-
この記事では、MySQLとRedisのキャッシュを同期するための2つのソリューションを紹介します
-
解決策1:MySQL、MySQLトリガー+ UDF関数の実装を通じてRedisを自動的に更新する
-
解決策2:MySQLのbinlog実装を分析し、データベース内のデータをRedisに同期します
-
1.スキーム1(UDF)
-
シナリオ分析: MySQLデータベースでデータ操作を実行するときに、対応するデータをRedisに同時に同期します。Redisに同期した後、クエリ操作はRedisから検索されます。
-
プロセスはおおまかに次のとおりです。
-
MySQLで操作するデータのトリガートリガーを設定し、操作を監視します
-
クライアント(NodeServer)がMySQLにデータを書き込むと、トリガーがトリガーされます。トリガーの後、MySQLUDF関数が呼び出されます。
-
UDF関数は、同期の効果を実現するために、Redisにデータを書き込むことができます
-
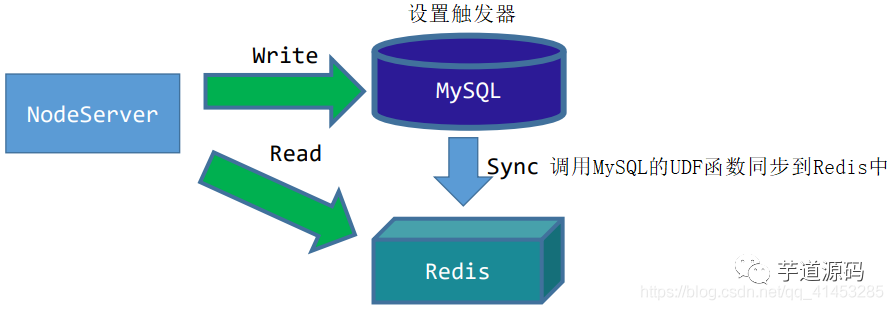
-
ケース分析:
-
このスキームは、読み取りが多く書き込みが少なく、同時書き込みがないシナリオに適しています。
-
MySQLトリガー自体が効率の低下を引き起こすため、テーブルが頻繁に操作される場合、このソリューションはそれが不適切であることを示しています
-
デモケース
以下はMySQLテーブルです
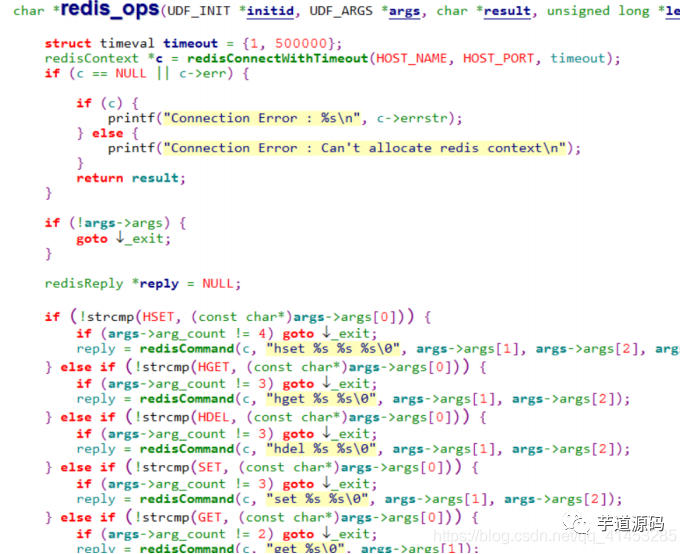
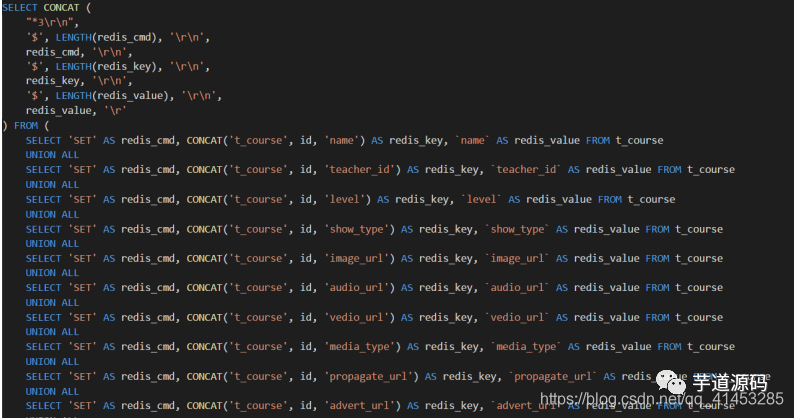
以下はUDFの解析コードです
対応するトリガーを定義する


2、プラン2(binlogの分析)
-
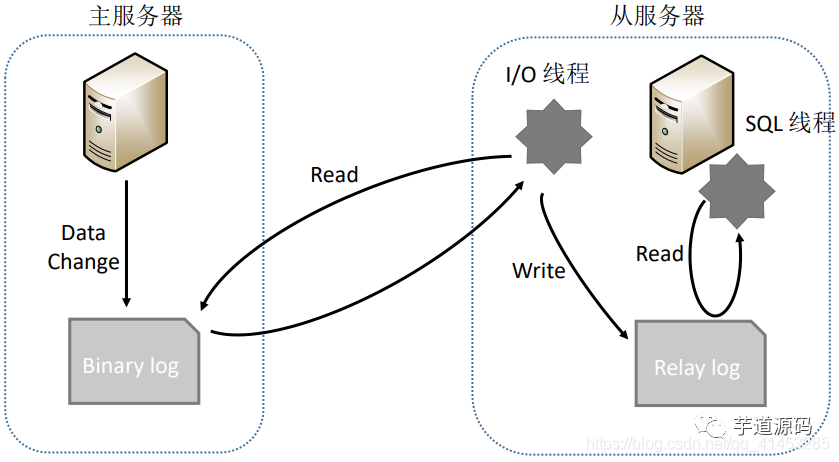
オプション2を導入する前に、次の図に示すように、まずMySQLレプリケーションの原則を紹介しましょう。
-
メインサーバーはデータを操作し、データをビンログに書き込みます
-
サーバーからI / Oスレッドを呼び出して、メインサーバーのBinログを読み取り、それを独自のリレーログに書き込みます。次に、SQLスレッドを呼び出して、リレーログからデータを解析し、独自のデータベースに同期します。
-
-
オプション2は次のとおりです。
-
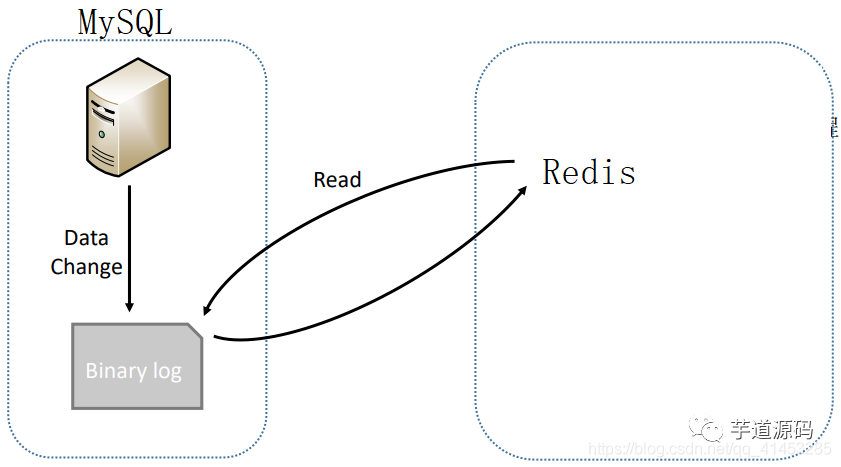
上記のMySQLのレプリケーションプロセス全体は、1つの文に要約できます。つまり、サーバーからメインサーバーのビンログのデータを読み取り、それを独自のデータベースに同期します。
-
同じことがソリューション2にも当てはまります。これは、概念的にマスターサーバーをMySQLに、スレーブサーバーをRedisに変更することです(下の図を参照)。MySQLに書き込むデータがある場合は、MySQLBinログを解析します。次に、同期の効果を実現するために、解析されたデータがRedisに書き込まれます。
-
-
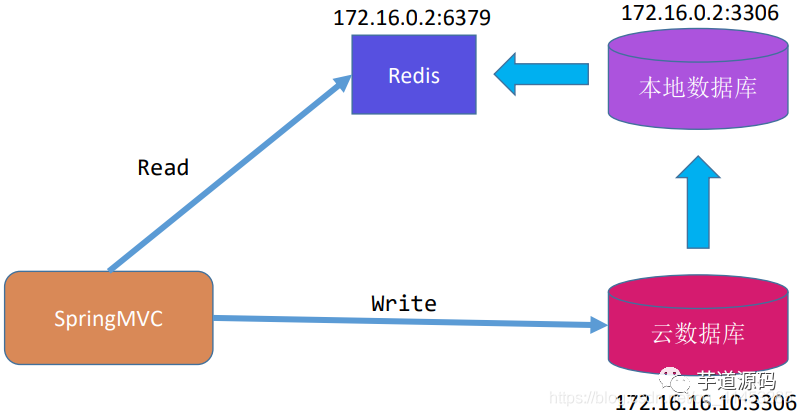
たとえば、以下はクラウドデータベースインスタンスの分析です。
-
クラウドデータベースは、ローカルデータベースとマスタースレーブ関係にあります。クラウドデータベースは書き込み用のメインデータベースとして機能し、ローカルデータベースはメインデータベースからデータを読み取るためのスレーブデータベースとして機能します。
-
ローカルデータベースがデータを読み取った後、Binログを解析し、データをRedisに書き込んで書き込み、クライアントがRedisからデータを読み取ります。
-
-
この技術的ソリューションの難しさは、 MySQLビンログを解析する方法にあります。ただし、これにはbinlogファイルとMySQLを非常に深く理解する必要があります。同時に、binlogには複数の形式のStatement / Row / Mixedlevelがあるため、同期を実現するためにbinlogを分析するワークロードは非常に大きくなります。
Canalオープンソーステクノロジー
Canalは、純粋なJavaで開発されたAlibabaのオープンソースプロジェクトです。データベースの増分ログ分析に基づいて、増分データのサブスクリプションと消費を提供します。現在、主にMySQLをサポートしています(mariaDBもサポートしています)。
オープンソースの参照アドレスは次のとおりです:https://github.com/liukelin/canal_mysql_nosql_sync
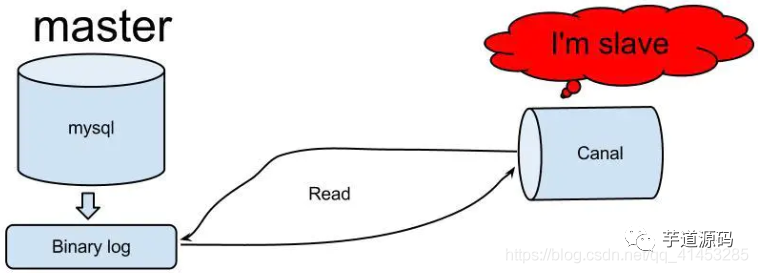
動作原理(MySQLレプリケーションを模倣):
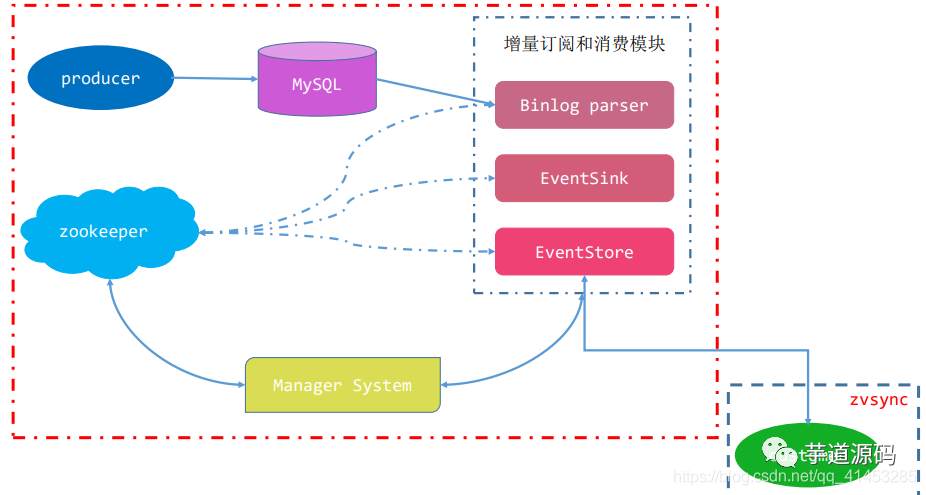
Canalは、mysqlスレーブの対話型プロトコルをシミュレートし、mysqlスレーブのふりをして、ダンププロトコルをmysqlマスターに送信します。
mysqlマスターはダンプ要求を受信し、バイナリログをスレーブ(つまり、運河)にプッシュし始めます。
Canalはバイナリログオブジェクト(元のバイトストリーム)を解析します
建築:
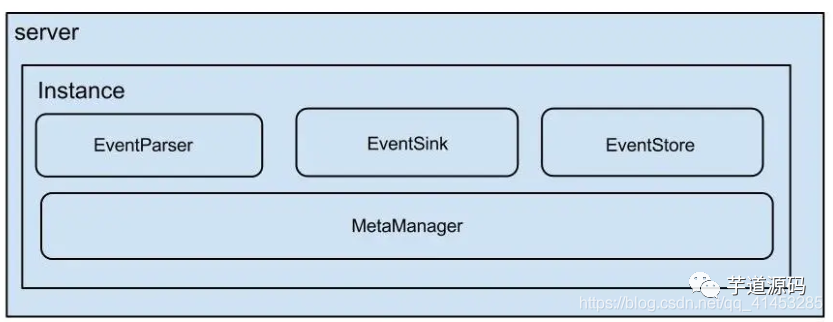
eventParser(データソースアクセス、シミュレートされたスレーブプロトコルとマスターの相互作用、プロトコル分析)
eventSink(パーサーおよびストアリンカー、データフィルタリング、処理、および配布作業)
eventStore(データストレージ)
metaManager(インクリメンタルサブスクリプションおよびコンシューマーインフォメーションマネージャー)
サーバーは、jvmに対応する運河の実行中のインスタンスを表します
インスタンスはデータキューに対応します(1つのサーバーは1..nインスタンスに対応します)
インスタンスモジュール:
一般的な分析プロセスは次のとおりです。
parseはMySQLBinログを解析し、データをシンクに入れます
シンクフィルター、処理、およびデータの配布
ストアは、解析されたデータをシンクから読み取り、保存します
次に、デザインコードを使用して、ストア内のデータをRedisに同期的に書き込みます。
その中で、解析/シンクはフレームワークによってカプセル化されています。私たちが行うのは、ストアデータを読み取るステップです。
Canclの詳細はBaiduで検索できます
以下は、実行中のトポロジ図です。
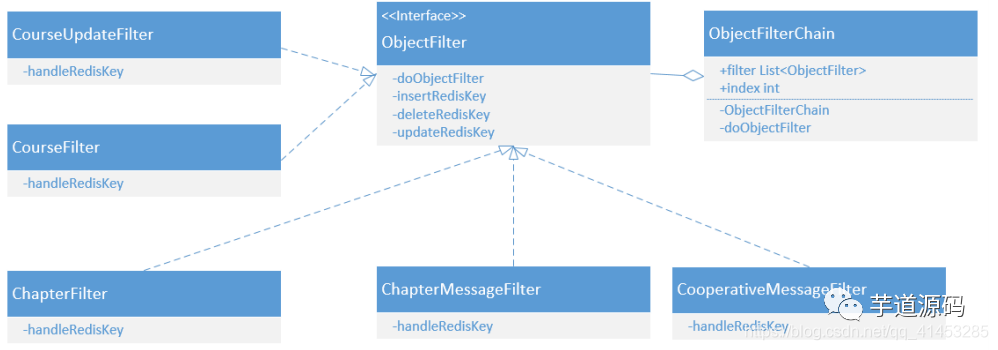
MySQLテーブルの同期は、Chain of Responsibilityモードを採用し、各テーブルはFilterに対応します 。たとえば、zvsyncで使用されるクラスは次のように設計されています。
以下は、マテリアライズドzvsyncで使用されるクラスです 。テーブルが追加または削除されるたびに、直接追加および削除するだけです。
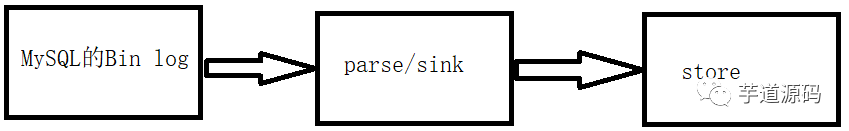

3、追加
-
この記事の上記のすべては、MySQLからキャッシュに同期されます。
しかし、実際の開発では、誰かが次のスキームを使用する可能性があります。
-
クライアントがデータを取得したら、最初にそれをRedisに保存してから、MySQLに同期します
-
このスキーム自体も安全ではない/信頼性が低いため、Redisに短期間のダウンタイムや障害が発生すると、データが失われます
-
