーズの要素が文字列ではなくリストを含み、文字列型に含めることができるのは文字列のみであるためです。
strメソッドの場合、要素を選択できます。セル要素がリストの場合、str [i]はi番目の要素を取得することを意味します。単一要素の場合は、最初に要素をリストに変換してから取得します。でる
s.str.split('_').str[1]
(B)その他のパラメーター
展開パラメーターは列を分割するかどうかを制御し、nパラメーターは分割の最大数を表します


2.str.catメソッド
(A)さまざまなオブジェクトのステッチモード
単一のシリーズの場合、すべての要素を文字列に結合することを指します。ここで、オプションのsepセパレーターパラメーターと欠落値が文字na_repパラメーターに置き換わります。
s = pd.Series(['ab',None,'d'],dtype='string')
print(s)
s.str.cat(sep=',',na_rep='*')

2つのシリーズのマージでは、対応するインデックスの要素がマージされ、対応するパラメーターもありますが、2つの欠落している値が同時に置き換えられることに注意してください
s = pd.Series(['ab',None,'d'],dtype='string')
print(s)
s2 = pd.Series(['24',None,None],dtype='string')
print(s2)
#使用分割符
s.str.cat(s2,sep=',',na_rep='*')
マルチカラムスプライシングは、テーブルスプライシングとマルチシリーズスプライシングに分けることができます
#表的拼接
s.str.cat(pd.DataFrame({0:['1','3','5'],1:['5','b',None]},dtype='string'),na_rep='*')
#多个Series拼接
s.str.cat([s+'0',s*2])
(B)猫のインデックスアラインメント
現在のバージョンでは、2つのマージされたインデックスが同じでなく、joinパラメータが指定されていない場合、デフォルトは左結合です。join= 'left'を設定します。
s2 = pd.Series(list('abc'),index=[1,2,3],dtype='string')
print(s2)
s.str.cat(s2,na_rep='*')

3、交換
1.str.replaceの一般的な使用法¶
最初の値のrの先頭に正規表現を記述し、後者の置換文字列を記述します
s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca','', np.nan, 'CABA', 'dog', 'cat'],dtype="string")
print(s)
s.str.replace(r'^[AB]','***')

2.サブグループと機能の置き換え
正の整数でサブグループを呼び出します(0は文字自体を返し、1から始まるのはサブグループです)
s.str.replace(r'([ABC])(\w+)',lambda x:x.group(2)[1:]+'*')
サブグループに名前を付けて呼び出すには、?<...>を使用します
s.str.replace(r'(?P<one>[ABC])(?P<two>\w+)',lambda x:x.group('two')[1:]+'*')
3.str.replaceの考慮事項
- str.replaceはオブジェクト型または文字列型用であり、デフォルトの操作は正規表現です。現在、DataFrameでの使用はサポートされていません。
- 置換は、任意のタイプのシーケンスまたはデータフレーム用です。正規表現で置換する場合は、regex = Trueを設定する必要があります。このメソッドは、辞書を介した複数列の置換をサポートしますが、文字列の最初の導入によります。タイプ、いくつかの使用法が表示されます問題、これらの問題は将来のバージョンで修正される予定です
(A)str.replace割り当てパラメーターはpd.NAであってはなりません
#pd.Series(['A','B'],dtype='string').str.replace(r'[A]',pd.NA) #报错
#pd.Series(['A','B'],dtype='O').str.replace(r'[A]',pd.NA) #报错
pd.Series(['A','B'],dtype='string').astype('O').replace(r'[A]',pd.NA,regex=True).astype('string')
(B)文字列型シリーズの場合、置換機能を使用する場合、正規表現は使用できません。
pd.Series(['A','B'],dtype='string').replace(r'[A]','C',regex=True)

pd.Series(['A','B'],dtype='O').replace(r'[A]','C',regex=True)
(C)文字列型シーケンスに欠落している値がある場合、replaceは使用できません。
pd.Series(['A',np.nan],dtype='string').str.replace('A','B')
第四に、部分文字列のマッチングと抽出
1.str.extractメソッド
(A)一般的な方法
pd.Series(['10-87', '10-88', '10-89'],dtype="string").str.extract(r'([\d]{2})-([\d]{2})')列名としてサブグループ名を使用する
pd.Series(['10-87', '10-88', '-89'],dtype="string").str.extract(r'(?P<name_1>[\d]{2})-(?P<name_2>[\d]{2})')使用する?定期的なメーター選択パーツ抽出
pd.Series(['10-87', '10-88', '-89'],dtype="string").str.extract(r'(?P<name_1>[\d]{2})?-(?P<name_2>[\d]{2})')(B)拡張パラメーター(デフォルトはTrue)
Seriesのサブグループの場合、expandがFalseに設定されていると、Seriesが返されます。それがサブグループより大きい場合、expandパラメーターは無効になり、すべてがDataFrameとして返されます。
サブグループのインデックスの場合、expandがFalseに設定されていると、抽出されたインデックスが返されます。サブグループより大きく、expandがFalseの場合、エラーが報告されます。
s = pd.Series(["a1", "b2", "c3"], ["A11", "B22", "C33"], dtype="string")
s.index![]()
s.str.extract(r'([\w])')
s.str.extract(r'([\w])',expand=False)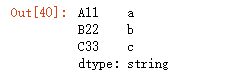
s.index.str.extract(r'([\w])')
s.index.str.extract(r'([\w])',expand=False)![]()
s.index.str.extract(r'([\w])([\d])')
2.str.extractallメソッド
最初の修飾された式にのみ一致するextractとは異なり、extractallはすべての修飾された文字列を検索し、マルチレベルインデックスを構築します(1つだけが見つかった場合でも)¶
s = pd.Series(["a1a2", "b1", "c1"], index=["A", "B", "C"],dtype="string")
two_groups = '(?P<letter>[a-z])(?P<digit>[0-9])'
s.str.extract(two_groups, expand=True)
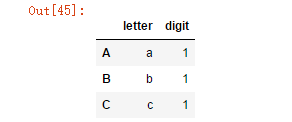
s.str.extractall(two_groups)
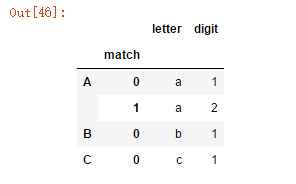
s['A']='a1'
s.str.extractall(two_groups)
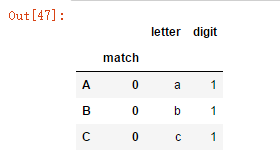
s = pd.Series(["a1a2", "b1b2", "c1c2"], index=["A", "B", "C"],dtype="string")
s.str.extractall(two_groups).xs(1,level='match')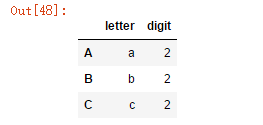
3.str.contains和str.match
str.containsは、特定の規則的なパターンが含まれているかどうかを検出するためのものです。オプションのパラメーターはnaです。
#查看是否包含字母和数字
pd.Series(['1', None, '3a', '3b', '03c'], dtype="string").str.contains(r'[0-9][a-z]')
#查看是否包含a
pd.Series(['1', None, '3a', '3b', '03c'], dtype="string").str.contains('a', na=False)str.matchとstr.contrainsの違いは、matchはPythonのre.matchに依存して、コンテンツに最初から通常のパターンが含まれているかどうかを検出することです。
pd.Series(['1', None, '3a_', '3b', '03c'], dtype="string").str.match(r'[0-9][a-z]',na=False)
pd.Series(['1', None, '_3a', '3b', '03c'], dtype="string").str.match(r'[0-9][a-z]',na=False)一般的に使用される5つの文字列メソッド
1.フィルタリング方法
(A)str.stripは、多くの場合、フィルタリングスペースと同じです。
pd.Series(list('abc'),index=[' space1 ','space2 ',' space3'],dtype="string").index.str.strip()
(B)str.lower(小文字)およびstr.upper(大文字)
pd.Series('A',dtype="string").str.lower()
pd.Series('a',dtype="string").str.upper()(C)str.swapcaseとstr.capitalize(大文字と小文字を入れ替えて最初の文字を大文字にする)
pd.Series('abCD',dtype="string").str.swapcase()#大写变小写,小写变大写
pd.Series('abCD',dtype="string").str.capitalize()#将字符串的第一个字母变成大写,其他字母变小写2.isnumericメソッド
各桁が数字かどうかを確認し、数字かどうかをどのように判断しますか
pd.Series(['1.2','1','-0.3','a',np.nan],dtype="string").str.isnumeric()運動:
質問2:
col2の平均値を見つけるには、文字列型の負の数を理解できる負の数に変換する方法を検討する必要があります。ここでは、splitを使用して文字列を2つの部分に分割します。整数は直接変換でき、負の数は、-1を掛けることで変換できます。、変換プロセスで0、9 '、/ 7などの不適合文字が見つかった場合は、最初にそれらを変換できます(数が大きくない場合)。コードは次のように表示されます。
df.loc[[309,396,485],'col2'] = ['0','9','7']
collist = []
for i in range (df['col2'].shape[0]):
strlist = df['col2'][i].split('-')
if len(strlist)==2 and strlist[0] =='':
col = int(strlist[1])*(-1)
else:
col = int(strlist[0])
collist.append(col)
df['new_col2'] = collist
df['new_col2'].mean()公式の答え、通常の考えは、正規表現を使用して型にはまらない文字を除外し、それらを変換できるというものです。正規表現はあまり良くありませんが、まだ学習しています。
df['col2'][~(df['col2'].str.replace(r'-?\d+','True')=='True')] #这三行有问题
df.loc[[309,396,485],'col2'] = [0,9,7]
df['col2'].astype('int').mean()