TfidfVectorizer
効果
テキストをベクトル化します。
原理
ここで、tf(用語頻度)は単語の頻度であり、idf(逆文書頻度)は単語の逆文書頻度です。
次のようなドキュメントのコレクションがあるとします。
train = ["Chinese Beijing Chinese","Chinese Chinese Shanghai","Chinese Macao","Tokyo Japan Chinese"]
リストの各要素はドキュメントであるため、上記には合計4つのドキュメントがあります。最初の文書は「ChineseBeijingChinese」です。
では、これらのドキュメントをどのようにベクトルに変換するのでしょうか。
古い方法では、最初にすべてのドキュメントの語彙をカウントします。全部で6つの単語があります{「中国語」、「北京」、「上海」、「マカオ」、「東京」、「日本」}。
次に、6次元のベクトルを使用して各ドキュメントを表しますが、問題は、各次元のベクトルにいくつの数字を入力する必要があるかということです。
最初の方法で
は、ワンホットエンコーディングを使用できます。最初のドキュメントには{"Chinese"、 "Shanghai"}しかないため、2番目のドキュメントは(1,0,1,0,0,0)としてエンコードされます。二つの単語。
2番目の方法
方法1は0または1のいずれかであることがわかりました。改善できますか?このベクトルがより多くの情報を表すようにしますか?使用できますtf-idf。最初
にidfの式を見てみましょう:
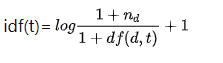
最初のドキュメントを例として取り上げます(「ChineseBeijingChinese」)。
tf計算は非常に簡単で、ラインの数、tf("Chinese")=2、tf("Beijing")=1。英語は頻度ですが、私の前の単語は単語の頻度であることがわかります。idfの計算は少し複雑です。ドキュメント全体を表示して計算する必要があります。idf("Chinese")最初に、ドキュメントコレクション全体に「Chinese」が表示される回数を数えます。4つのドキュメントに「Chinese」、つまりdf(d、 "C hinese")=が含まれていることがわかります。 4 df(d、 "Chinese")= 4d f (d 、" C h i n e s e " )=4、およびnd n_dnDドキュメントセット内のドキュメントの数を示します。したがって、nd = 4 n_d = 4nD=4。上記の2つをidf数式に取り入れますidf("Chinese")=log(5/5)+1=0+1=1。はい。同様にidf("Beijing")=log(5/2)+1=1.916290731874155、ここでの対数はeeに基づいていることに注意してくださいeは一番下です。- 最後に、式tfidf(t)= tf(t)∗ idf(t)tfidf(t)= tf(t)* idf(t)を使用します。t f i d f (t )=t f (t )∗I D F (T )が得られた
tfidf("Chinese")=2*1=2、tfidf("Beijing")=1*1.916290731874155=1.916290731874155。最後に、最初のドキュメント(2、1.916290731874155、0、0、0、0)のベクトル化された表現が取得されます。もちろん、標準化された表現を標準化することもできます。つまり、v ′= v ∣ ∣ v ∣ ∣ 2 v' = \ frac {v} {|| v || _2}v′=∣ ∣ v ∣ ∣2v、または正規化と呼ばれます。になる:(0.722056、0.691834610、0、0、0、)
sklearn検証に使用します
from sklearn.feature_extraction.text import TfidfVectorizer
#训练数据
train = ["Chinese Beijing Chinese","Chinese Chinese Shanghai","Chinese Macao","Tokyo Japan Chinese"]
#将训练数据转化为向量。
tv=TfidfVectorizer()#初始化一个空的tv。
tv_fit=tv.fit_transform(train)#用训练数据充实tv,也充实了tv_fit。
print("fit后,所有的词汇如下:")
print(tv.get_feature_names())
print("fit后,训练数据的向量化表示为:")
print(tv_fit.toarray())
結果は次のとおりです。
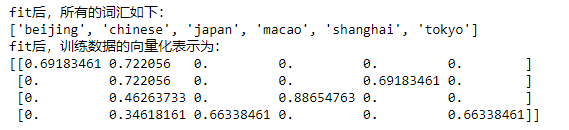
これは計算したものと同じです(ここでの語彙は辞書式順序で配置されているため、最初の語彙は「北京」であるため、チェックインする必要があります)。
直後、濃縮されtvた後。テストドキュメントをベクトル表現に変換するにはどうすればよいですか?transform機能を使用する
test=["Chinese Beijing shanghai"]
tv_test=tv.transform(test)#测试数据不会充实或者改变tv,但这步充实了tv_test。
print("所有的词汇如下:")
print(tv.get_feature_names())
print("测试数据的向量化表示为:")
print(tv_test.toarray())
結果は次のとおりです。

ここでも、テストデータは影響を受けません。tvつまり、トレーニング中に設定された元のドキュメントは4ドキュメントでありidf、計算時にndn_dになります。nD5つのドキュメントではなく4つのドキュメントのままです。同様idfに、式に含まれているのは、そのdf(d,t)単語tが含まれている元の4つのドキュメントの数を調べることです。
終わり
最後に、取得したベクトルを使用して、分类ドキュメント間の類似性を実行または計算できます(たとえば、コサイン類似性を使用)聚类。
補足
TfidfVectorizerには、次のようないくつかのパラメーターを使用できます。
(1)
stop_words
これはストップワードであり、ストップワードとは、中国語の{"的"、 "地"}など、無関係な単語を意味します。ストップワードのライブラリを提供するtvと、tvこれらのストップワードはドキュメント内で自動的に無視されます。これは、ドキュメントの前処理と同等であり、これらのドキュメント内のすべてのストップワードが削除されます。
from sklearn.feature_extraction.text import TfidfVectorizer
#训练数据
train = ["Chinese Beijing Chinese","Chinese Chinese Shanghai","Chinese Macao","Tokyo Japan Chinese"]
#将训练数据转化为向量。
tv=TfidfVectorizer(stop_words=["chinese"])#停用词注意要用小写,因为train会被自动转成小写。
tv_fit=tv.fit_transform(train)#用训练数据充实tv,也充实了tv_fit。
print("fit后,所有的词汇如下:")
print(tv.get_feature_names())
結果:

「中国語」というストップワードはなく、語彙が1つ少なくなります。
別の値(「英語」として直接指定)を見てみましょう。
stop_words="english"
これは、sklearnには、「the」など、誰もが一般的に同意する英語の停止語彙があることを意味します。これは中国語ではなくsklearnに組み込まれていることに注意してください。
from sklearn.feature_extraction.text import TfidfVectorizer
#训练数据
train = ["the Chinese Beijing Chinese","Chinese Chinese Shanghai","Chinese Macao","Tokyo Japan Chinese"]
#将训练数据转化为向量。
tv=TfidfVectorizer(stop_words="english")#初始化一个空的tv。
tv_fit=tv.fit_transform(train)#用训练数据充实tv,也充实了tv_fit。
print("fit后,所有的词汇如下:")
print(tv.get_feature_names())

「the」はストップワードとして自動的に削除されることがわかりました。
(二)
ngram_range
理解するために直接例を挙げてください。
from sklearn.feature_extraction.text import TfidfVectorizer
#训练数据
train = ["Chinese Beijing Chinese","Chinese Chinese Shanghai","Chinese Macao","Tokyo Japan Chinese"]
#将训练数据转化为向量。
tv=TfidfVectorizer(ngram_range=(1,2))#初始化一个空的tv。
tv_fit=tv.fit_transform(train)#用训练数据充实tv,也充实了tv_fit。
print("fit后,所有的词汇如下:")
print(tv.get_feature_names())
結果:

以前よりも語彙が増え、2つの単語の組み合わせが1つの語彙と見なされるようになりました。これは、自然言語処理のバイナリフレーズです。ここで、このパラメータは、1グラムのフレーズ(単語)と2グラムのフレーズの両方が総語彙の1項目と見なされることを意味します。
同様に、次のようにパラメータを自由に変更できます。
ngram_range=(2,2)#表示只要2元短语作为词汇表项。
(三)
max_df=0.9, min_df=2#如果是整数,那么就是含有该词的绝对文档数,如果是小数,就是含有该词的文档比例。
このdfを覚えておく必要がありますか?これはドキュメントの頻度ですが、逆数(逆数)ではないことに注意してください。たとえば、上記の4つのドキュメントの1つに「上海」が表示されている場合、その頻度は0.25です。
このパラメーターの意味は、ドキュメントの90%以上に表示される単語を削除し、少なくとも2つのドキュメントに表示されない単語も削除することです。
といった:
from sklearn.feature_extraction.text import TfidfVectorizer
#训练数据
train = ["Chinese Beijing Chinese","Chinese Chinese Shanghai","Chinese Macao","Tokyo Japan Chinese"]
#将训练数据转化为向量。
tv=TfidfVectorizer(max_df=0.9,min_df=0.25)#初始化一个空的tv。
tv_fit=tv.fit_transform(train)#用训练数据充实tv,也充实了tv_fit。
print("fit后,所有的词汇如下:")
print(tv.get_feature_names())
結果:

ドキュメントの頻度が高いため、「中国語」がないことがわかりましたdf(d,"Chinese")=4/4=1>0.9。これはストップワードと同等であり、無視されます。