PythonJSリバースエンジニアリングノックレベルの百度翻訳のケース
後で、JSリバースエンジニアリングについて学ぶ必要があるかもしれません。時間があれば、暗号化されたWebサイトにJSリバースエンジニアリングを実装する方法をお送りします。私と一緒に進歩しましょう。
JSリバースエンジニアリングとは何かを知らない方もいらっしゃると思いますが、簡単に説明します。この言葉を初めて聞いたときは、難しいかどうかにかかわらず、とても背が高いと感じるかもしれませんが、スキルを習得した後は難しくないというのが私の答えです。ウェブサイトのクローラー分析の過程で、ウェブサイトの応答から直接取得できないデータもあります。ウェブサイトにアクセスするためのパラメータを構築するには、相手のサーバーにリクエストを送信してから、ウェブサイトをシミュレートします。 JSリバースエンジニアリングでは、多くのパラメーターがWebサイトのバックエンドでJavaScriptによって生成されます。私たちがしなければならないのは、バックエンドパラメーター生成の原理を見つけることです。
理解できるかどうかにかかわらず、以下の分析を見てみましょう。実際の戦闘で知識を学ぶことが最も効率的です。
1.分析リンク
1.日常業務の波である百度翻訳のWebサイトにアクセスします。F12を押し、「XHR」を選択し、翻訳ボックスにテキストを入力して、キャプチャされたパッケージへのリンクを確認します。

赤いボックスがこの分析の最終的な目標であることがわかります。このパラメータリストを作成してから、投稿して対応するリンクにアクセスしてください。
現在、復号化する必要のあるパラメーターは符号とトークンのようですが、実際には符号は1つしかありません。
次に、翻訳ボックスにテキストを入力すると、トークンの値が変更されていないことがわかります。その後のJSスクリプトの分析により、これが確認されます。トークンは定数です。
2.「sign」パラメータを含むリンクフラグメントを直接検索して、生成メカニズムのコードを見つけます。ここにサイトフラグメントがあるのはなぜですか?一般に、スクリプトの構造は、サイト名が関数名と変数名の前にあるというものです。符号は変数です。サイトフラグメントを取得すると、符号の位置を簡単に見つけることができます。
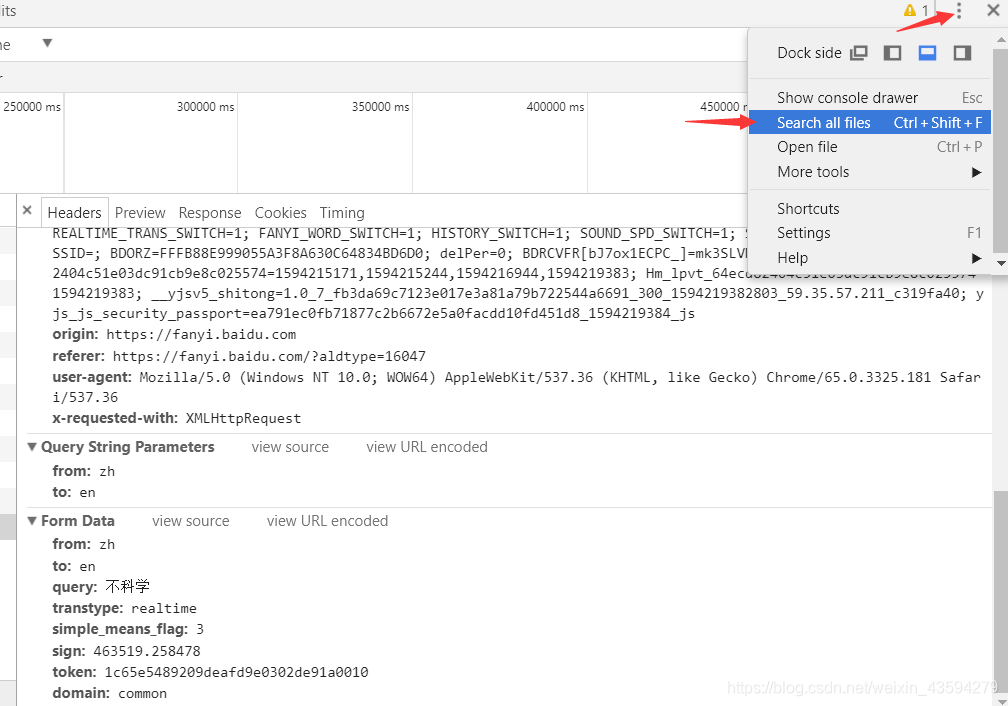

検索したところ、選択肢が1つしかないことがわかりました。スクリプトを直接クリックし、見にくいコードをフォーマットして、[{}]を押します。
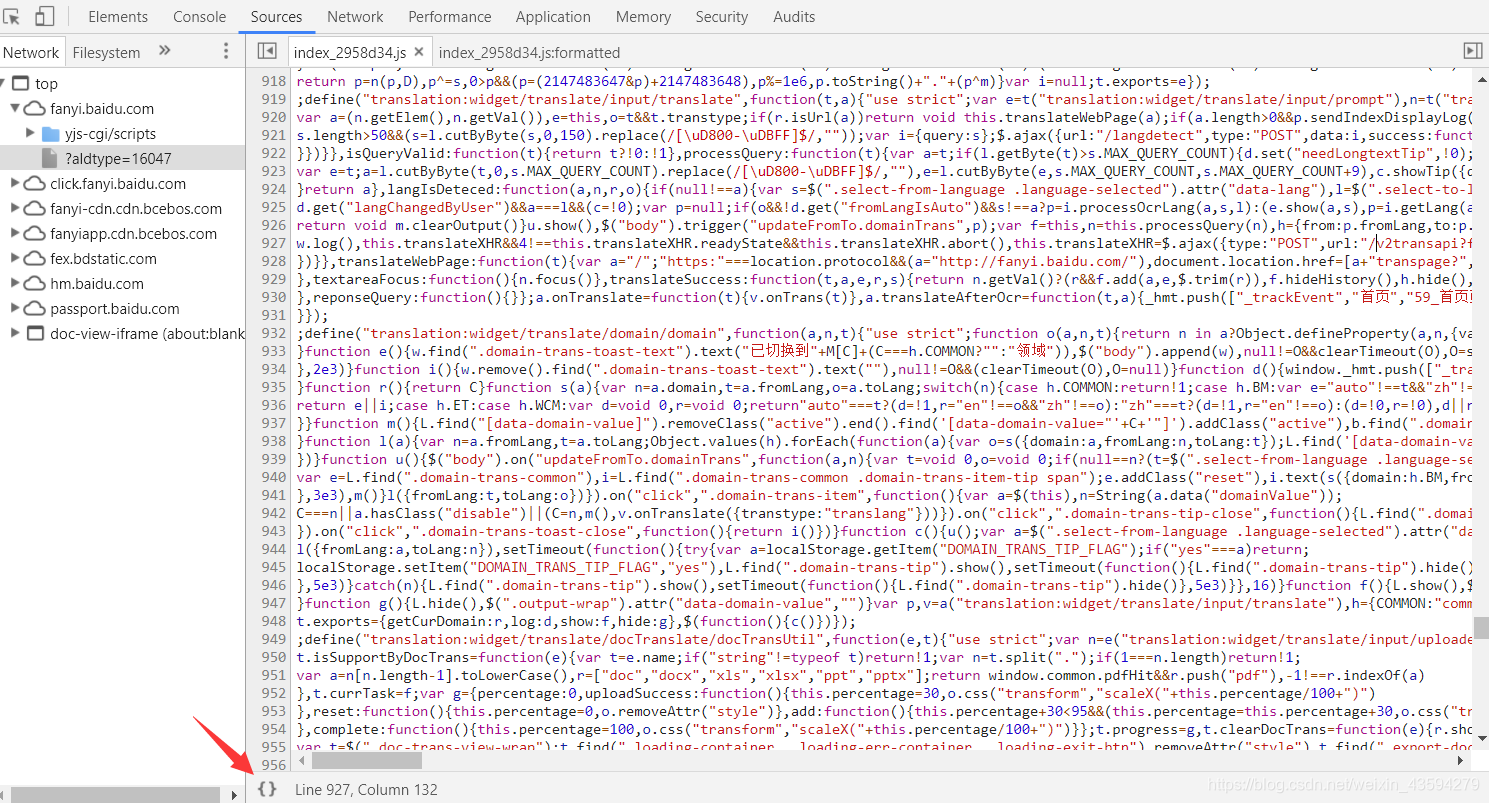
次に、必要なパラメーターがここで定義されており、右側にブレークポイントが直接設定されていることがわかります。ただし、念のため、黄色の線にブレークポイントを設定する必要があります。
次に、インターフェースを更新します。ブレークポイントに到達した場所でWebサイトが停止し、一部のデータが読み込まれます。次に、記号の横のyにマウスを合わせると、次のような画像が表示されます。

次にクリックしてポップしますウィンドウの「e」jsリンクは別のjsスクリプトにジャンプします。
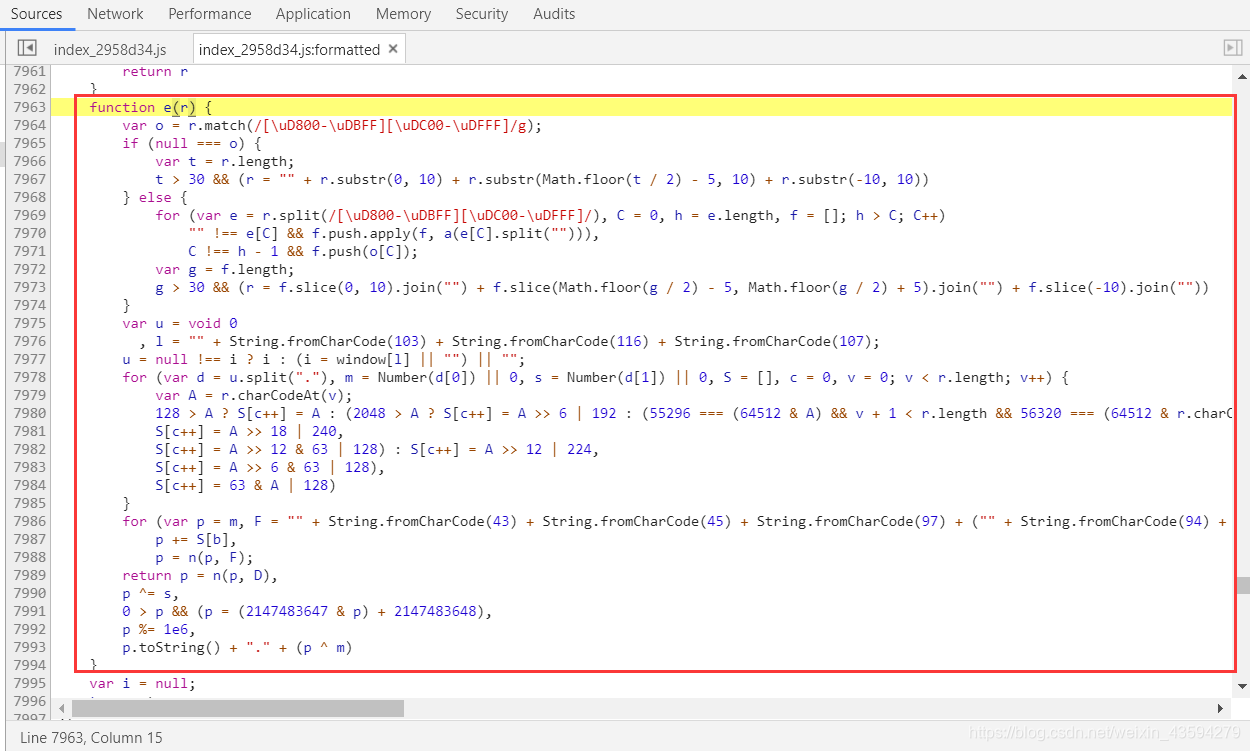
この関数e関数は、signパラメーターのjsコードを生成し、赤いボックス内のコードをここではcode.jsという名前のjsファイルにコピーします。次の仕事は、コードを書いてデバッグすることです。
第二に、コードリンク
import requests
import execjs
class BaiduTranslater:
def __init__(self, sources):
self.sources = sources #输入翻译的内容
self.url = 'https://fanyi.baidu.com/v2transapi?from=zh&to=en' #访问网站
self.headers = {
#请求头
'origin': 'https: // fanyi.baidu.com',
'referer': 'https: // fanyi.baidu.com /?aldtype = 16047',
'user - agent': #自行添加,
'cookie': #自行添加
}
def data_creater(self): #生成data参数表
with open("code.js", 'r')as f: #调用从网站上复制下来的js脚本
content = execjs.compile(f.read()) #编译脚本
sign = content.call("e", self.sources) #得到sign值
self.data = {
'from': 'zh',
'to': 'en',
'query': self.sources,
'transtype': 'translang',
'simple_means_flag': 3,
'sign': sign,
'token': '1c65e5489209deafd9e0302de91a0010', #系统常量
'domain': 'common'
}
def crawler(self):
self.data_creater() #先生成data
res = requests.post(self.url, data=self.data, headers=self.headers)
res.encoding = 'utf-8'
print("翻译结果为:", res.json()['trans_result']['data'][0]['dst']) #对应翻译结果
if __name__ == '__main__':
while True:
str_input = input("请输入要翻译的内容:")
if str_input == 'q':
break
baidu = BaiduTranslater(str_input) #实例化百度翻译类
baidu.crawler() #调用函数进行翻译
execjsには追加のインストールが必要であることに注意する必要があります。これは、cmdに「pipinstallPyExecJS」と入力することでインストールできます。
JSスクリプトを最初に下の図に示します。取得したjsonに従って翻訳結果を抽出し、目的のデータを抽出できます。これは、翻訳結果の簡単な抽出のみです。

コードが少し長いので、コードの一部を片付けました。中括弧の一致が正しいことを確認するために、jsコードの構造に注意してください。
ただし、このようなコードを実行すると、エラーが報告されることがわかります。!
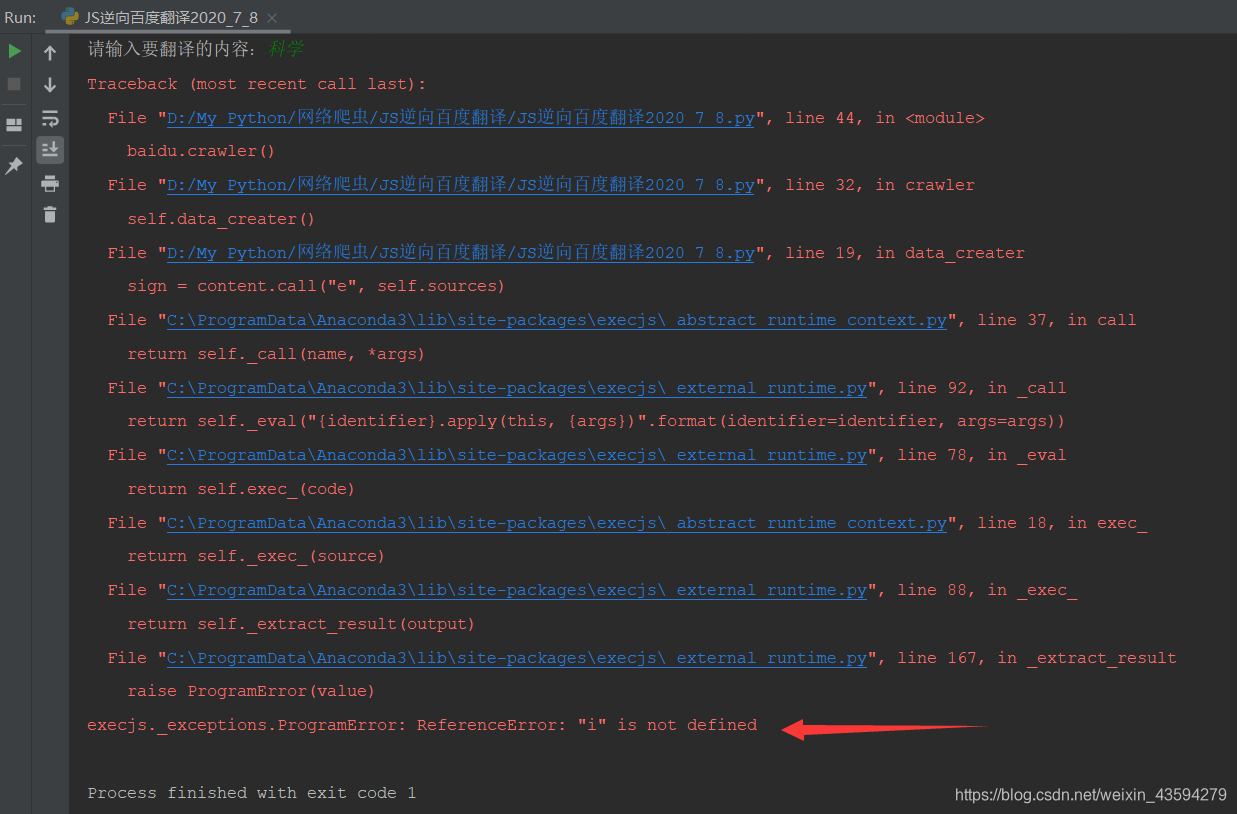
エラーが報告された場合は、大丈夫です。慌てる必要はありませんが、code.jsのiが定義されておらず、コンパイル時にiの値が見つかりません。前のWebサイトのインターフェースに戻って、分析を続けてください。
3.デバッグリンク

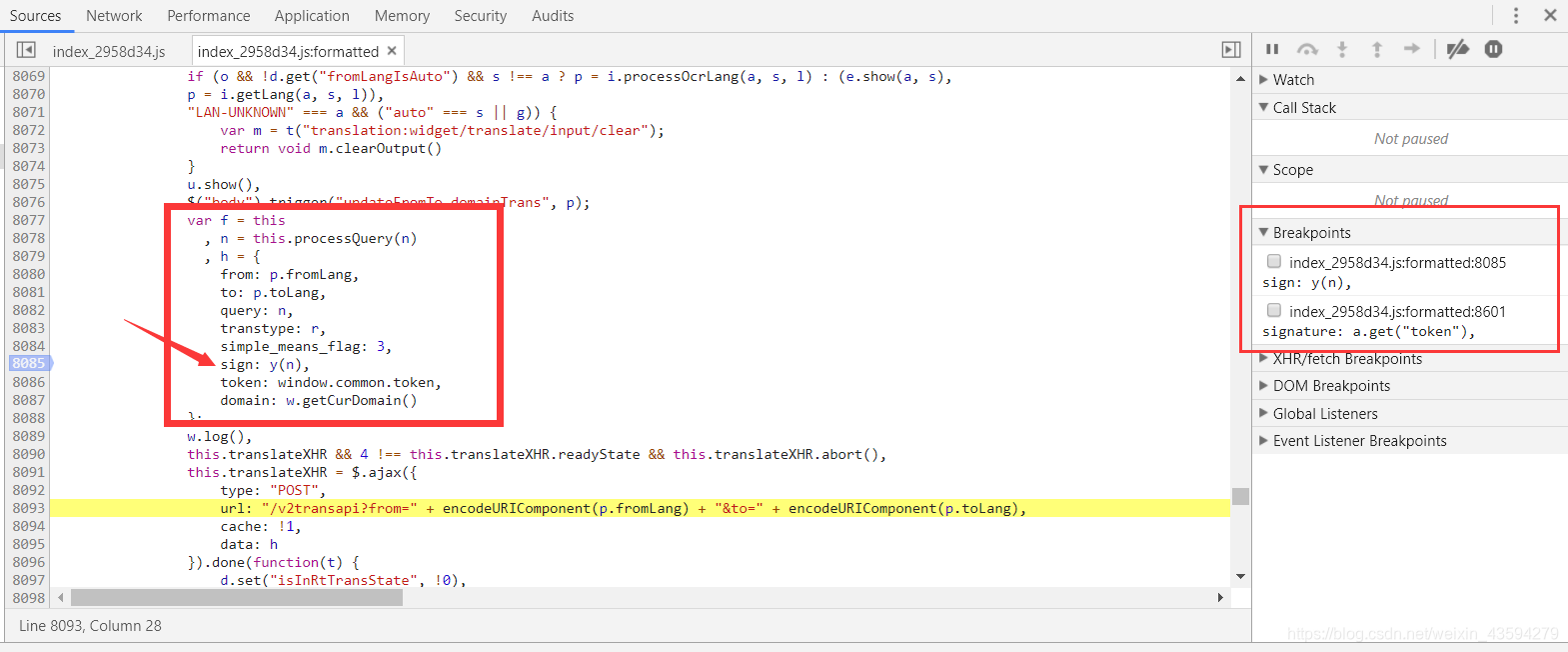
関数e関数にブレークポイントを設定し、BreakPointの他のブレークポイントをアンロードしてから、更新します。下図の「次へ」(↓)を実行すると、実行結果が段階的に表示されます。
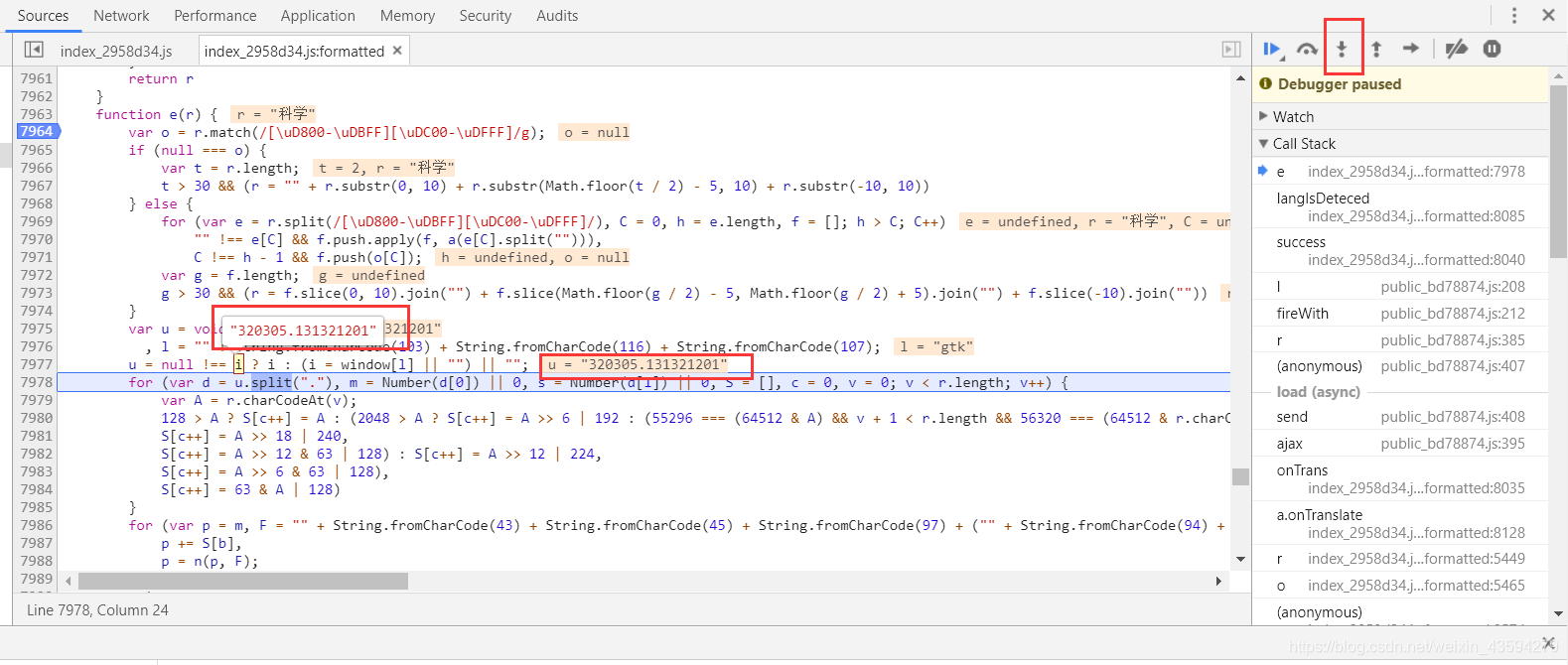
iの値がこの定数であることがはっきりとわかります。なぜそれが定数であると確信できるのでしょうか。window[l]に浮かぶか、赤いボックス内のステートメントで観察できます。iは定数です。計算されました。
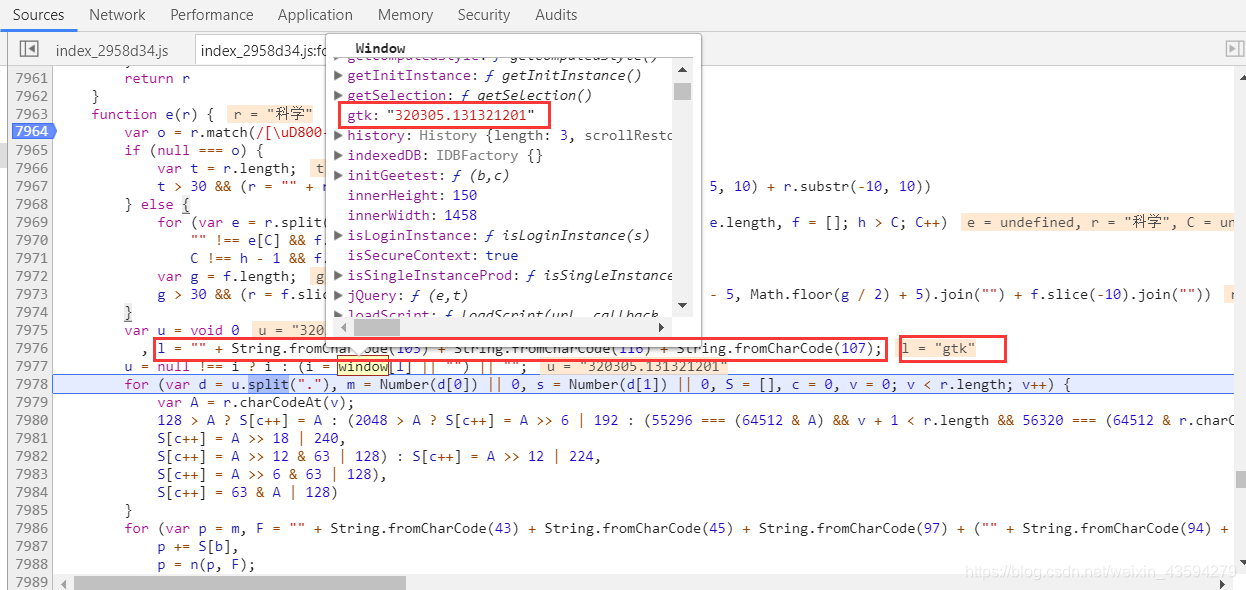
マウスをi変数に合わせ、ポップアップウィンドウのコンテンツをコピーして、定数iをcode.jsスクリプトに追加します。
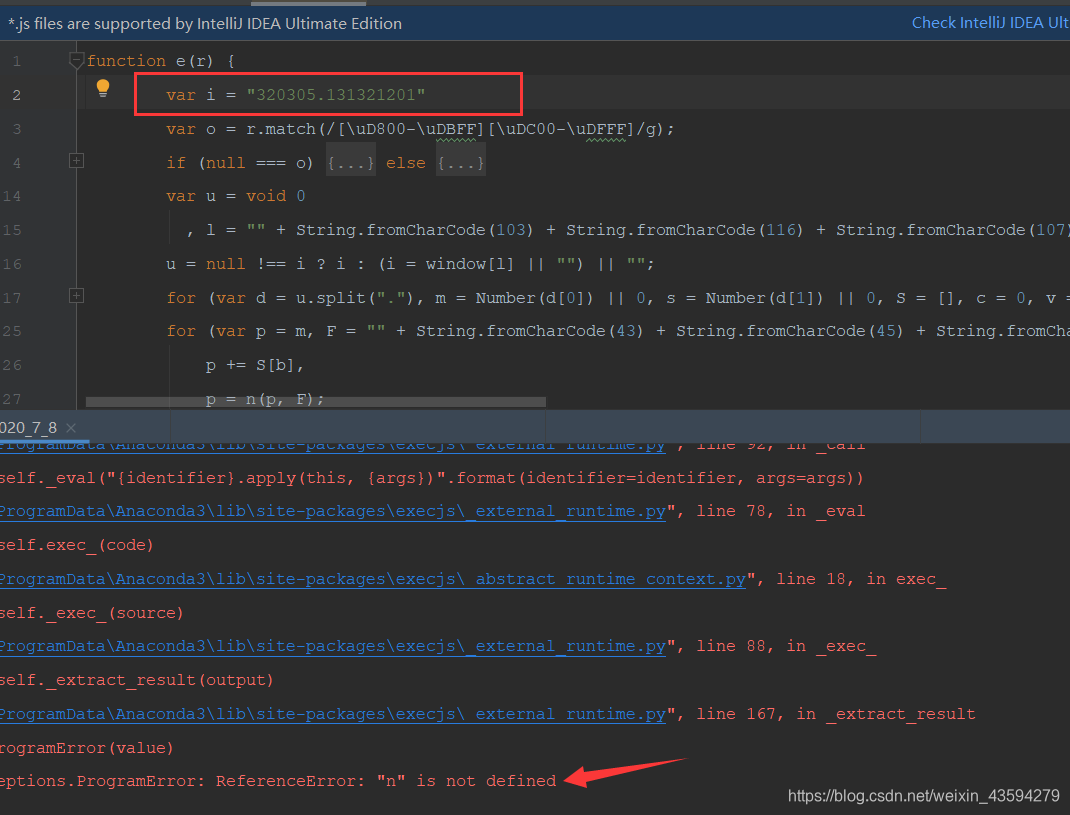
ただし、新しいエラーが報告されているので、分析を続けましょう。結局のところ、私はjsコードの原則を理解する代わりに、他の人のjsコードを使用して、署名を実装し、Pythonコードを自分で作成するため、Webサイトのスクリプトに屈する必要があります。JSの基盤がある場合は、原則を作成することを選択できます。自分でPythonを使用しますが、この方法の方がコストがかかります。もうすぐです。
それでも段階的に進み、次のステップを実行し続けます↓
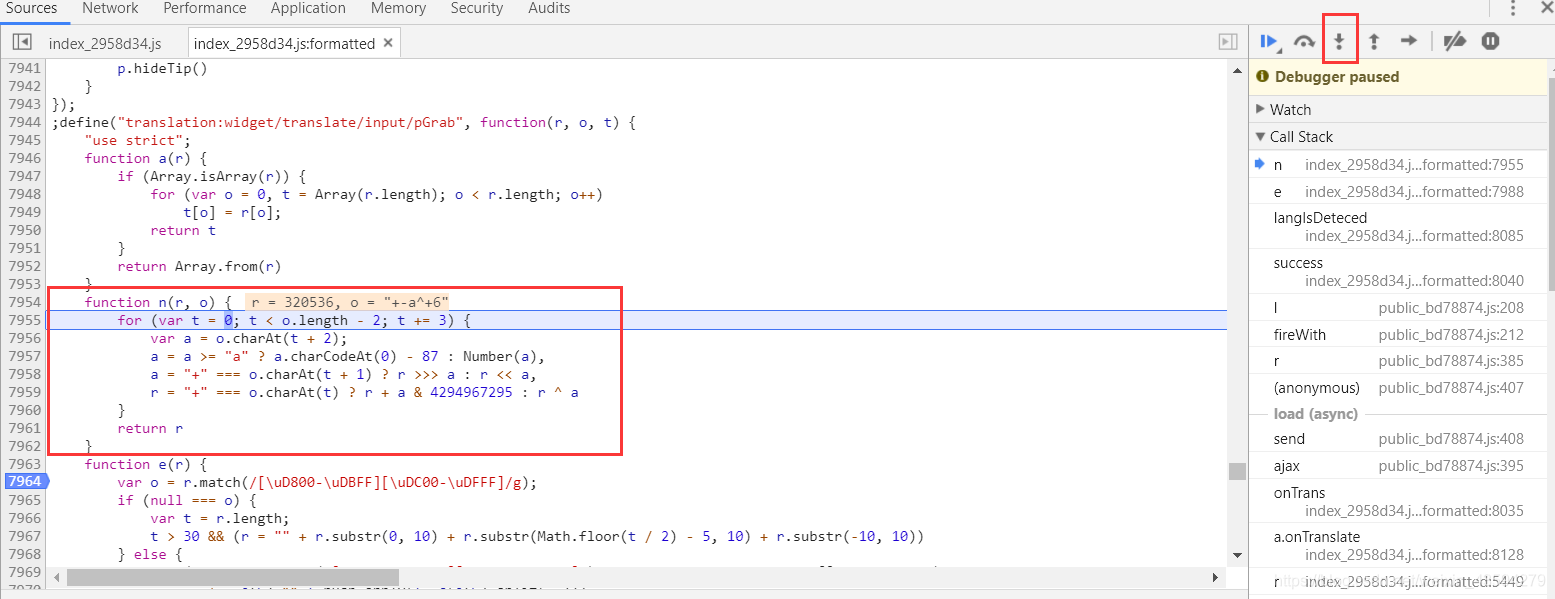
明らかにこれは必要なnであり、nは関数です。赤いボックスのコードをcode.jsにコピーしてから、プログラムを実行します。
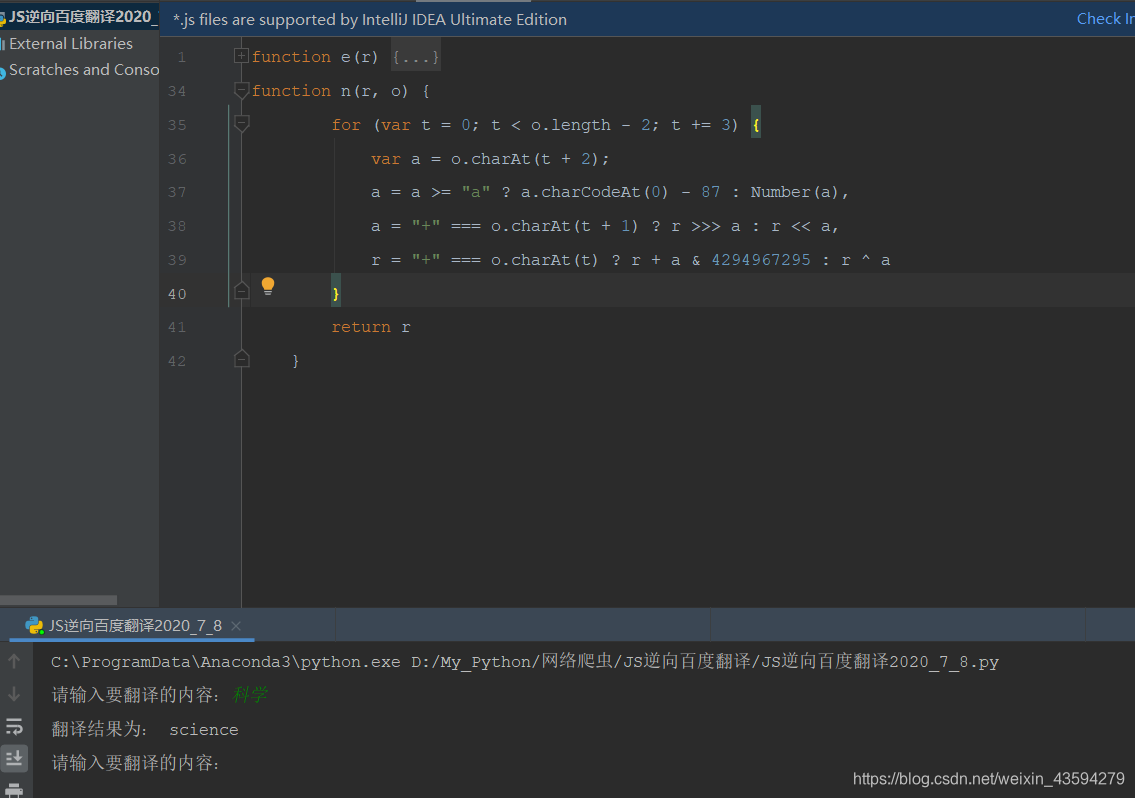
最後に、成功しました!!!
4.まとめ
これから、JSリバースエンジニアリングがWebサイトでデバッグし、目的のコードとパラメーターの構成を探し、中断し、次のステップを実行し、変数を照会し、その他の操作を行うという実際の問題を覗き見することもできます。。これは忍耐と時間を必要とするプロセスです。正直なところ、それは本当に忍耐力を必要とします。学習の最初からどこから始めればよいかわからない場合は、既製のビデオ教育を見つける必要があります。次に何をすべきかわからない。最も重要なことは、知識を自分の中で何かに変えることができるようにするための学習方法、つまりスキルとテクノロジーの向上です。スキルとテクノロジーは1日で達成することはできず、時間の経過とともに蓄積されます。
この記事は説明を参照しています:[Pythonクローラー]百度翻訳JSリバース