RCU(Read-Copy Update)は、Linuxの重要な同期メカニズムです。名前が示すように、それは「読み取り、コピー、更新」であり、鈍点は「自由に読み取る」ですが、データを更新するときは、最初にコピーを作成し、コピーの変更を完了してから、古いものを置き換える必要がありますデータを一度に。」これは、共有データを「読み取りと書き込みを減らす」ためにLinuxカーネルによって実装される同期メカニズムです。
他の同期メカニズムとは異なり、複数のリーダーが同時に共有データにアクセスでき、リーダーのパフォーマンスに影響を与えることはなく(「自由に読み取る」)、リーダーとライター間の同期メカニズムは必要ありません(ただし、 「コピー後に再度コピーする」必要があります。書き込み」)が、複数のライターがある場合、ライターが更新された「コピー」を元のデータに上書きする場合、ライターとライターは他の同期メカニズムを使用して同期を確保する必要があります。 。
RCUの典型的なアプリケーションシナリオはリンクリストです。ヘッダーファイル(include / linux / rculist.h)はLinuxカーネルで提供され、RCUメカニズムを使用してリンクリストを追加、削除、チェック、および変更するためのインターフェイスを提供します。この記事では、rculist.hが提供するインターフェースを使用して、リンクリストを追加、削除、チェック、変更してRCUの原理を説明し、Linuxカーネルに関連するAPIを導入する例を使用します(Linux v3のソースコードに基づく)。 .4.0)。
リストアイテムを追加
LinuxカーネルでRCUを使用してリンクリストにアイテムを追加するためのソースコードは次のとおりです。
#define list_next_rcu(list) (*((struct list_head __rcu **)(&(list)->next)))
static inline void __list_add_rcu(struct list_head *new,
struct list_head *prev, struct list_head *next)
{
new->next = next;
new->prev = prev;
rcu_assign_pointer(list_next_rcu(prev), new);
next->prev = new;
}list_next_rcu()関数のrcuは、コード分析ツールSparseで使用されるコンパイルオプションです。rcuタグ付きのポインターは直接使用できないことが規定されており、以前にRCUで保護されたポインターを返すにはrcu_dereference()を使用する必要があります。使用できます。rcu_dereference()インターフェースの関連知識は後で紹介されます。このセクションでは、rcu_assign_pointer()インターフェースに焦点を当てます。まず、rcu_assign_pointer()のソースコードを見てください。
#define __rcu_assign_pointer(p, v, space) \
({ \
smp_wmb(); \
(p) = (typeof(*v) __force space *)(v); \
})上記のコードの最終的な効果は、vの値をpに割り当てることです。重要なポイントは、3行目のメモリバリアです。メモリバリア(メモリバリア)とは何ですか?CPUがパイプラインテクノロジを使用して命令を実行する場合、2番目の命令がアクセスするポインタpが指すメモリはに依存するため、p = v; a = * p;などのメモリ依存関係を持つ命令の実行順序のみを保証します。最初の命令。したがって、CPUは、2番目の命令が実行される前に最初の命令が実行されることを保証します。ただし、上記の__list_add_rcu()インターフェイスなど、メモリに依存しない命令の場合、8行目がprev-> next = new;と記述されていると、この割り当て操作には新しいポインタが指すメモリへのアクセスが含まれないため、次のようになります。 6、7行目のnew-> nextおよびnew-> prevの割り当てに依存しないでください。CPUは、prev-> next = new;を実行してから、new-> prev = prev;を実行する場合があります。これにより、Newが発生します。初期化が完了する前に、ポインタ(つまり、新しく追加されたリンクリストアイテム)がリンクリストに追加されます。この時点で、リーダーが新しいリンクリストアイテムをトラバースしてアクセスした場合(RCUの重要な機能は、自由に読むことができます操作)、初期化されていないリンクリスト項目にアクセスします!この問題は、メモリバリアを設定することで解決できます。これにより、メモリバリアの前の命令が、メモリバリアの後の命令の前に実行されるようになります。これにより、リンクリストに追加されたアイテムが初期化されている必要があります。
最後に、リンクリストアイテムを追加する操作を同時に実行するスレッドが複数ある場合は、リンクリストアイテムを追加する操作を他の同期メカニズム(など)で保護する必要があることに注意してください。 spin_lockなど)。
Linuxカーネル開発関連の学習ビデオ資料をクリックしてください:取得する学習資料
アクセスリストアイテム
LinuxカーネルでRCUリンクリストアイテムにアクセスするための一般的なコードパターンは次のとおりです。
rcu_read_lock();
list_for_each_entry_rcu(pos, head, member) {
// do something with `pos`
}
rcu_read_unlock();ここで説明するrcu_read_lock()とrcu_read_unlock()は、RCUの「自由に読み取る」ための鍵です。これらの効果は、読み取り側のクリティカルセクションを宣言することです。読み取り終了のクリティカルセクションについて説明する前に、リンクリスト項目を読み取るマクロ関数list_for_each_entry_rcuを見てみましょう。ソースコードに戻って、リンクリストアイテムへのポインタを取得すると、主にrcu_dereference()という名前のマクロ関数が呼び出されます。このマクロ関数の主な実装は次のとおりです。
#define __rcu_dereference_check(p, c, space) \
({ \
typeof(*p) *_________p1 = (typeof(*p)*__force )ACCESS_ONCE(p); \
rcu_lockdep_assert(c, "suspicious rcu_dereference_check()" \
" usage"); \
rcu_dereference_sparse(p, space); \
smp_read_barrier_depends(); \
((typeof(*p) __force __kernel *)(_________p1)); \
})
第 3 行:声明指针 _p1 = p;
第 7 行:smp_read_barrier_depends();
第 8 行:返回 _p1;上記の2つのコードは、実際にはそのようなパターンと見なすことができます。
rcu_read_lock();
p1 = rcu_dereference(p);
if (p1 != NULL) {
// do something with p1, such as:
printk("%d\n", p1->field);
}
rcu_read_unlock();rcu_dereference()の実装によると、最終的な効果は、あるポインターを別のポインターに割り当てることです。上記の2行目のrcu_dereference()がp1 = pとして直接記述されている場合はどうなりますか?一般的なプロセッサアーキテクチャでは、まったく問題はありません。ただし、アルファ版では、コンパイラの値推測最適化オプションはp1の値を「推測」し、命令を再配置して最初に値p1-> field〜を取得すると言われます。したがって、Linuxカーネルでは、smp_read_barrier_depends()の実装Arm、x86、およびその他のアーキテクチャは空の実装であり、メモリバリアがアルファに追加されて、pの実際のアドレスが最初に取得され、次に逆参照されるようにします。したがって、前のセクション「リンクリストアイテムの追加」で説明した「__rcu」コンパイルオプションは、rcu_dereference()がRCUで保護されたデータへのアクセスに使用されているかどうかを強制的にチェックします。これにより、実際にはコードの移植性が向上します。
ここで、読み取り側のクリティカルセクションの問題に戻ります。複数のリードエンドクリティカルセクションは相互に排他的ではありません。つまり、複数のリーダーを同時にリードエンドクリティカルセクションに含めることができますが、メモリデータの一部をリードエンドクリティカルセクションのポインタで参照できるようになると、このメモリブロックデータのリリースは、読み取りまで待機する必要があります。エンドクリティカルセクションが終了すると、読み取りエンドクリティカルセクションの終了を待機しているLinuxカーネルAPIはsynchronize_rcu()です。読み取り端のクリティカルセクションのチェックはグローバルです。システム内のコードが読み取り端のクリティカルセクションにある場合、synchronize_rcu()はブロックされ、読み取り端のすべてのクリティカルセクションが終了しました。この問題を直感的に理解するために、次のコード例を示します。
/* `p` 指向一块受 RCU 保护的共享数据 */
/* reader */
rcu_read_lock();
p1 = rcu_dereference(p);
if (p1 != NULL) {
printk("%d\n", p1->field);
}
rcu_read_unlock();
/* free the memory */
p2 = p;
if (p2 != NULL) {
p = NULL;
synchronize_rcu();
kfree(p2);
}次の図を使用して、複数のリーダーとメモリ解放スレッドの間のタイミング関係を示します。
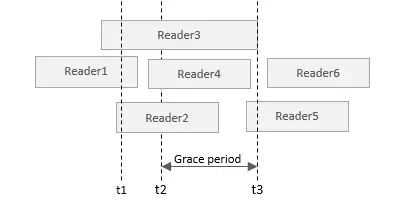
上の図では、各リーダーの2乗は、pの参照(5行目のコード)を取得してから読み取り終了のクリティカルセクションの終わりまでの期間を表します。t1はp = NULLのときの時間を表し、t2は時間を表します。 synchronize_rcu()呼び出しが開始されたとき。t3は、synchronize_rcu()によって返される時間を表します。最初にリーダー1、2、および3を見てみましょう。これら3つのリーダーの終了時間は異なりますが、すべてt1より前のpアドレスへの参照を取得します。Synchronize_rcu()はt2で呼び出されます。この時点で、Reader1のクリティカルセクションは終了していますが、Reader2とReader 3はまだ読み取り終了のクリティカルセクションにあるため、Reader2と3のクリティカルセクションが終了するまで待つ必要があります。つまり、t3、t3の後で、kfree(p2)を実行してメモリを解放できます。synchronize_rcu()がブロックされるこの期間には、猶予期間と呼ばれる名前があります。また、リーダー4、5、6は、猶予期間との時間関係に関係なく、参照を取得する時間はt1以降であるため、pポインターの参照を取得できず、p1の分岐に入りません。 = NULL。
リストアイテムを削除する
前述の猶予期間を知っていると、リンクリストアイテムの削除を理解するのは簡単です。一般的なコードパターンは次のとおりです。
p = seach_the_entry_to_delete();
list_del_rcu(p->list);
synchronize_rcu();
kfree(p);
其中 list_del_rcu() 的源码如下,把某一项移出链表:
/* list.h */
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
/* rculist.h */
static inline void list_del_rcu(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->prev = LIST_POISON2;
}前のセクションの「リンクリストアイテムへのアクセス」の例によると、読者がリンクリストから削除しようとしているリンクリストアイテムを取得できる場合、彼はsynchronize_rcu(の前に読み取り終了のクリティカルエリアに入る必要があります)、およびsynchronize_rcu()は、読み取り終了を保証します。クリティカルセクションが終了すると、リンクリストアイテムのメモリが解放され、リーダーがアクセスしているリンクリストアイテムは解放されません。
リストアイテムを更新する
前述のように、RCUの更新メカニズムは「コピー更新」であり、RCUリンクリストアイテムの更新もこのメカニズムです。一般的なコードパターンは次のとおりです。
p = search_the_entry_to_update();
q = kmalloc(sizeof(*p), GFP_KERNEL);
*q = *p;
q->field = new_value;
list_replace_rcu(&p->list, &q->list);
synchronize_rcu();
kfree(p);3行目と4行目は、コピーを作成し、コピーの更新を完了してから、list_replace_rcu()を呼び出して、古いノードを新しいノードに置き換えます。ソースコードは次のとおりです
。3行目と4行目はコピーを作成し、コピーの更新を完了してから、list_replace_rcu()を呼び出して古いノードを新しいノードに置き換え、最後に古いノードのメモリを解放します。list_replace_rcu()のソースコードは次のとおりです。
static inline void list_replace_rcu(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->prev = old->prev;
rcu_assign_pointer(list_next_rcu(new->prev), new);
new->next->prev = new;
old->prev = LIST_POISON2;
}Linuxカーネル開発関連の学習ビデオ資料をクリックしてください:取得する学習資料
Linuxカーネルの体系的な研究の概要、マインドマッピングの取得をクリックします