複数のサーバー、実験環境を構成する必要があります:マスターとデータの2つのサーバー、hadoopがインストールされています、前の記事を参照してください!!!
1.sparkのインストール
- マスターインストール
(1)scalaとsparkをダウンロードする
(2)環境変数を解凍して構成します
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
export SPARK_HOME=/home/spark-2.4.5-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin(3)spark-env.shファイルを構成します
export SPARK_MASTER_IP=IP
export SPARK_MASTER_HOST=IP
export SPARK_WORKER_MEMORY=512m
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=4
export SPARK_MASTER_PORT=7077(4)スレーブファイルを設定します
data
- データのインストール
(1)scalaとsparkをダウンロードする
(2)環境変数を解凍して構成します
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
export SPARK_HOME=/home/spark-2.4.5-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin(3)spark-env.shファイルを構成します
export SPARK_MASTER_IP=IP
export SPARK_MASTER_HOST=IP
export SPARK_WORKER_MEMORY=512m
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=4
export SPARK_MASTER_PORT=7077起動してテストします。
開始するsbinディレクトリを入力します:start-all.shまたはstart-master.sh、start-slaves.sh、jpsを入力します:
マスター表示: データ表示:
データ表示: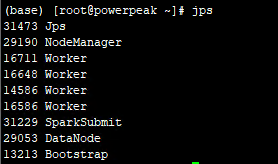
次に、pysparkを開始します。
pyspark 正常にアクセスして、モードを変更できます。
pyspark --master spark://master_ip:70772. Anacondaを構成し、Jupyterにリモートアクセスします
(1)Anacondaをインストールします
インストール:![]()
環境変数を構成します。![]()
(2)Jupyterのリモート構成
参照:https://blog.csdn.net/MuziZZ/article/details/101703604
(3)pysparkとpythonの組み合わせ
export PATH=$PATH:/root/anaconda3/bin
export ANACONDA_PATH=/root/anaconda3
export PYSPARK_DRIVER_PYTHON=$ANACONDA_PATH/bin/jupyter-notebook
#PARK_DRIVER_PYTHON="jupyter" PYSPARK_DRIVER_PYTHON_OPTS="notebook" pyspark
export PYSPARK_PYTHON=$ANACONDA_PATH/bin/pythonアクセスインターフェース:
