http面接の質問
- フロントエンドエンジニア開発インターフェース
- データを送信/取得するには、バックエンドインターフェイスを使用する必要があります-httpプロトコル
- 事前にajaxを十分に把握する必要があります
httpとは
HTTPプロトコルは、Hyper Text Transfer Protocol(Hyper Text Transfer Protocol)の略で、ワールドワイドウェブ(WWW:ワールドワイドウェブ)サーバーからローカルブラウザにハイパーテキストを転送するために使用される転送プロトコルです。
これは、データ(HTMLファイル、画像ファイル、クエリ結果など)を転送するためのTCP / IP通信プロトコルに基づいています
。HTTPプロトコルは、アプリケーション層に属するオブジェクト指向のプロトコルです。簡潔で高速な方法のため、分散型ハイパーメディアシステムに適しています。
これにはいくつかの特徴があります
。1。シンプルで高速:クライアントがサーバーにサービスを要求するとき、要求メソッドとパスを送信するだけで済みます。
2.柔軟性:HTTPを使用すると、あらゆるタイプのデータオブジェクトを送信できます。
3.接続なし:接続なしの意味は、各接続を1つの要求のみを処理するように制限することです。
4.ステートレス:HTTPプロトコルはステートレスプロトコルです。ステートレスとは、プロトコルにトランザクション処理用のメモリ容量がないことを意味します。
一般的なhttpステータスコードは何ですか
ステータスコード:
1xxは情報です
といった:
100:サーバーは要求の一部のみを受信しますが、サーバーが要求を拒否しない場合、クライアントは残りの要求を送信し続ける必要があります。
2xxは成功クラスです
といった
200:リクエストは成功しました
。201:リクエストが作成され、同時に新しいリソースが作成されます。
202:処理の要求は受け入れられましたが、処理は完了していません。
3xxはリダイレクトクラスです
といった:
300:複数選択、接続リスト。
301:要求されたページは新しいURLに転送されました。ここでは、301と302の違いに注意してください。301は、永続的な転送がAからBに永続的に転送され、Aに何も残っていないことを強調しています。302は一時的にBに転送され、Aのものはまだ
302です:要求されたページは一時的に新しいURLに転送されました。
303:要求されたページは他のURLの下にあります。
4xxクライアントエラークラス
といった:
400:サーバーがリクエストを理解できませんでした、
401:ログインに失敗しました、
402:このコードはまだ利用できません、
403:リクエストされたページは禁止されています、
404:ファイルまたはディレクトリが見つかりません、
405:リクエストで指定されたメソッドはありません許可、
408:リクエストがタイムアウトしました
5xxサーバーエラークラス
といった:
501:要求が完了しておらず、サーバーが要求された機能をサポートしていません。
502:要求は完了せず、サーバーはアップストリームサーバーから無効な応答を受信しました。
504ゲートウェイのタイムアウト
一般的なHTTPヘッダーは何ですか
HTTP(Hyper Text Transfer Protocol)は、Webページ転送用の現在のユニバーサルプロトコルであるハイパーテキスト転送プロトコルです。HTTPプロトコルは要求/応答モデルを使用します。ブラウザまたは他のクライアントが要求を送信し、サーバーが応答します。ネットワークリソースの送信全体に関する限り、メッセージヘッダーとメッセージ本文の2つの部分が含まれます。最初にメッセージヘッダー、つまりhttpheaderメッセージを渡します。httpヘッダーメッセージは通常、一般ヘッダー、要求ヘッダー、応答ヘッダー、エンティティヘッダーの4つの部分に分かれています。しかし、理解の面では、この分割方法は境界が明確ではないと感じています。ウィキペディアのhttpヘッダーコンテンツの構成によると、それは大きく2つの部分に分けられます:要求と応答。
リクエストセクション
| ヘッダ | 説明 | 例 |
|---|---|---|
| 受け入れる | クライアントが受信できるコンテンツのタイプを指定します | 受け入れる:text / plain、text / html |
| Accept-Charset | ブラウザが受け入れることができる文字エンコーディングセット。 | Accept-Charset:iso-8859-5 |
| Accept-Encoding | ブラウザがサポートできるWebサーバーから返されるコンテンツ圧縮エンコーディングのタイプを指定します。 | Accept-Encoding:compress、gzip |
| 受け入れる-言語 | ブラウザで使用可能な言語 | 受け入れる-言語:en、zh |
| Accept-Ranges | ページエンティティの1つ以上のサブスコープフィールドをリクエストできます | Accept-Ranges:バイト |
| 承認 | HTTP認証用の認証証明書 | 承認:基本QWxhZGRpbjpvcGVuIHNlc2FtZQ == |
| キャッシュ制御 | 要求と応答が従うキャッシュメカニズムを指定します | キャッシュ制御:キャッシュなし |
| 接続 | 持続的接続が必要かどうかを示します。(HTTP 1.1はデフォルトで持続的接続です) | 接続:閉じる |
| クッキー | HTTPリクエストが送信されると、リクエストされたドメイン名で保存されているすべてのCookie値が一緒にウェブサーバーに送信されます。 | クッキー:$ Version = 1; スキン=新規; |
| コンテンツの長さ | 要求されたコンテンツの長さ | コンテンツの長さ:348 |
| コンテンツタイプ | エンティティに対応する要求されたMIME情報 | コンテンツタイプ:application / x-www-form-urlencoded |
| 日付 | リクエストが送信された日時 | 日付:2010年11月15日火曜日08:12:31 GMT |
| 期待する | 要求された特定のサーバーの動作 | 期待:100-続行 |
| から | リクエストを行ったユーザーのメールアドレス | 差出人:[email protected] |
| ホスト | 要求されたサーバーのドメイン名とポート番号を指定します | ホスト:www.zcmhi.com |
| If-Match | 要求されたコンテンツがエンティティと一致する場合にのみ有効です | 一致する場合:「737060cd8c284d8af7ad3082f209582d」 |
| 変更された場合-以降 | 要求された部分が指定された時間後に変更された場合、要求は成功し、変更されていない場合は304コードが返されます。 | 変更された場合-以降:2010年10月29日土曜日19:43:31 GMT |
| If-None-Match | コンテンツが変更されていない場合は、304コードを返します。パラメーターは、以前にサーバーから送信されたEtagであり、サーバーから応答されたEtagと比較して、変更されたかどうかを判断します。 | 一致しない場合:「737060cd8c284d8af7ad3082f209582d」 |
| If-Range | エンティティが変更されていない場合、サーバーはクライアントの欠落している部分を送信します。変更されていない場合、エンティティ全体が送信されます。パラメータもEtagです | If-Range:「737060cd8c284d8af7ad3082f209582d」 |
| 場合-変更なし-以降 | 指定された時間後にエンティティが変更されていない場合にのみ、要求は成功します | 変更されていない場合-以降:2010年10月29日土曜日19:43:31 GMT |
| マックスフォワード | 情報がプロキシとゲートウェイを通過する時間を制限する | 最大フォワード:10 |
| プラグマ | 実装固有の指示を含めるために使用されます | プラグマ:キャッシュなし |
| プロキシ認証 | エージェントに接続するための認証証明書 | プロキシ認証:基本的なQWxhZGRpbjpvcGVuIHNlc2FtZQ == |
| 範囲 | エンティティの一部のみをリクエストし、 | 指定範囲範囲:bytes = 500-999 |
| リファラー | 前のWebページのアドレス、現在の要求Webページがすぐに追跡されます。つまり、発信元です。 | リファラー:http://www.zcmhi.com/archives/71.html |
| に | クライアントは転送エンコーディングを受け入れ、サーバーにテールとヘッダー情報を受け入れるように通知します | TE:トレーラー、収縮; q = 0.5 |
| アップグレード | サーバーが変換する特定の転送プロトコルをサーバーに割り当てます(サポートされている場合) | アップグレード:HTTP / 2.0、SHTTP / 1.3、IRC / 6.9、RTA / x11 |
| ユーザーエージェント | User-Agentのコンテンツには、リクエストを行ったユーザーの情報が含まれています | ユーザーエージェント:Mozilla / 5.0(Linux; X11) |
| 経由 | 中間ゲートウェイまたはプロキシサーバーのアドレスと通信プロトコルを通知する | 経由:1.0 fred、1.1 nowhere.com(Apache / 1.1) |
| 警告 | メッセージエンティティに関する警告情報 | 警告:199その他の警告 |
応答セクション
| ヘッダ | 説明 | 例 |
|---|---|---|
| Accept-Ranges | 表明服务器是否支持指定范围请求及哪种类型的分段请求 | Accept-Ranges: bytes |
| Age | 从原始服务器到代理缓存形成的估算时间(以秒计,非负) | Age: 12 |
| Allow | 对某网络资源的有效的请求行为,不允许则返回405 Allow: GET, HEAD | |
| Cache-Control | 告诉所有的缓存机制是否可以缓存及哪种类型 Cache-Control: no-cache | |
| Content-Encoding | web服务器支持的返回内容压缩编码类型。 | Content-Encoding: gzip |
| Content-Language | 响应体的语言 | Content-Language: en,zh |
| Content-Length | 响应体的长度 | Content-Length: 348 |
| Content-Location | 请求资源可替代的备用的另一地址 | Content-Location: /index.htm |
| Content-MD5 | 返回资源的MD5校验值 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
| Content-Range | 在整个返回体中本部分的字节位置 | Content-Range: bytes 21010-47021/47022 |
| Content-Type | 返回内容的MIME类型 | Content-Type: text/html; charset=utf-8 |
| Date | 原始服务器消息发出的时间 | Date: Tue, 15 Nov 2010 08:12:31 GMT |
| ETag | 请求变量的实体标签的当前值 | ETag: “737060cd8c284d8af7ad3082f209582d” |
| Expires | 响应过期的日期和时间 | Expires: Thu, 01 Dec 2010 16:00:00 GMT |
| Last-Modified | 请求资源的最后修改时间 | Last-Modified: Tue, 15 Nov 2010 12:45:26 GMT |
| Location | 用来重定向接收方到非请求URL的位置来完成请求或标识新的资源 | Location: http://www.zcmhi.com/archives/94.html |
| Pragma | 包括实现特定的指令,它可应用到响应链上的任何接收方 | Pragma: no-cache |
| Proxy-Authenticate | 它指出认证方案和可应用到代理的该URL上的参数 | Proxy-Authenticate: Basic |
| refresh | 应用于重定向或一个新的资源被创造,在5秒之后重定向(由网景提出,被大部分浏览器支持) | Refresh: 5; url=http://www.zcmhi.com/archives/94.html |
| Retry-After | 如果实体暂时不可取,通知客户端在指定时间之后再次尝试 | Retry-After: 120 |
| Server | web服务器软件名称 | Server: Apache/1.3.27 (Unix) (Red-Hat/Linux) |
| Set-Cookie | 设置Http Cookie | Set-Cookie: UserID=JohnDoe; Max-Age=3600; Version=1 |
| Transfer-Encoding | 文件传输编码 | Transfer-Encoding:chunked |
| Vary | 告诉下游代理是使用缓存响应还是从原始服务器请求 | Vary: * |
| Via | 告知代理客户端响应是通过哪里发送的 | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning | 警告实体可能存在的问题 | Warning: 199 Miscellaneous warning |
| WWW-Authenticate | 表明客户端请求实体应该使用的授权方案 | WWW-Authenticate: Basic |
HTTP Request的Header信息
1、HTTP请求方式
GET 向Web服务器请求一个文件
POST 向Web服务器发送数据让Web服务器进行处理
PUT 向Web服务器发送数据并存储在Web服务器内部
HEAD 检查一个对象是否存在
DELETE 从Web服务器上删除一个文件
CONNECT 对通道提供支持
TRACE 跟踪到服务器的路径
OPTIONS 查询Web服务器的性能
说明:
主要使用到“GET”和“POST”。
实例:
POST /test/tupian/cm HTTP/1.1
分成三部分:
(1)POST:HTTP请求方式
(2)/test/tupian/cm:请求Web服务器的目录地址(或者指令)
(3)HTTP/1.1: URI(Uniform Resource Identifier,统一资源标识符)及其版本
备注:
在Ajax中,对应method属性设置。
2、Host
说明:
请求的web服务器域名地址
实例:
例如web请求URL:http://zjm-forum-test10.zjm.baidu.com:8088/test/tupian/cm
Host就为zjm-forum-test10.zjm.baidu.com:8088
3、User-Agent
说明:
HTTP客户端运行的浏览器类型的详细信息。通过该头部信息,web服务器可以判断到当前HTTP请求的客户端浏览器类别。
实例:
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11
4、Accept
说明:
指定客户端能够接收的内容类型,内容类型中的先后次序表示客户端接收的先后次序。
实例:
例如:
Accept:text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,/;q=0.5
备注:
在Prototyp(1.5)的Ajax代码封装中,将Accept默认设置为“text/javascript, text/html, application/xml, text/xml, /”。这是因为Ajax默认获取服务器返回的Json数据模式。
在Ajax代码中,可以使用XMLHttpRequest 对象中setRequestHeader函数方法来动态设置这些Header信息。
5、Accept-Language
说明:
指定HTTP客户端浏览器用来展示返回信息所优先选择的语言。
实例:
Accept-Language: zh-cn,zh;q=0.5
这里默认为中文
6、Accept-Encoding
说明:
指定客户端浏览器可以支持的web服务器返回内容压缩编码类型。表示允许服务器在将输出内容发送到客户端以前进行压缩,以节约带宽。而这里设置的就是客户端浏览器所能够支持的返回压缩格式。
实例:
Accept-Encoding: gzip,deflate
备注:
其实在百度很多产品线中,apache在给客户端返回页面数据之前,将数据以gzip格式进行压缩。
另外有关deflate压缩介绍:
http://man.chinaunix.net/newsoft/ApacheMenual_CN_2.2new/mod/mod_deflate.html
7、Accept-Charset
说明:
浏览器可以接受的字符编码集。
实例:
Accept-Charset: gb2312,utf-8;q=0.7,*;q=0.7
8、Content-Type
说明:
显示此HTTP请求提交的内容类型。一般只有post提交时才需要设置该属性。
实例:
Content-type: application/x-www-form-urlencoded;charset:UTF-8
有关Content-Type属性值可以如下两种编码类型:
(1)“application/x-www-form-urlencoded”: 表单数据向服务器提交时所采用的编码类型,默认的缺省值就是“application/x-www-form-urlencoded”。 然而,在向服务器发送大量的文本、包含非ASCII字符的文本或二进制数据时这种编码方式效率很低。
(2)“multipart/form-data”: 在文件上载时,所使用的编码类型应当是“multipart/form-data”,它既可以发送文本数据,也支持二进制数据上载。
当提交为单单数据时,可以使用“application/x-www-form-urlencoded”;当提交的是文件时,就需要使用“multipart/form-data”编码类型。
在Content-Type属性当中还是指定提交内容的charset字符编码。一般不进行设置,它只是告诉web服务器post提交的数据采用的何种字符编码。
一般在开发过程,是由前端工程与后端UI工程师商量好使用什么字符编码格式来post提交的,然后后端ui工程师按照固定的字符编码来解析提交的数据。所以这里设置的charset没有多大作用。
9、Connection
说明:
表示是否需要持久连接。如果web服务器端看到这里的值为“Keep-Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),它就可以利用持久连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。要实现这一点, web服务器需要在返回给客户端HTTP头信息中发送一个Content-Length(返回信息正文的长度)头,最简单的实现方法是:先把内容写入ByteArrayOutputStream,然 后在正式写出内容之前计算它的大小。
实例:
Connection: keep-alive
10、Keep-Alive
说明:
显示此HTTP连接的Keep-Alive时间。使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
以前HTTP请求是一站式连接,从HTTP/1.1协议之后,就有了长连接,即在规定的Keep-Alive时间内,连接是不会断开的。
实例:
Keep-Alive: 300
11、cookie
说明:
HTTP请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器。
12、Referer
说明:
包含一个URL,用户从该URL代表的页面出发访问当前请求的页面
HTTP Response的Header信息
1、Content-Length
说明:
表示web服务器返回消息正文的长度
2、Content-Type:
说明:
返回数据的类型(例如text/html文本类型)和字符编码格式。
实例:
Content-Type: text/html;charset=utf-8
3、Date
说明:
显示当前的时间
什么是 Restful API
REST,即Representational State Transfer的缩写。直接翻译的意思是"表现层状态转化"。
它是一种互联网应用程序的API设计理念:URL定位资源,用HTTP动词
(GET,POST,DELETE,DETC)描述操作。
产生背景
近年来移动互联网的发展,前端设备层出不穷(手机、平板、桌面电脑、其他专用设备…),因此,必须有一种统一的机制,方便不同的前端设备与后端进行通信,于是RESTful诞生了,它可以通过一套统一的接口为 Web,iOS和Android提供服务。
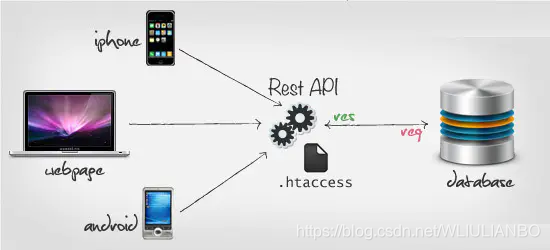
URI
即统一资源标识符,服务器上每一种资源,比如文档、图像、视频片段、程序 都由一个通用资源标识符(Uniform Resource Identifier, 简称"URI")进行定位。
HTTP动词
常用的HTTP动词有下面五个
- GET(SELECT):从服务器取出资源(一项或多项)。
- POST(CREATE):在服务器新建一个资源。
- PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
- PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
- DELETE(DELETE):从服务器删除资源。
RESTful架构
服务器上每一种资源,比如一个文件,一张图片,一部电影,都有对应的url地址,如果我们的客户端需要对服务器上的这个资源进行操作,就需要通过http协议执行相应的动作来操作它,比如进行获取,更新,删除。
简单来说就是url地址中只包含名词表示资源,使用http动词表示动作进行操作资源
举个例子:左边是错误的设计,而右边是正确的
GET /blog/getArticles --> GET /blog/Articles 获取所有文章
GET /blog/addArticles --> POST /blog/Articles 添加一篇文章
GET /blog/editArticles --> PUT /blog/Articles 修改一篇文章
GET /rest/api/deleteArticles?id=1 --> DELETE /blog/Articles/1 删除一篇文章
描述一下 http 的缓存机制(重要)
一、前方
通过网络请求资源缓慢并且降低了客户端的用户体验,增添了服务端的负担。很多短期之内不会经常发生变化的资源文件没必要每次访问都向服务端进行数据请求,而缓存策略的使用就是为了改善客户端的呈现时间,降低服务端的负担。
二、缓存规则及解析
为方便理解,假设浏览器存在一个缓存数据库,用于存储缓存信息。在客户端第一次请求数据时,此时缓存数据库中没有对应的缓存数据,需要请求服务器,服务器返回后,将数据存储至缓存数据库中,如下图:
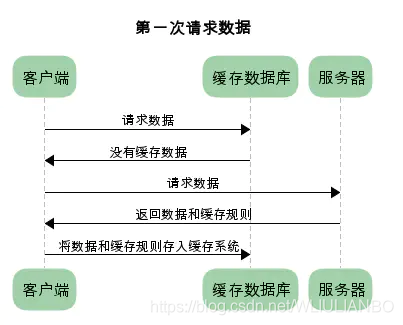
根据是否需要重新向服务器发起请求分类,将HTTP缓存规则分为两在类(强制缓存,对比缓存「也叫协商缓存」):
(1)已存在缓存数据时,仅基于强制缓存,请求数据的流程如下所示:
(2)已存在缓存数据时,仅基于协商缓存,请求数据流程如下:
我们可以看到两种缓存规则的不同,强制缓存如果生效,不需要再和服务器发生交互,而协商缓存不管是否生效,都需要与服务端发生交互。
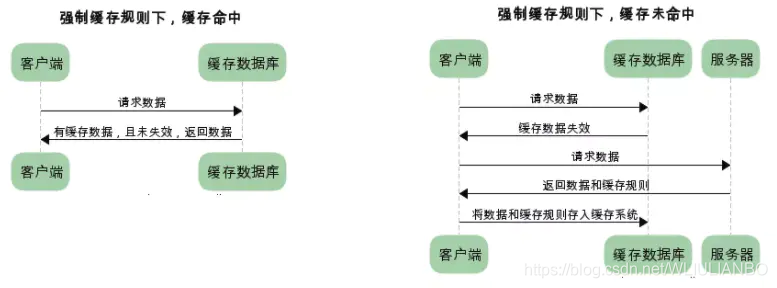

两类缓存规则可以同时存在,强制缓存优先级高于协商缓存,也就是说,当执行强制缓存的规则时,如果缓存生效,直接使用缓存,不再执行协商缓存规则。
三、缓存常用字段
强制缓存方案:
1、Cache-Control 作为请求头字段
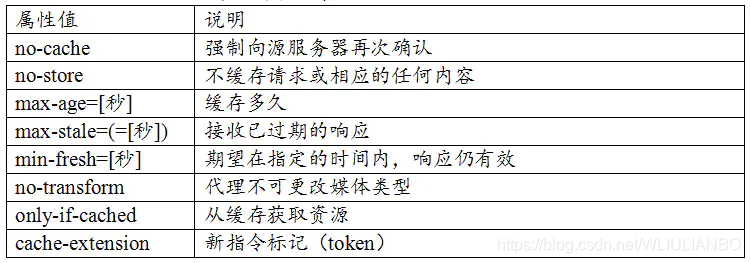
1.1 Cache-Control:no-cache
使用 no-cache 指令的目的是为了防止从缓存中返回过期的资源。客户端发送的请求中如果包含no-cache 指令,则表示客户端将不会接收缓存的资源,每次请求都是从服务器获取资源,返回304
1.2 Cache-Control: no-store
使用no-store指令表示请求的资源不会被缓存,下次任何其它请求获取该资源,还是会从服务器获取,返回200,即资源本身。
2、Cache-Control 作为响应头字段
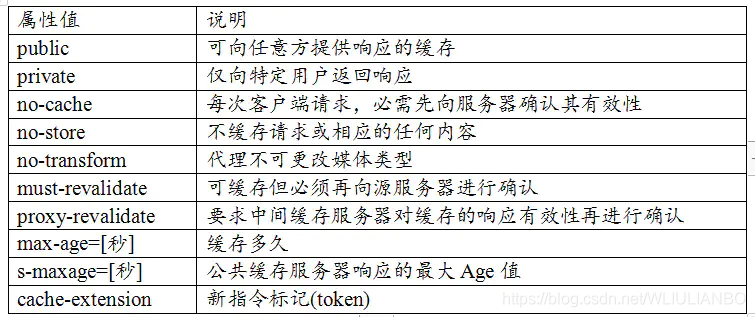
2.1 Cache-Control:public
当指定使用 public 指令时,则明确表明其他用户也可以利用缓存
2.2 Cache-Control:private
当指定 private 指令后,响应只以特定的用户作为对象,这与 public 指令的行为相反,缓存服务器会对该特定用户提供资源缓存的服务,对于其他用户发送过来的请求,代码服务器则不会返回缓存。
2.3 Cache-Control:no-cache
每次客户端请求,必须先向服务器确认其有效性,如果资源没有更改,则返回 304,
2.4 Cache-Control :no-store
不对响应的资源进行缓存,即用户下次请求还是返回200,返回资源本身
2.5 Cache-Control:max-age=60800(单位:秒)
资源缓存在本地浏览器的时间,如果超过该时间,则重新向服务器获取
协商缓存方案:
1、请求头部字段 & 响应头部字段
1.1 请求头部字段

1.2 响应头部字段

注意:If-None-Match 的优先级比 If-Modified-Since高,所以两者同时存在,遵从前者。
四、强缓存与协商缓存
缓存的优点:
1、减少了少必要的数据传输,节省带宽
2、减少服务器的负担,提升网站性能
3、加快了客户端加载网页的速度
4、用户体验友好
缓存的缺点:
1、资源如果有更改但是客户端不及时更新会造成用户获取信息滞后,如果老版本有BUG的话,情况会更坏,
所以为了避免设置缓存错误,掌握缓存的原理对于我们工作中去更加合理的配置缓存是非常重要的
强制缓存的总结:
1、cache-control:max-age=xxx,public
客户端和代理服务器都可以缓存该资源
客户端在xxx秒的有效期内,如果有请求该资源的需求的话就直接读取缓存,statu code:200,如果用户做了刷新操作,就向服务器发起http请求
2、cache-control:max-age=xxx,private
只让客户端可以缓存该资源,代理服务器不缓存
客户端在xxx秒内直接读取缓存,statu code:200
3、cache-control:max-age=xxx,immutable
客户端在xxx秒的有效期内,如果有请求该资源的需求的话就直接读取缓存,statu code = 200 即使用户做了刷新操作,也不会向服务器访问请求
4、cache-control:no-cache
路过设置强缓存,但是不妨碍设置协商缓存; 一般如果做了强缓存,只有在强缓存失效了才走协商缓存,设置了 no-cache 就不会走强缓存了,每次请求都会询问服务端
5、cache-control:no-store
不缓存,这个会让客户端、服务端都不缓存,也就是没有所谓的强缓存 、协商缓存了
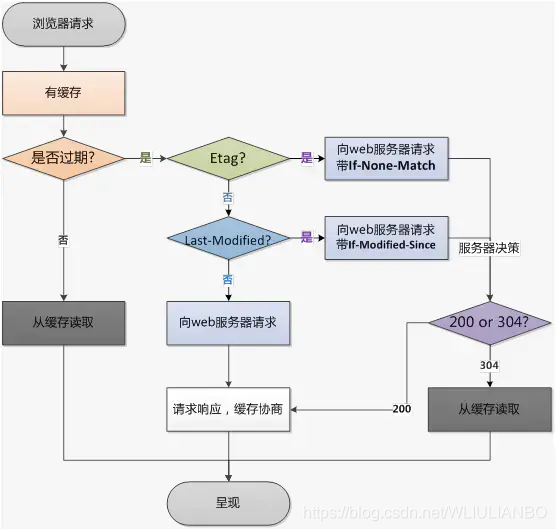
如何设置协商缓存:
1、responseHeader 里面的设置 etag:‘xxxxxx’ ; last-modified: time
etag:每个文件只有一个,改动了就变了,表示文件的hash,每个文件唯一
last-modified:文件的修改时间,精确到秒
也就是说,每次请求返回来 responseHeader 中的etag和 last-modified ,在下次请求时在 requestHeader 把这两个带上,服务端把你带过来的标识进行对比,然后判断资源是否更改了,如果更改了直接返回新的资源,和更新对应的 responseHeader 的标识 etag / last-modified,如果资源没有变,那就不变etag / last-modified ,这时候对客户端来说每单位名称请求都要进行协商缓存 ,请求流程如下:
发请求 > 看资源是否过期 > 过期 > 请求服务器 > 服务器对比资源是否真的过期 > 没过期 > 返回304状态码 > 客户端用缓存 的老资源
协商缓存步骤总结:
1、请求资源时,把用户本地该资源的etag同时带到服务端,服务端和最新资源做对比
2、如果资源没改,返回304,浏览器读取本地缓存
3、如果资源有改,返回200 , 返回最新的资源
注:responseHeader中的 etag/last-modified 在客户端重新向服务端发起请求时,会在 requestHeader中换个Key名:
etag --> if-noni-matched
last-modified —> if-modified-since
扩展:serviceWorker:浏览器背后的独立线程,一般可以用来实现缓存功能,使用serviceWorker必须用HTTPS,因为它涉及到请求拦截
五、总结
1、对于强制缓存,服务器通知浏览器一个缓存时间,下次请求直接用缓存,不在时间内,执行协商缓存策略
2、对于协商缓存,将缓存信息中的 Etag 和 Last-Modified 通过请求发送给服务器,由服务器校验 ,返回304状态,浏览器直接使用缓存
关于协议和规范
- 就是一个约定
- 要求大家都跟着执行
- 不要违反规范,例如 IE 浏览器
http methods
传统的 methods
- get 获取服务器的数据
- post 像服务器提交数据
- 简单的网页功能,就这两个操作
现在的 methods
- get 获取数据
- post 新建数据
- patch / put 更新数据
- delete 删除数据
Restful API
- 一种新的 API 设计方法(早已推广使用)
- 传统 API 设计, 把每个 url 当做一个功能
- Restful API 设计:把每个 url 当做一个唯一的资源
如何设计成一个资源
尽量不用 url 参数
- 传统 API 设计: /api/list?pageIndex=2
- Restful API 设计:/api/list/2
用 method 表示操作类型 - post 请求 /api/create-blog
- post 请求 /api/update-b;og?id=100
- post 请求 /api/get-blog?id=100