WeChatパブリックアカウントの画像クロール
友人から「隣に犬がいる」という公式アカウントの写真を這うことができるかと聞かれ、すべての歴史記事の写真が欲しかった。私は公式アカウントに登っていませんが、少し分析した後でも、それでも友達のニーズを満たすことができると思います。ナンセンスな話をしないで、手を汚してください!
1.準備:
「PC版のWeChat」を開き、公式アカウントを見つけて
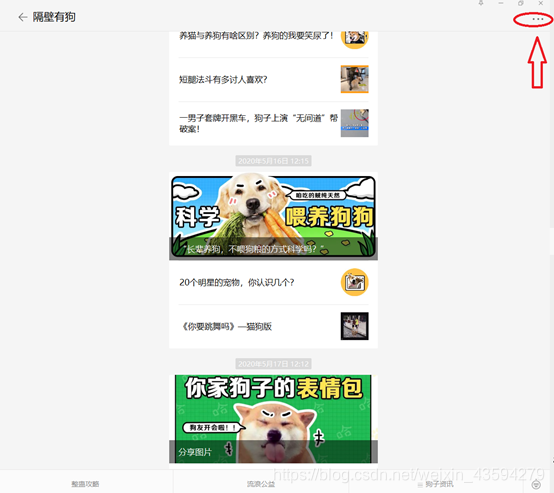
右上隅をクリックし、「履歴の表示」オプションをクリックします。もちろん、この方法以外にもありますが、効果は次のページが表示される必要があります。
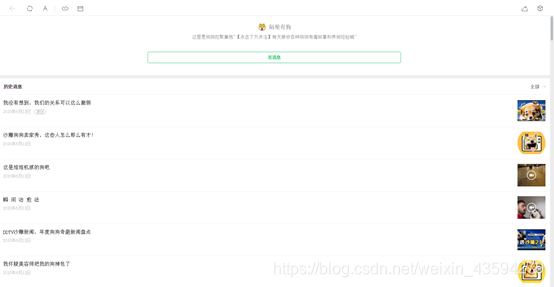
右クリックして空白の場所に移動すると、「ソースコードを表示」するオプションが表示されます。クリックすると、このページの下にあるソースコードであるtxt形式のテキストが自動的にポップアップ表示されます。現在のページで過去の記事のタイトルをコピーし、それをtxtファイルで検索すると、それが見つかることがわかります。また、これらの記事へのリンクもソースコードに含まれていることがわかります。
ただし、実際にはここに罠があります。つまり、ここに表示されるソースコードはすべての歴史的記事ではなく、最初に見た歴史的記事だけです。何も考えずに、このページのスクロールホイールを一番下に引っ張りました。これは、この公式アカウントによって公開された最初の記事の位置です。

次に、下部の空白を右クリックして「ソースコードを表示」すると、今回開いたtxtのコンテンツが前回よりも明らかに多いことに驚かれることでしょう。txtに最初と最後の記事のタイトルを入力してください検索ボックスと一致が成功した後、自信を持ってソースコードをローカルにコピーし、準備が完了しました。
PS:このページの記事をクリックするだけではいけません。クリックしないと、スクロールホイールをもう一度ドラッグする必要があります。
2.ソースコードを分析する:
最初の過去の記事を例にとると、「リンクアドレスのコピー」と「デフォルトのブラウザで開く」をクリックして取得したリンクアドレスは同じですが、ソースコードに見つかりません。可能性は1つだけです。つまり、この記事へのリンクが複数あります。
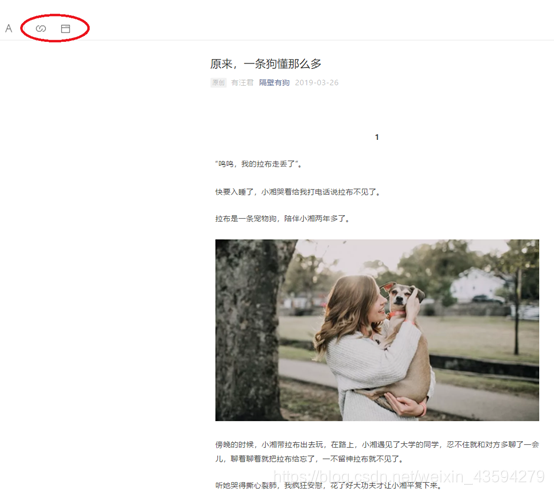
記事名でリンクを探すだけです。名前はソースコードにあるので、リンクがないのは少し無理です。ソースコードで記事の名前を見つけてください。結果は図に示されています。明らかに、hrefsは必要なリンクです。それを開いた後、それが可能であることがわかりました。フレームワークはまだ非常に明確であることがわかります。
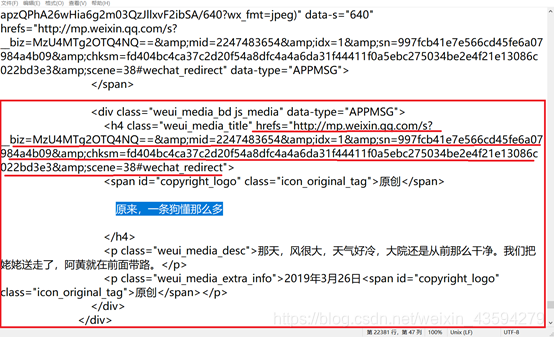
次のステップはウェブページの分析です。F12で要素を確認して右クリックすると、ウェブページのソースコードが表示されます。完全に検索して検索したところ、画像へのリンクがソースにあることがわかりました。 Webページのコード。これにより、パケットをキャプチャしてWebページを直接分析する必要がなくなります。ソースコードは問題ありません。
3.クローラーの作成:
私の個人的な習慣は、2つのpyファイルを作成することです。そのうちの1つはtest.pyという名前で、公式のクローラーで作成されたコードの正確さをテストするために使用されます。クローラーを作成するプロセスは、一般的に遠回りです。モジュール変更されたプログラミングにより、ブロックを作成するのが楽しくなります。コードに直接移動してください!
import requests #请求网页
import os #用于创建文件夹
from lxml import etree #使用其中的xpath
def start():
#第一层,获取公众号全部文章的链接
filename=’source.txt’#之前存在本地的公众号源代码
with open(filename,'r',encoding='utf-8')as f:
source=f.read() #读取内容
html_ele=etree.HTML(source) #xpath常规操作
hrefs=html_ele.xpath('//div[contains(@data-type,"APPMSG")]/h4/@hrefs') #锁定元素位置
num=0
for i in hrefs:
num+=1
try:
apply_one(i)
except:
continue
print('第%d篇爬取完毕'%num)
#第二层,解析单篇文章
def apply_one(url):
headers={
#可以用自己浏览器的User-Agent,也可以用fake-useragent库函数生成
}
#ps:fake-useragent举例
#pip install fake-useragent
#from fake_useragent import UserAgent
#ua = UserAgent()
#print(ua.random)
response=requests.get(url,headers=headers)
elements=etree.HTML(response.text)
data_src=elements.xpath('//section[contains(@style,"text-align")]/section/img/@data-src')
#print(len(data_src))
data_src=data_src[2:-1]
#print(len(data_src))
for src in data_src:
try:
download(src) #下载图片
except:
continue
#第三层下载层
def download(src):
headers={
'User-Agent': #自行添加}
response=requests.get(src,headers=headers)
name=src.split('/')[-2] #截取文件名
#print(name)
dtype=src.split('=')[-1] #截取图片类型
name+='.'+dtype #重构图片名
os.makedirs('doge',exist_ok=True) #当前目录生成doge文件夹
with open('doge/'+name,'wb')as f:
f.write(response.content)
if __name__=='__main__':
start()
4.まとめ:
多くの同様のクローラーのコンパイルは、ポイントからサーフェスへのプロセスです。最初にブレークスルーを作成し、次にサーフェスから内部へ、浅いものから深いものへと、サーフェスを繰り返しプロモートしてカバーします。爬虫類の学習には多くの時間とエネルギーが必要です。あきらめたいときは、もう一度歯を食いしばってください。その忍耐力と気質の痕跡で、私は困難を乗り越えることができると信じています。学習プロセスは閉じられておらず、優秀な人ともっとコミュニケーションをとることはできますが、それでも自分で問題を解決することを提唱しています。自分だけが本当に自分を救うことができるので、助けを求める方法は本当にありません。そこから何かを学べることを願っています。ひどく書いたらご容赦ください!