MySQLシリーズ-InnoDBインデックスの導入と管理
運営・維持管理YouthO&M Youth
一連の記事の説明
MySQLシリーズの記事には、ソフトウェアのインストール、特定の使用法、バックアップとリカバリなどが含まれ、主に個人の学習メモを記録するために使用されます。使用される主なMySQLバージョンは5.7.28で、サーバーシステムバージョンはCentOS7.5です。この章では、InnoDBインデックス管理について説明します。
インデックス
インデックスの定義
インデックスは、データベース内のデータをすばやく取得するのに役立つデータ構造です。素人の言葉で言えば、索引は本の目次のようなものであり、目次から必要なものをすばやく見つけることができます。
インデックス作成の長所と短所
インデックス作成の利点:
1.データ検索を高速
化できます。2。インデックス作成により、使用プロセスで最適化されたハイダーを使用して、システムのパフォーマンスを向上させることができます。
インデックス作成のデメリット:
1.テーブル内のデータを追加、削除、変更する場合、インデックスを動的に維持する必要があります。これにより、追加/変更/削除の実行効率が低下します
。2。インデックスは物理スペースを占有する必要があります。
インデックス分類
MySQL InnoDBでは、インデックスはクラスター化インデックスと補助インデックス(非クラスター化インデックス)に分けることができます。
クラスター化インデックス
インデックスB + Treeのリーフノードは、データの行全体を格納するプライマリキーインデックスであり、クラスター化インデックスとも呼ばれます。クラスター化インデックスは、ディスク上の実際のデータを再編成して、指定された1つ以上の列の値で並べ替えるアルゴリズムです。特徴は、格納されたデータの順序がインデックスの順序と一致していることです。一般に、主キーはデフォルトでクラスター化インデックスを作成します。データが格納されると、順序は1つだけになるため、テーブルで許可されるクラスター化インデックスは1つだけです。インデックスが見つかると、必要なデータが見つかり、インデックスはクラスター化インデックスになるため、主キーはクラスター化インデックスになります。クラスター化インデックスを変更すると、実際には主キーが変更されます。
:一般的に言えば、テーブルはInnoDBは自動的にインデックスを生成するために列を選択します、それが定義されていない場合でも、クラスタ化インデックスを持っている必要があり
、主キーに基づいてクラスタ化インデックスを作成し、主キーがある場合)1
時)2主キーがない場合は、一意であり、使用されません。空のインデックス列が主キーとして使用され、このテーブルのクラスター化インデックスになります
。3)上記の2つが満たされない場合、innodbは次の方法で仮想クラスター化インデックスを作成します。自体
次の表がある場合:
CREATE TABLE world.student(
`id` INT AUTO_INCREMENT NOT NULL COMMENT 'id',
`name` VARCHAR(10) NOT NULL COMMENT '姓名',
`age` INT NOT NULL COMMENT '年龄',
PRIMARY KEY(id),
INDEX idx_name(NAME)
)ENGINE=INNODB DEFAULT CHARSET='utf8mb4';
INSERT INTO world.`student`(NAME,age) VALUES('张三',24),('李四',20),('王五',21),('运维少年',18);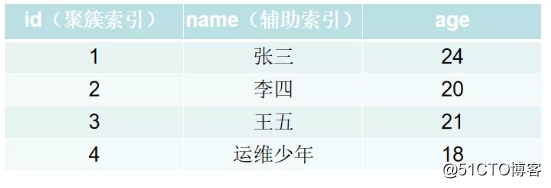
クラスター化インデックスの構造は次のとおりです。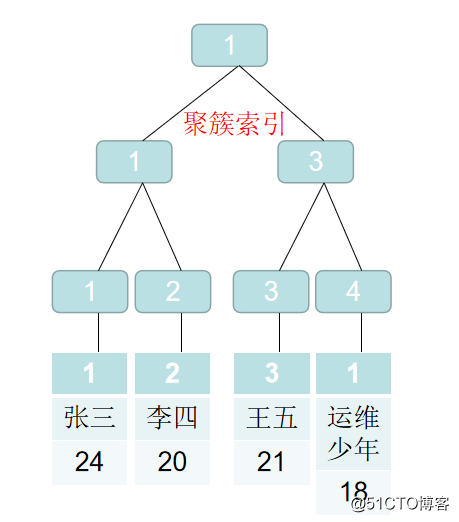
クラスター化インデックスの検索プロセス: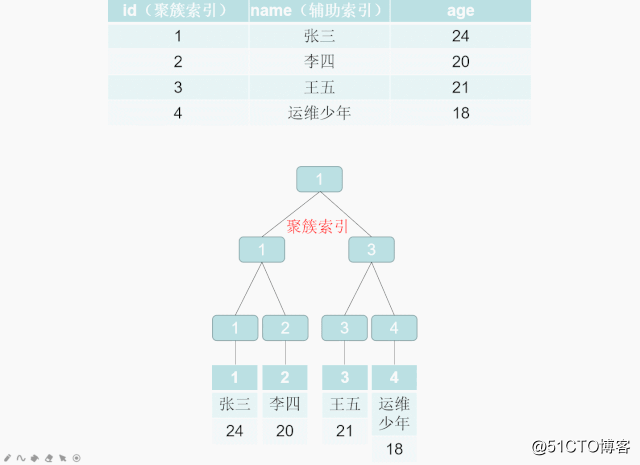
補助インデックス
インデックスB + Treeのリーフノードは主キーの値のみを格納し、インデックス列は非主キーインデックスであり、非クラスター化インデックスとも呼ばれます。テーブルには、複数の非クラスター化インデックスを含めることができます。非クラスター化インデックスのストレージは、データのストレージから分離されています。つまり、インデックスは検出されてもデータが検出されない場合があります。インデックスの値(主キー)に基づいて、テーブルを再度クエリする必要があります。非クラスター化インデックスは、セカンダリインデックスとも呼ばれます。
学生テーブルの補助グループインデックスのデータ構造: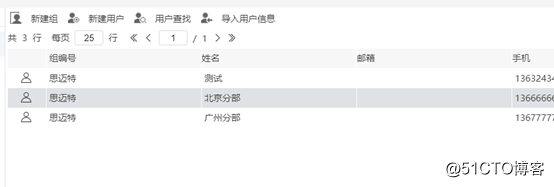
補助グループインデックスルックアップデータプロセス(テーブルに戻らない):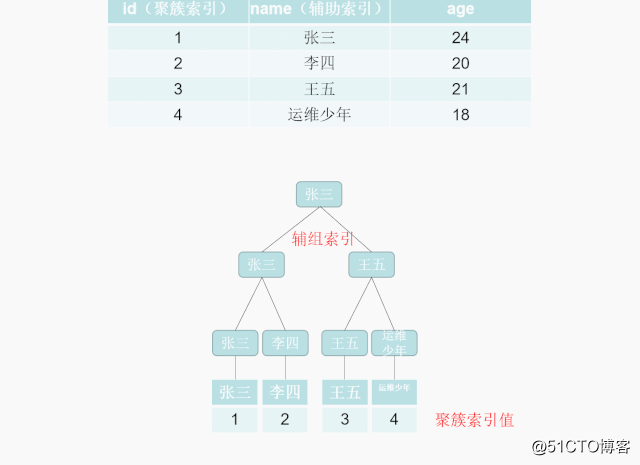
補助グループインデックス検索データプロセス(表に戻る):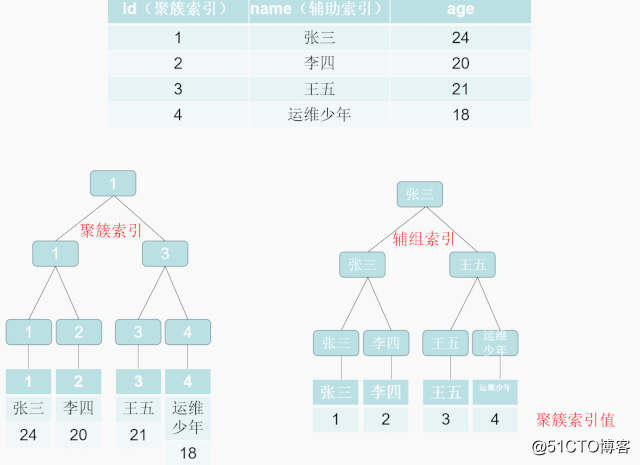
補助インデックス単一列インデックス
単一列インデックス、つまり1つの列を補助インデックス列として使用しますが、クエリ条件で補助インデックス列を使用する場合は、インデックスが使用されます。
補助インデックス複数列インデックス(ジョイントインデックス)
ジョイントインデックス、つまり複数列のインデックスは、インデックスを作成するときに、次のように複数の列をインデックス列として使用します。
alter table student add index idx_na(name,age);補助インデックス複数列インデックス(ジョイントインデックス)
プレフィックスインデックスが対象であり、選択したインデックス列の値の長さが長すぎるため、インデックスの高さが高くなり、インデックスが適用されたときに読み取られるインデックスデータページが多くなります。MySQLでは次のことを推奨しています。インデックスツリーの高さは3〜4層です。したがって、大きなフィールドの最初の部分をインデックス生成条件として選択できます。
本のタイトルと同様に、タイトルを長くすることはできません。タイトルが長すぎると、目次が生成されるときに目次が多くのスペースを占め、目次ページが大きくなります。プレフィックスインデックスは通常、ファジークエリに使用されます。
次のテーブルがある場合は、sno列をインデックス列として使用する必要があります。比較すると、最初の6文字で一意の値を決定できることがわかります。したがって、インデックスを作成するときに、プレフィックスの長さを次のように設定できます。 6インデックスツリーの高さを減らします。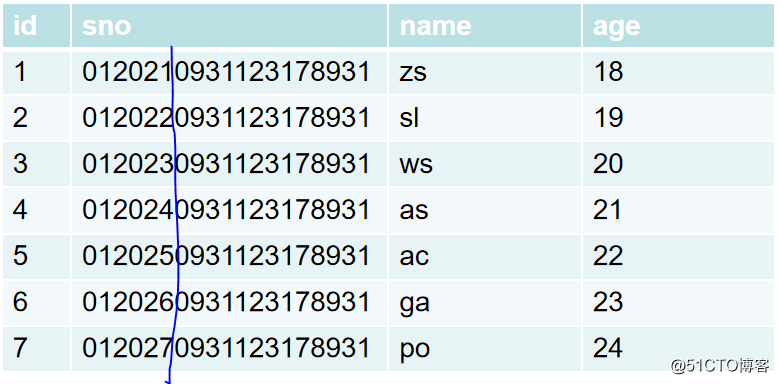
alter table xxx add index index_name(sno(2));インデックス管理
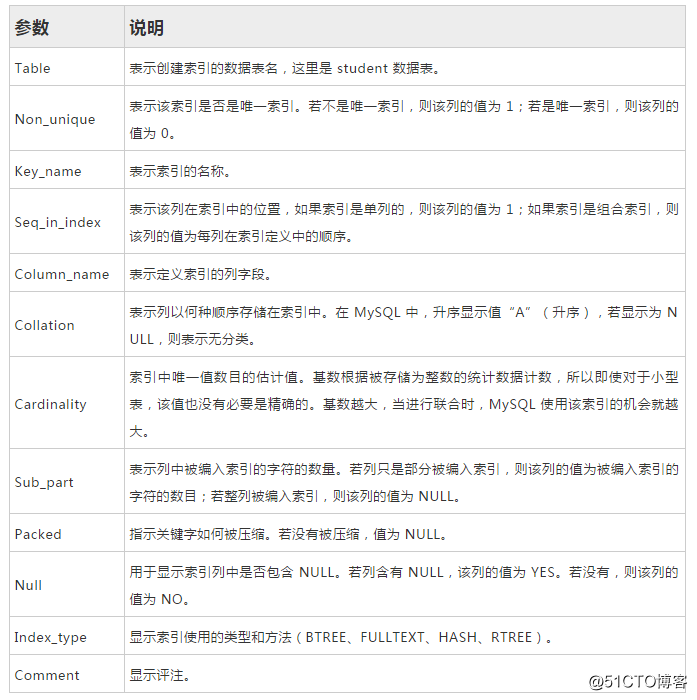
インデックスを表示:
show index from world.student;
インデックスの削除:
drop index idx_name on world.student;
インデックスの作成:
一般的な方法1:テーブルを作成するときに作成する
CREATE TABLE world.student(
`id` INT AUTO_INCREMENT NOT NULL COMMENT 'id',
`name` VARCHAR(10) NOT NULL COMMENT '姓名',
`age` INT NOT NULL COMMENT '年龄',
PRIMARY KEY(id), # 聚簇索引
INDEX idx_name(name) # 辅助索引
)ENGINE=INNODB DEFAULT CHARSET='utf8mb4';一般的な方法2:alterステートメントを使用する
alter table world.student add index idx_name(name);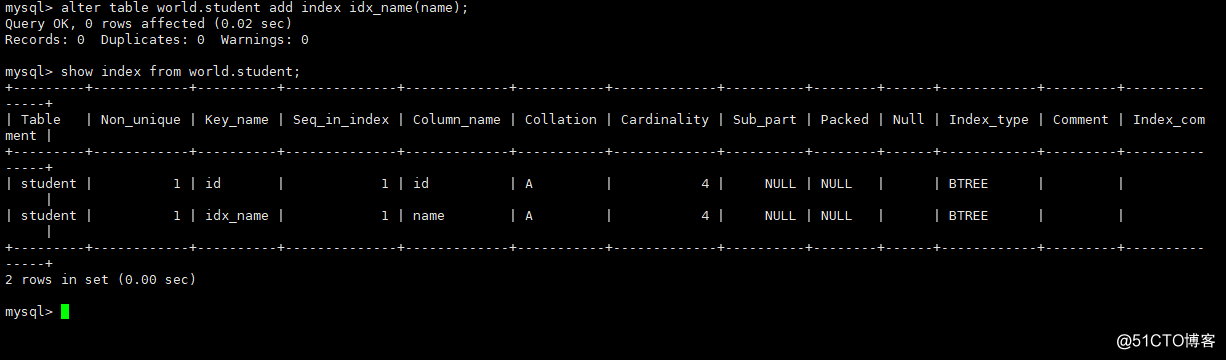
インデックスはいつ作成されますか?
1)ビジネスステートメントのニーズに応じて適切なインデックスを作成します。すべての列にインデックスが付けられる
わけではありません。2)すべての列にインデックスが付けられるわけではありません。インデックスが多いほど良いというわけで
はありません。条件付き列に結合する
無秩序なインデックス作成の結果は?
1)冗長インデックスが多すぎる場合、テーブルデータが変更されると、インデックスが頻繁に更新される可能性があります。多くの通常のビジネスリクエストをブロックします
2)インデックスが多すぎると、オプティマイザが偏差を選択します
インデックスアプリケーションの仕様:
1.テーブルを作成するときは、主キーが必要です。主キーは数値列であることが望ましいです。そうでない場合は、無関係な列をカスタマイズして、自己成長として定義できます
。2 。一意の
インデックスを選択する場合、値一意のインデックスのは一意であり、変更できます。インデックスを使用し
て、生徒テーブルの中学校番号などのレコードの一意のフィールドをすばやく特定できます。このフィールドに一意のインデックスを設定すると、特定の生徒の情報をすばやく特定できます。 。名前を変更すると、同じ名前の現象が発生する可能性があり、クエリ速度が低下します。
3. where、order by、group by、join onなどの操作を頻繁に必要とするフィールドの場合、並べ替えは多くの時間を浪費します。クエリを最適化するためにインデックスを確立できます。列が条件として頻繁に使用される場合重複する値が多すぎる場合は、結合インデックスを確立できます
。4 。可能な限りプレフィックスインデックスを使用します。インデックスフィールドの値が非常に長い場合は、インデックスに値のプレフィックスを使用することをお勧めします
。5。制限
インデックスの数。インデックスの数はできるだけ多くありません。発生する可能性のある問題
1)各インデックスが必要ですディスク領域を占有し、インデックスが多いほど、より多くのディスク領域が必要になります
。2)テーブルを変更する場合は次のようになります。インデックスの再構築と更新が面倒です。インデックスが多いほど、テーブルの更新は時間の無駄になります
。3)オプティマイザ負担が大きく、オプティマイザの選択に影響を与える可能性
があります。percona-toolkitにはツールがあります。インデックスが有用かどうかを具体的に分析します。6。
使用されなくなったインデックスまたはほとんど使用されないインデックスを削除します
。7。大きなテーブルにインデックスを追加します。忙しい時間帯の操作
8.更新された値に基づいて構築することをできるだけ少なくしますカラム
インデックス補足
補足準備フォーム
CREATE TABLE world.student(
`id` INT AUTO_INCREMENT NOT NULL COMMENT 'id',
`name` VARCHAR(10) NOT NULL COMMENT '姓名',
`age` CHAR(3) NOT NULL COMMENT '年龄',
`address` VARCHAR(20) NOT NULL COMMENT '地址',
`phone` VARCHAR(11) NOT NULL COMMENT '手机号码',
PRIMARY KEY(id),
INDEX idx_info(age,NAME,address)
)ENGINE=INNODB DEFAULT CHARSET='utf8mb4';
INSERT INTO world.`student`(NAME,age,address,phone) VALUES('张三',24,'北京市','10086'),('李四',20,'上海市','10000'),('王五',21,'重庆市','10010'),('运维少年',18,'天津市','13800138000');
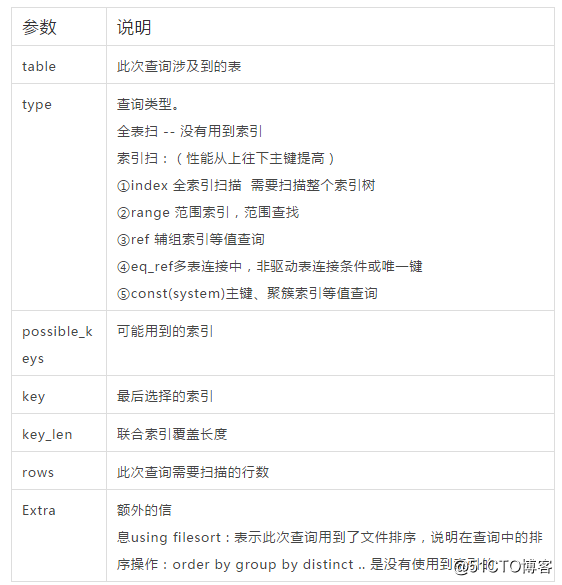
SQLにインデックスが付けられているかどうかを確認するにはどうすればよいですか?
方法1:説明する
explain 执行的语句
explain select * from student where id=1;方法2:説明
desc 执行的语句
desc select * from student where name='张三'
補足インデックススキャンタイプ
1)インデックスフルインデックススキャン-インデックスツリー全体をスキャンする必要があります
インデックスフルインデックススキャンは通常、クエリ列がインデックス列の場合に発生します
select id from student;
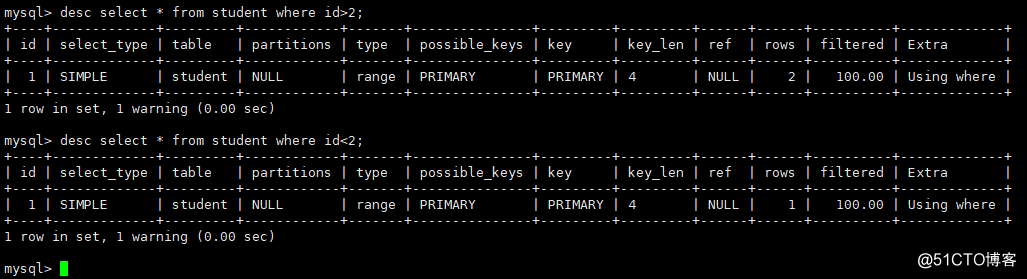
2)範囲-範囲スキャン
クエリ条件が>、<、inなどの場合、タイプは範囲になります

3)ref-auxiliaryindexと同等のクエリ
補助インデックスの同等のクエリは、通常、同等のクエリに補助インデックス列を使用する場合に発生します。
4)Const主キーと同等のクエリ
クラスター化インデックスの同等のクエリは、通常、クラスター化インデックスの列を使用して同等のクエリを実行するときに発生します。
どのような状況でインデックスが追加されませんか?
1)クエリ条件なし
2)結果セットをクエリする場合、元のテーブルのほとんどのデータは15%〜30%である必要があります。それを超えると、オプティマイザはインデックスを作成する必要がないと感じます。リミページングを使用できます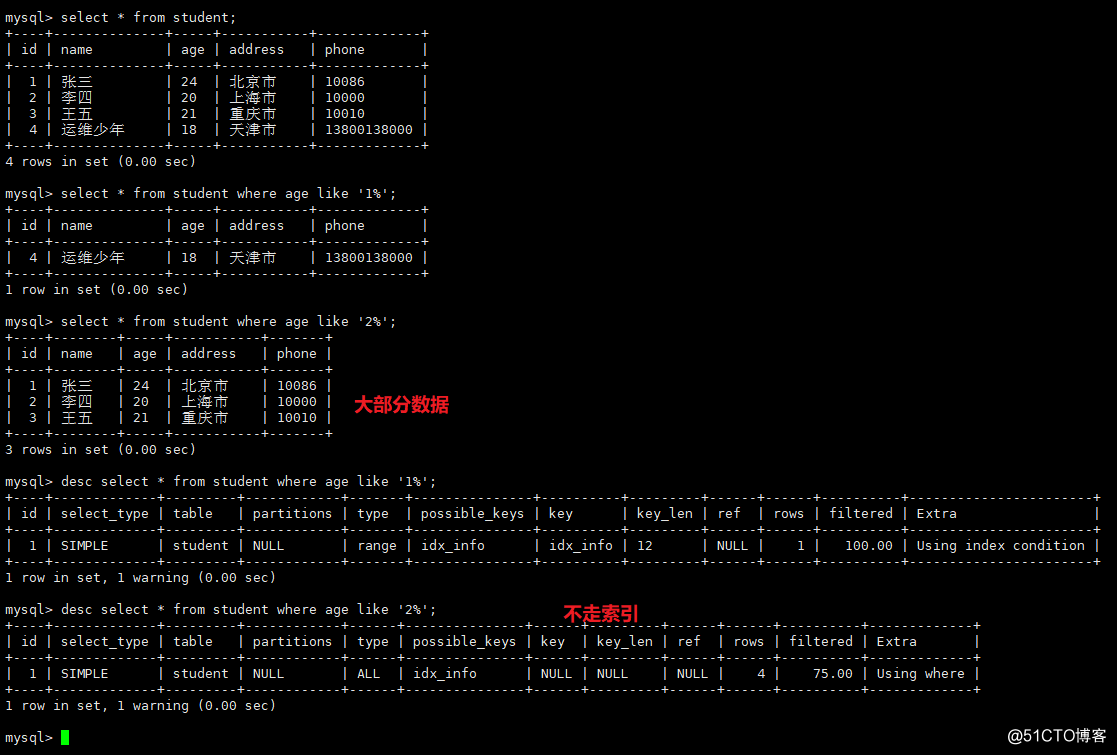
。3)クエリ条件インデックス列の関数に属しているか、インデックス列で操作を実行すると、操作に(+- /!など)が
含まれます間違った例:学生ID-1 = 2
から選択;正しい例:学生ID = 3から*を選択; 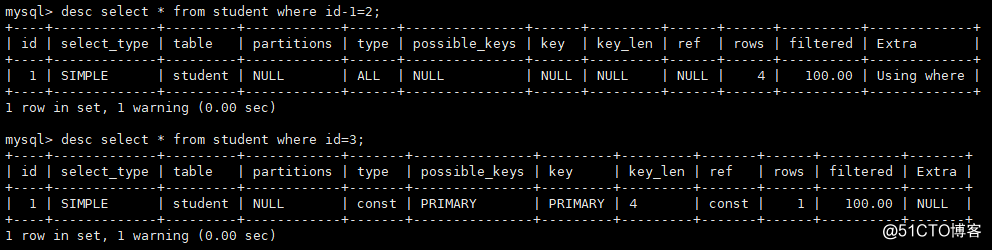
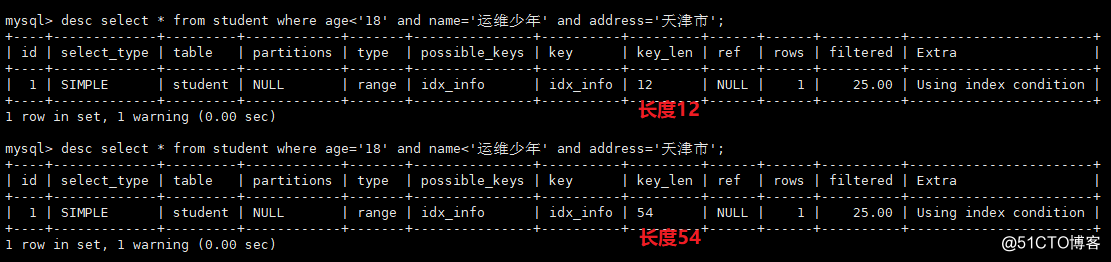
4)暗黙の変換により、インデックスが失敗します。この点は真剣に受け止められる必要があり、この間違いはよくあります。charが定義されている場合、クエリ時に数値型が使用されます。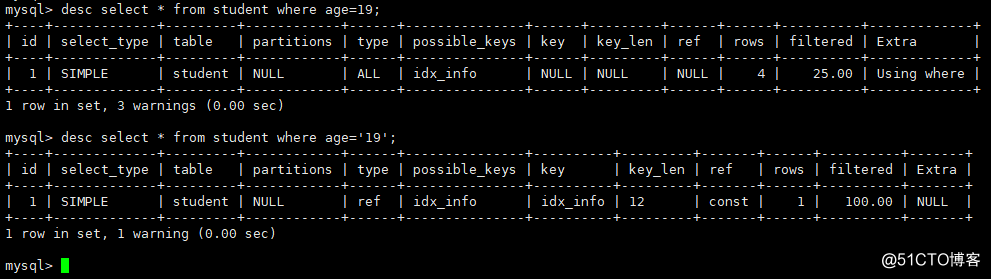
5)入っていない場合は補助インデックスを取りません。またはまたはinをユニオンに変更できます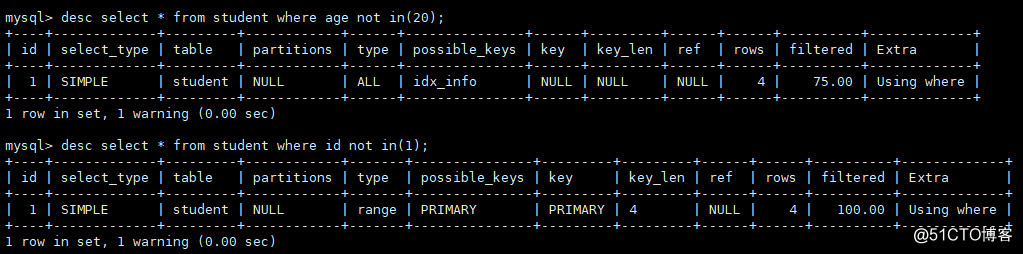
6)「%_」がパーセント記号の前に表示されないように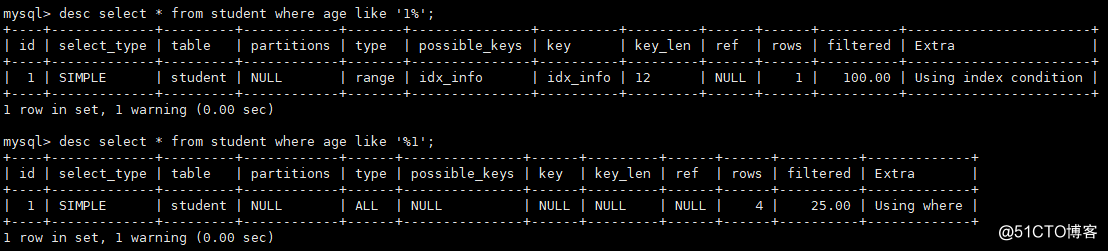
複数列インデックスの補足(ジョイントインデックス)
複数の列を使用してインデックスを結合しますidx(age、name、address)
有効なインデックス:年齢年齢、名前年齢、名前、住所(年齢で始まり連続)
無効なインデックス:名前住所名前、住所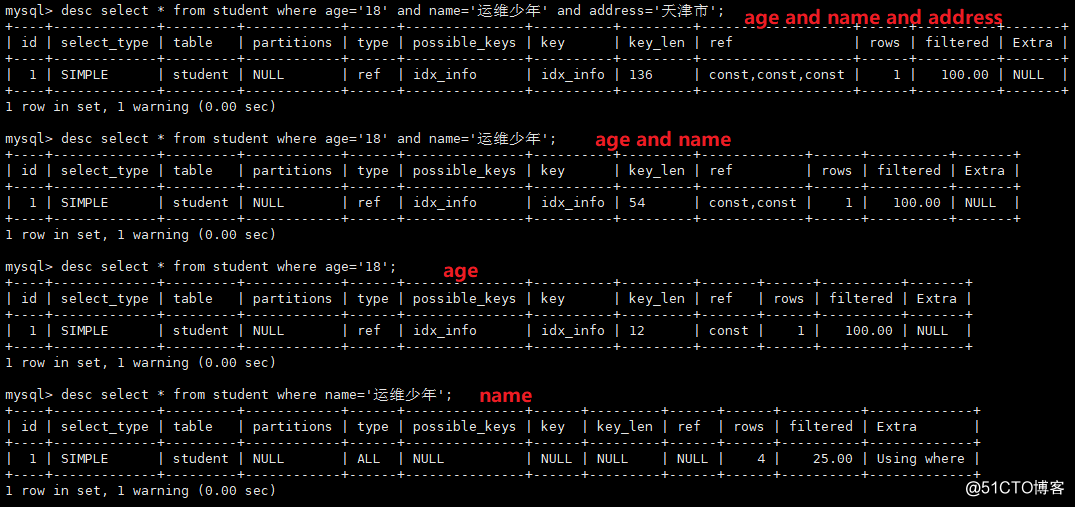
インデックスは等しくなることしかできず、範囲値をとることはできません。
1、age= and name= and address= #索引能到address
2、age= and name> and address= # 索引能到name
3、age< and name = and address= # 索引能到a