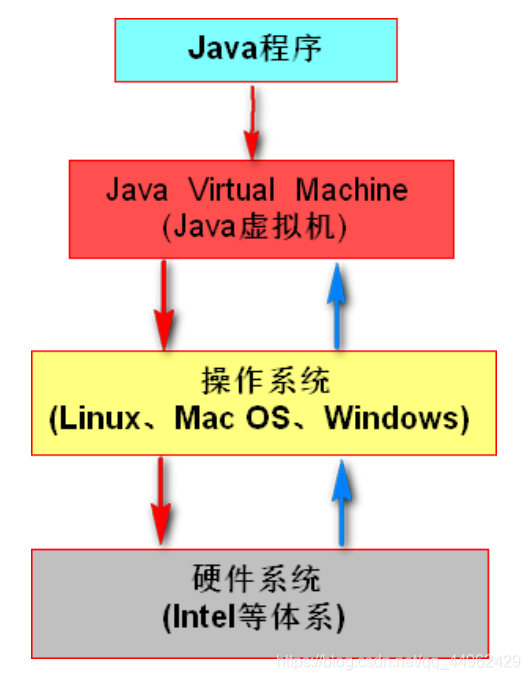
1.JVMアーキテクチャの概要
1. JVMはオペレーティングシステム上で実行され、ハードウェアと直接対話しません
2.JVMアーキテクチャ図
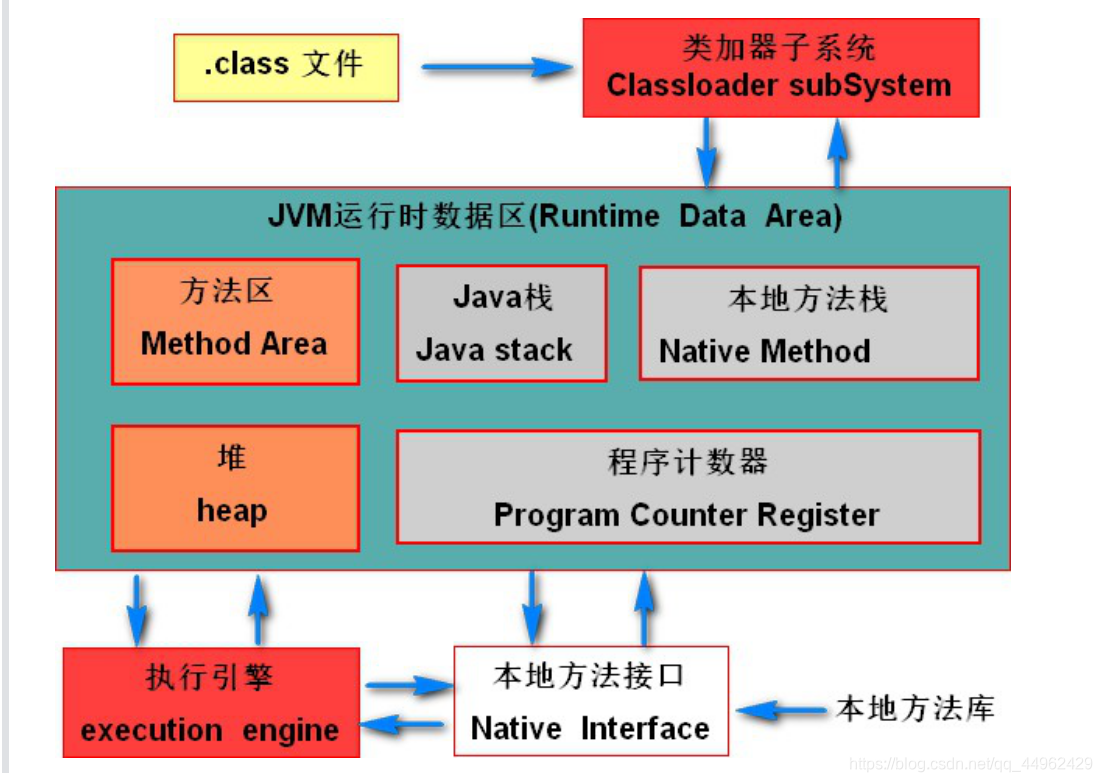
ストレージの内容に応じて、メソッド領域、Javaスタック、ローカルメソッドスタック、ヒープ、プログラムカウンタの5つの領域に分けられます。その中で、メソッド領域とヒープはスレッドによって共有され、Javaスタック、ローカルメソッドスタック、およびプログラムカウンタはスレッドに固有です。
1.プログラムカウンタ
はメモリスペースが小さいため、現在のスレッドで実行されているバイトコードの行番号インジケータと見なすことができます。バイトコードインタープリタが動作すると、このカウンタの値を変更して、次に実行するカウンタを選択します。 。バイトコード命令、分岐、ループ、ジャンプ、例外処理、スレッドスキニングなどの基本機能はすべて、このカウンターに依存して完了します。同時に、スレッド切り替え後に正しい実行位置を復元するには、各スレッドが必要です。独立各スレッドのプログラムカウンタは相互に影響を与えず、独立して格納されます。このタイプのメモリ領域をスレッドプライベートメモリと呼びます。
2.
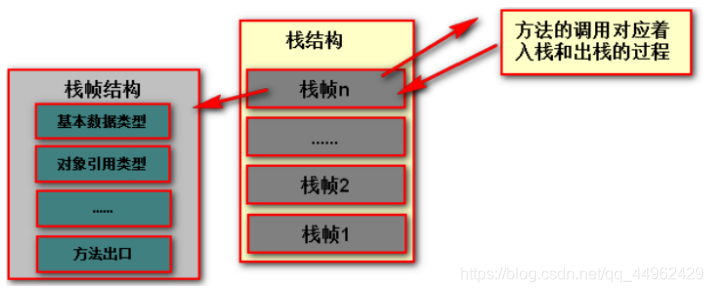
プログラムカウンタと同様に、Javaスタック(仮想マシンスタック)もスレッド専用であり、宣言期間はスレッドの宣言期間と同じです。仮想マシンスタックは、Javaメソッド実行のメモリモデルを記述します。各メソッドは、実行と同時にスタックフレーム(StackFrame)を作成します。これは、ローカル変数テーブル、オペランドスタック、動的リンク、メソッドなどの情報を格納するために使用されます。メソッドの呼び出しから実行までのプロセスは、仮想マシンスタック内のスタックフレームをプッシュしてスタックからポップアウトするプロセスに対応します。
3.ローカルメソッドスタック
は、仮想マシンで使用されるネイティブメソッドを提供し、データスレッド専用のデータ領域でもあります。通常の状況では、この領域に注意を払う必要はありません。C言語の説明
4.ヒープ
は、Java仮想マシンによって管理される最大のメモリです。仮想マシンの起動時に、すべてのスレッドで共有されるメモリ領域であるブロックが作成されます。主な目的は、インスタンスオブジェクトを格納することです。同時に、この領域は、管理される主な領域です。ガベージコレクタによって使用される世代別コレクションアルゴリズムによると、ガベージコレクタによって「GC」ヒープと呼ばれることがよくあります。ヒープメモリロジックは

5つに分割され、メソッド領域は
非ヒープとも呼ばれます。仮想マシンによってロードされた、インスタントコンパイラによってコンパイルされたクラス情報、定数、静的変数、およびコードを格納します。これは、各スレッドによって共有される共有メモリ領域でもあります。
注:メソッド領域にはランタイム定数プールと呼ばれる領域があり、主にコンパイルによって生成されたさまざまなリテラル値とシンボル参照を格納するために使用されます。コンテンツのこの部分は、クラスが終了した後、ランタイム定数プールに格納されます。ロードされました。
3.クラスの読み込み
(1)クラスロードメカニズム:仮想マシンは、クラスを記述するデータを.class照会からメモリにロードし、データをチェックし、変換、分析、初期化して、最終的に仮想マシンで直接使用できるJavaタイプを形成します。 。
注:クラスのロードは1回だけ実行されます
(2)クラスのロードプロセス:
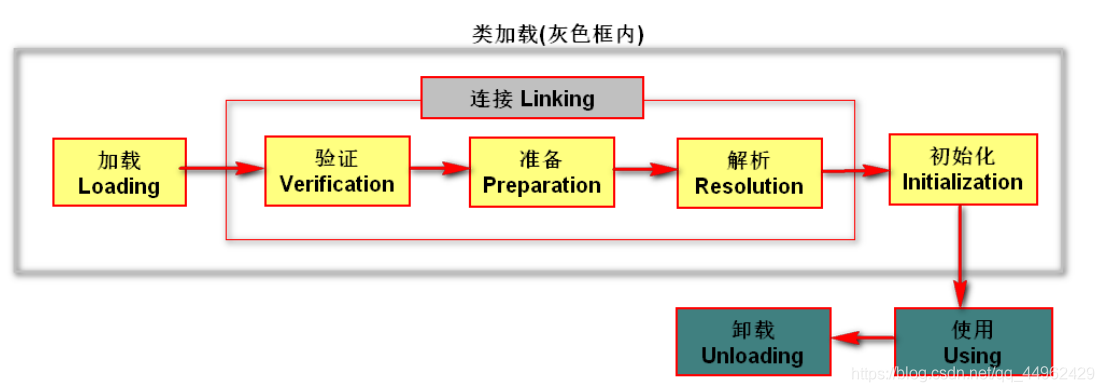
ロード:クラスファイルのバイトコードコンテンツをメモリにロードし、コンテンツをメソッド領域のランタイムデータ構造に変換し、この表現をで生成します。メモリクラスのjava.lang.Classオブジェクト(クラスオブジェクト)は、メソッド領域のクラスデータへのアクセスエントリとして機能します。
検証:クラスファイルのバイトコンテンツがJVM仕様に準拠しており、JVM自体のセキュリティを危険にさらしていないことを確認します。
準備:クラス変数(静的変数)にメモリスペースを正式に割り当て、静的変数を初期化します(デフォルト値を割り当てます)。静的変数のメモリはメソッドに割り当てられます。
解決策:仮想マシン定数プールのシンボリック参照を直接参照に置き換えるプロセス。
例:String s = "aaa"、sに変換されたアドレスは "aaa"のアドレスを指します
初期化:プログラムを通じてプログラマーが作成した主観的な計画に従って、静的変数およびその他のリソースの初期化が完了します。このプロセスでは、静的変数の割り当てと静的コードがステートメントで完了します。
4.クラスローダー
(1)クラスローダー:クラスロードプロセスのロード段階を実装するために使用されます。クラスファイルのバイトコードコンテンツをメモリにロードし、これらのコンテンツをメソッドのランタイムデータ構造に変換し、生成します。メモリ内の代表このクラスのjava.lang.Classオブジェクトは、メソッド領域のクラスデータへのアクセスエントリとして機能します。
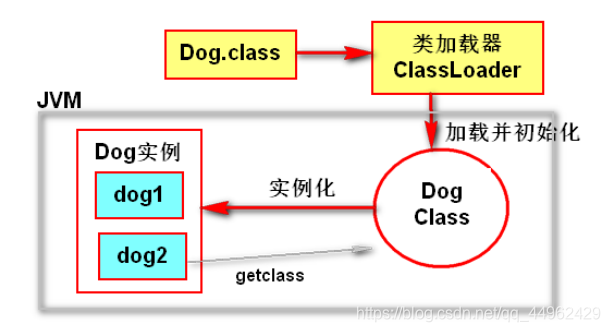
(2)クラスローディングの分類
1.仮想マシン自体のクラスローディング:
クラスローダーを起動します:C ++言語の実装、%java_home%jre / lib /rt.jarのコンテンツのロードを担当
拡張クラスローダー:Java言語の実装、%java_home%jre / lib / ext/*。jarのコンテンツのロードを担当
アプリケーションクラスローダー:システムクラスローダーとも呼ばれ、ユーザークラスパスclassPathのすべてのクラスのロードを担当します。非アクティブ化されたプログラムで独自のクラスローダーが定義されていない場合、通常、デフォルトでアプリケーションクラスのロードが使用されます。
2.ユーザー定義のクラスローダー
*ユーザーはjava.lang.ClassLoaderを継承してクラスローダーをカスタマイズできます
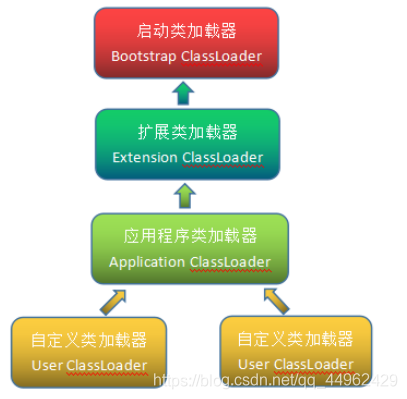
(3)クラスローダーのParents Delegation Model(Parents Delegation Model)
*作業プロセス:クラスローダーが受信した場合リクエストをロードするには、最初にクラスを単独でロードしようとはしませんが、要求を親クラスローダーに委任して完了させます。これはクラスローダーのすべてのレベルに当てはまるため、すべてのロード要求は最終的に最も多くのレベルに送信される必要があります。トップレベルのスタートアップクラス。親クラスがロード要求を完了できない(必要なクラスが検索範囲に見つからない)とフィードバックした場合にのみ、子クラスはそれを単独でロードしようとします。
*利点:親の委任を使用します。アキュムレータを編成するモデル2つの関係では、どのクラスであっても、rt.jarにあるjava.lang.Objectクラスをロードするなど、Javaがクラスロードとともに優先度レベルの関係を持っているという明らかな利点があります。ロードされたこのクラスは、最終的にはトップレベルのスタートアップクラスローダーにロードを委託されるため、Objectクラスは、プログラムのさまざまなクラスロード環境で同じクラスになります。
コード例
public class Test{
public static void main(String[] args) throws IOException {
Object obj = new Object();
System.out.println(obj.getClass().getClassLoader()); //启动类加载器,所以打印结果为null
MyClass mc = new MyClass();
System.out.println(mc.getClass().getClassLoader().
getParent().getParent());
System.out.println(mc.getClass().getClassLoader().getParent());
System.out.println(mc.getClass().getClassLoader());
}
}
class MyClass{}
5.ガベージコレクション
1.オブジェクトが死んでいるかどうかを判断します
(1)参照カウントアルゴリズム:各オブジェクトに参照カウンターを追加します。つまり、オブジェクトが1つの場所で参照されるたびに、カウンターが1ずつ増加し、参照が無効な場合は、カウンタが1減少し、カウンタが0のオブジェクトをいつでも使用できなくなります。
*長所:参照カウントアルゴリズムの実装が比較的簡単で、判断効率が高くなります。
*短所:解決が困難です。オブジェクト間の参照を変更する問題。

現在の主流のJava仮想マシンは参照カウントアルゴリズムを使用してメモリを管理していないため、上記のコードの実行はリサイクルできます。
(2)到達可能性分析アルゴリズム:「GCルート」と呼ばれる一連のオブジェクトを開始点として使用し、これらのノードから下方向に検索します。検索されたパスは参照チェーンと呼ばれます。オブジェクトの場合GCルートへの参照チェーンがない場合は、このオブジェクトが使用できないことを証明します。
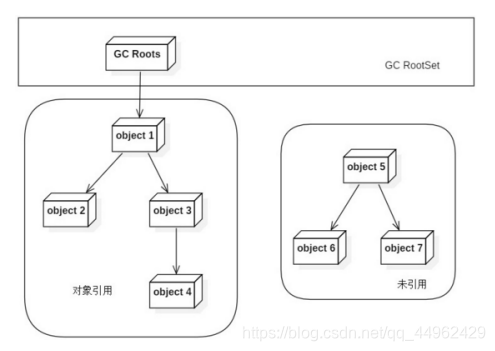
Javaボイスでは、GCルートとして使用できるオブジェクトは次のとおりです。
*仮想マシンスタックで参照されるオブジェクト(スタックフレーム内のローカル変数テーブル。つまり、ローカル変数)
*のクラス静的プロパティによって参照されるオブジェクト
メソッド領域*メソッド領域
*の定数によって参照されるオブジェクトネイティブメソッドによって参照されるオブジェクト(ネイティブメソッド)
2.参考文献の分類
(1)背景:伝統的に、オブジェクトは引用されているか引用されていないだけで満たされていると理解されていますが、「食べるのが味がなく、残念です」というオブジェクトを説明する方法はありません。このようなカテゴリを説明したいと思います。オブジェクトは、メモリスペースがまだ十分である場合、メモリに保持できます。カードマシンのリカバリ後もメモリスペースが非常に狭い場合は、これらのオブジェクトを破棄できます。
(2)JDK1.2以降、オブジェクトの参照は4つのレベルに分割されるため、プログラムはオブジェクトのライフサイクルをより柔軟に制御できます。
*強い参照
*ソフト参照
*弱い参照(弱い参照)
*ファントム参照
(3)参照のレベルは高から低です:強い参照>ソフト参照>弱い参照>ファントム参照
*強い参照: "Object obj =" new Object()と同様に、プログラムで最も一般的に使用される参照です。 "、この種の参照は、強参照がまだ存在する限り、ガベージコレクターが強いクレジットでオブジェクトを再利用することはありません。メモリスペースが不足すると、JVMはOutOfMemoryErrorをスローし、再利用しません。
*ソフト参照:いくつかの有用であるが必須ではないオブジェクトを説明するために使用されます。オブジェクトにソフト参照しかない場合、メモリスペースは十分であり、ガベージコレクターはそれを再利用せず、オブジェクトはプログラムで使用でき、ソフト参照は次のことができます。使用メモリに依存する通知キャッシュを実現するために、JDK1.2以降、ソフト参照を実装するためのSoftReferenceクラスが提供されています。
*弱参照:一部の必須ではないオブジェクトの説明にも使用されます。弱参照とソフト参照の違いは、弱い参照を持つオブジェクトのみがより正確なライフサイクルを持ち、ガベージコレクタスレッドがその管轄下のメモリ領域をスキャンすることです。このプロセスでは、弱い参照のみを持つオブジェクトが見つかると、現在のメモリスペースが十分であるかどうかに関係なく、そのメモリが再利用されます。JDK1.2以降、弱い参照を実装するためにWeakReferenceクラスが提供されます。
*仮想参照:他の種類の参照とは異なり、仮想参照と同じです。仮想参照はオブジェクトのライフサイクルを決定しません。オブジェクトが仮想参照のみを保持している場合は、次のようになります。参照がない場合、いつでも影響を受ける可能性があります。ガベージコレクターは再利用し、仮想参照を介してインスタンスオブジェクトを取得できません。オブジェクトの仮想参照の関連付けを設定する唯一の目的は、現在のときに通知を受信することです。オブジェクトはガベージコレクターによってリサイクルされます。JDK1.2以降、PhantomReferenceクラスが仮想参照を実装するようになります。
3.さまざまな領域でのガベージコレクション

メソッド領域:HotSpot仮想マシンでの永続的な生成ガベージコレクションの永続的な生成が、廃止された定数と役に立たないクラスオブジェクトの2つの部分をリサイクルする場合
*廃止された定数:文字列定数「abc」を想定します。は定数プールに入りましたが、現在のシステムには「abc」定数を指す文字列タイプの参照がなく、「abc」リテラル定数を使用する場所は他にありません。メモリの再利用が発生した場合、および必要に応じて、 「abc」定数はクリアされます。
*役に立たないクラスオブジェクト
*このクラスのすべてのインスタンスオブジェクトがリサイクルされました。つまり、Javaヒープにこのクラスのインスタンスがありません
*このクラスをロードしたClassLoaderがリサイクルされました
*これによって使用されるjava.lang.Classオブジェクトクラスは使用できません。どこでも参照されており、このクラスのメソッドには、どこでもリフレクションを介してアクセスできません。
注:ここで不要なオブジェクトは、3つの条件を満たす場合にリサイクルできますが、必須ではありません。リサイクルするかどうかは、-Xnoclassgcパラメーターで制御できます。同時に、-XX:+ TraceClassLoadingを使用してクラスの読み込み情報。
ヒープ領域:特に新世代のガベージコレクションでは、従来のアプリケーションで実行されるガベージコレクションは、通常、スペースの70%から95%を回復できます。
ヒープメモリ割り当て図
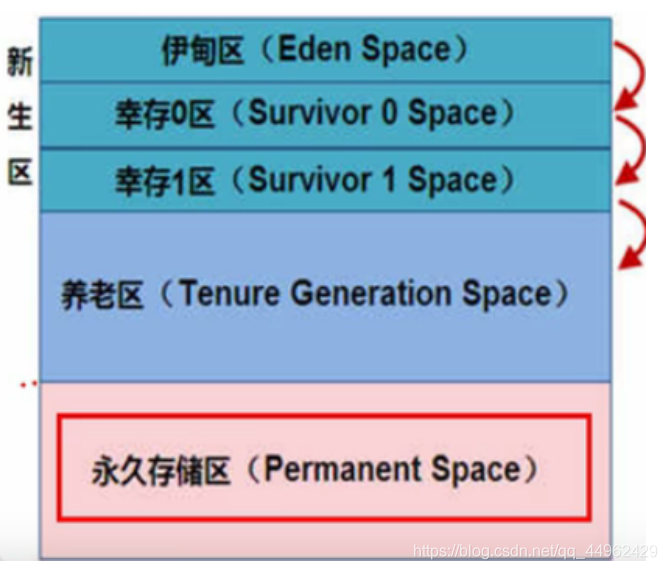
簡単な説明:新生児領域は、オブジェクトが作成、適用、および消滅する領域です。オブジェクトは、ガベージコレクターによって作成、適用され、最終的に収集されて消滅します。新生児エリアは、エデンエリアとサバイバーエリアの2つの部分に分かれています。新しく作成されたすべてのオブジェクト(新規)はEdenエリアにあり、サバイバーはサバイバーゾーン0とゾーン1の2つに分けられます。Edenゾーンのスペースが使い果たされると、プログラムは新しいオブジェクト、JVMオブジェクトを作成する必要があります。 Yiガベージコレクションはエデンエリアで開始され、YGCを使用して、エデンエリアで使用されなくなったオブジェクトを破棄し、エデンエリアの残りのオブジェクトをサバイバーエリア0に移動します。エリア0はいっぱいで、エリア0はガベージ破壊されます。、生き残ったオブジェクトはサバイバーゾーン1に移動されます。ゾーン1もいっぱいの場合、ゾーン1は高齢者ケアゾーンに移動されます。高齢者ケアゾーンもいっぱいの場合、JVMはこの時点でFullGC(略称:FGC)をオンにして、リタイアメントエリアのメモリクリーニングを続行します。ただし、フルGCの実行後に新しいオブジェクトを保存できない場合は、OOM例外が発生します。ヒープメモリオーバーフローです。
4.ガベージコレクションアルゴリズム
(1)マークスイープ:最も基本的なガベージコレクションアルゴリズムです。このアイデアに基づいて他のアルゴリズムが改善されています。マークスイープアルゴリズムは「マーク」と「スイープ」に分けられます。「クリア」2つステージ:最初にリサイクルが必要なオブジェクトにマークを付け、マークを付けた後、マークされたすべてのオブジェクトを均一に収集します。

短所:
*マーキングとクリアはあまり効率的ではありません
。クリアをマークした後、多数の不連続なメモリフラグメントが生成され、大きなオブジェクトが後で使用可能なスペースを見つけることができないという問題が発生します。
(2)コピーアルゴリズム(コピー):使用可能なメモリを2つのブロックに分割し、一度に1つのブロックのみを使用します。このメモリのブロックが使い果たされると、残っているオブジェクトが他のブロックにコピーされ、使用されます。メモリメモリスペースは一度にクリーンアップされます。
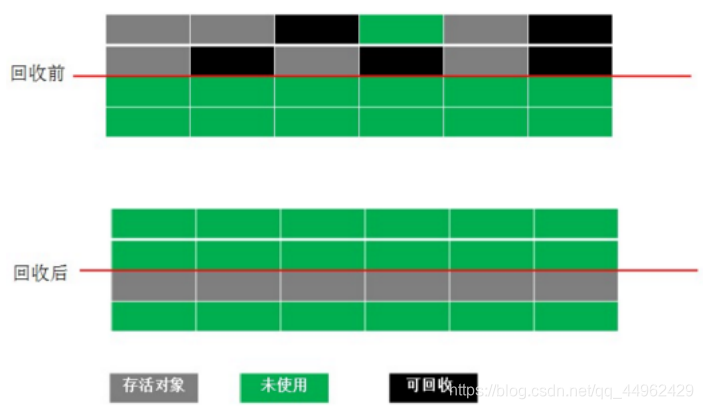
分析:このアルゴリズムは実装が簡単で、メモリ効率が高く、断片化する傾向がありませんが、最大の問題は、使用可能なメモリが元のメモリの半分に圧縮されることです。また、存続するオブジェクトの数が増えると、コピーアルゴリズムの効率が大幅に低下します。
アプリケーション:仮想マシンの現在の商用バージョンは、レプリケーションアルゴリズムを使用して新世代を再利用します。新世代のオブジェクトの98%は「ライブアンドダイ」であるため、ヒープメモリはより大きなエデンスペースと2つのより小さなスペースに分割されます。 Serivors(Survivor)スペース、HotSpot仮想マシンのデフォルトのEdenとSerivorのサイズ比は8:1です。エデンとサービバーを使用するたびに、回収するときに、エデンとセリバーの生き残ったオブジェクトを一度に別のセリバーにコピーし、最後にエデンと使用済みのセリバーのスペースをクリアします。
(3)Mark-Compactアルゴリズム:mark操作は「mark-clear」アルゴリズムと同じです。後続の操作はオブジェクトを直接クリーンアップしませんが、不要なオブジェクトをクリーンアップするときに完了し、残っているすべてのオブジェクトが一方の端を移動してから、端の境界の外側のメモリを直接クリーンアップします。
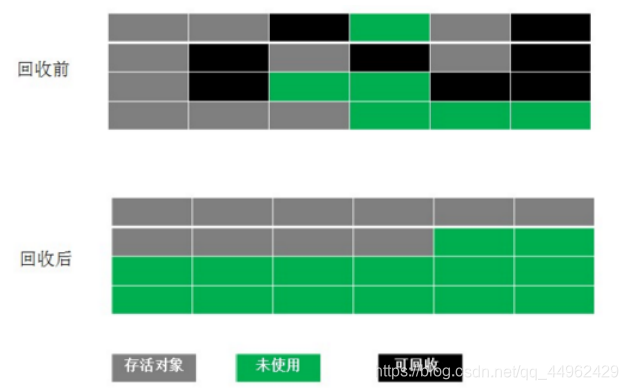
分析:メモリの断片化は発生せず、マーキングに基づいてオブジェクトを移動する必要があるため、効率が低下します。
アプリケーション:老後のオブジェクトの生存率は比較的高く、この収集アルゴリズムは一般的にリサイクルに使用されます。
(4)世代別収集アルゴリズム(世代別収集):現在、商用仮想マシンのガベージコレクションは「世代別収集」を採用しており、オブジェクトの存続のライフサイクルに応じてメモリをいくつかの異なる領域に分割することを中心的な考え方としています。通常、ヒープ領域はテニュア世代とヤング世代に分けられます。旧世代の特徴は、ガベージコレクションごとに収集する必要のあるオブジェクトの数が少ないことですが、新世代の特徴は、すべてのガベージがコレクションリサイクルが必要なオブジェクトが多数あるため、世代の特性に応じて最適なコレクションアルゴリズムを採用できます。ほとんどのJVMGCは、新世代にコピーアルゴリズムを採用しています。旧世代では、毎回収集されるオブジェクトの数が少ないため、Mark-Compactアルゴリズムが使用されます。