I.はじめに
前回の記事では、VOCデータセットの編成形式について学習しました。独自のデータセットをトレーニングする場合は、VOC形式に従ってデータを編成できます。
もちろん、いくつかのツールが必要になる場合があります。機会があれば、後で説明します。!!
ただし、公式darknetバージョンにyolov3、yolov4必要なデータ形式はこのようなものではなく、変換を行う必要があります。しかし、良いニュースは、いくつかのPythonスクリプトを使用して、フォーマット変換をすばやく完了することができることです。!!
2、yoloのデータ形式
前述のように、yoloのデータ形式はvocのデータ形式とは異なります。これは主に、カテゴリと座標情報の異なる編成に反映されます。つまり、前者は前の記事で説明した.xmlファイルを直接使用してデータを読み取ることはありません。ただし、カテゴリと座標情報を特定の形式.txtで保存するファイルにデータの読み取りを使用します。では、カテゴリと座標情報を保存するためのyoloの特定の形式は何ですか?下記参照:

1つ
.txtは1つの画像に対応し、それらの名前は同じです。
オブジェクトに対応する行。最初の部分はclass_idで、次の4つの数字は
BoundingBoxにあり(中心x坐标,中心y坐标,宽,高)ます。これらの座標は、0から1までの相対座標です。
3、フォーマット変換
したがって、vocのラベル部分のデータ形式はyoloのデータ形式とは異なるため、変換する必要があります。公式のものvoc_label.pyを使用して変換を行うことができます。何に注意を払うべきかについて簡単に話しましょう!!!
1.最初に、以前にvocデータセットを取得し、それをVOCdevkitフォルダーに保存したと想定します。このフォルダの下には、VOC2007サブフォルダまたはVOC2012サブフォルダ、あるいはその両方があります。でVOC2007且つVOC2012その下方に前記物品上に格納されているAnnotations、ImageSets和JPEGImagesようなサブフォルダとして。((トレーニングの検証とテストのデータセットはダウンロード時に分離されますが、それらのイメージ名とxmlファイル名は連続しています。つまり、互いに同じ名前がないため、すべてのイメージが直接混合されていることに注意してください。したがって、すべてのtrain、val、およびtestデータを一度に変換する場合は、ダウンロードしたテストデータセット内の同じ名前のフォルダー内のファイルを、トレーニング検証データセット内の同じ名前のフォルダーにコピーするだけです。)。
実際Main、フォルダ内の他のファイルは使用されておらず、下の図のファイルのみを保持しても問題ありません。
2、voc_label.pyスクリプトファイルとあなたのVOCdevkit次のレベルに同じパス上のフォルダー。
3.実際の状況に応じてコードを変更します。
- 1つ目は、コード内の場所
setsを使用する必要setsがあります。たとえば、次のコードは、setsどの値を設定する必要があるかを理解するために使用する必要があります。実際、これはフォルダーの名前とパスに密接に関連しています。
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'
%(year, image_set)).read().strip().split()
のでVOCdevkit1つだけあるVOC2007サブフォルダの下の私のファイルは、そこにある下のファイルVOCdevkit/VOC2007/ImageSets/Mainのパスtrain.txt、val.txtおよびtest.txtすべてのカテゴリ(またはすべての画像)でトレーニング、検証、およびテストのために使用されている画像の名前が格納されています。だから、私のsets設定はになりましたsets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]。
- 2つ目は
classes、データセットに含まれるさまざまなカテゴリです。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'),('2007', 'test')]
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus",
"car", "cat", "chair", "cow", "diningtable", "dog", "horse",
"motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text),
float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'
%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'
%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
4.を実行するvoc_label.pyと、最後にVOCdevkitフォルダの同じレベルのディレクトリに生成さ2007_train.txt,2007_val.txt,2007_test.txtれ、VOCdevkit/VOC2007パスの下にlabelフォルダが生成されます。

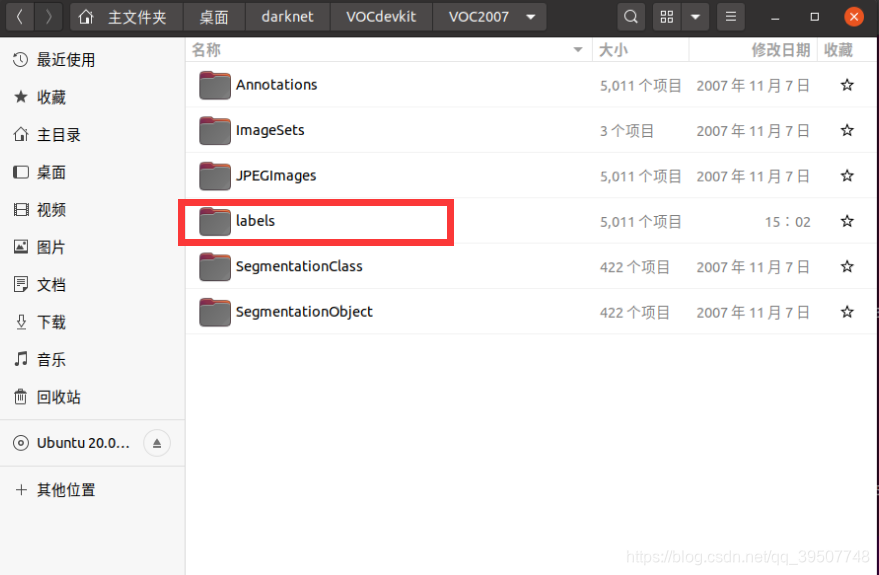
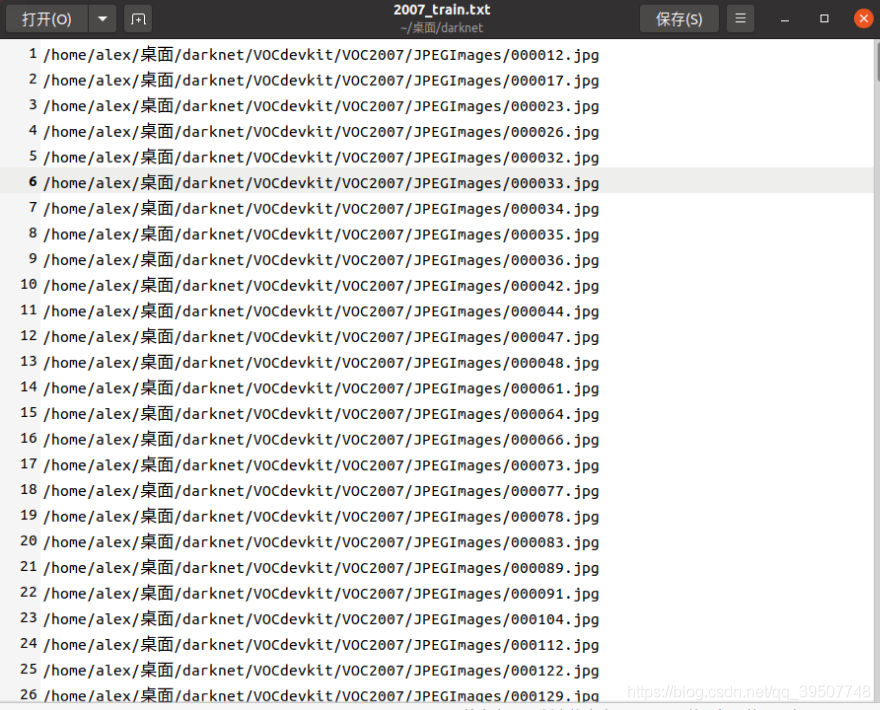
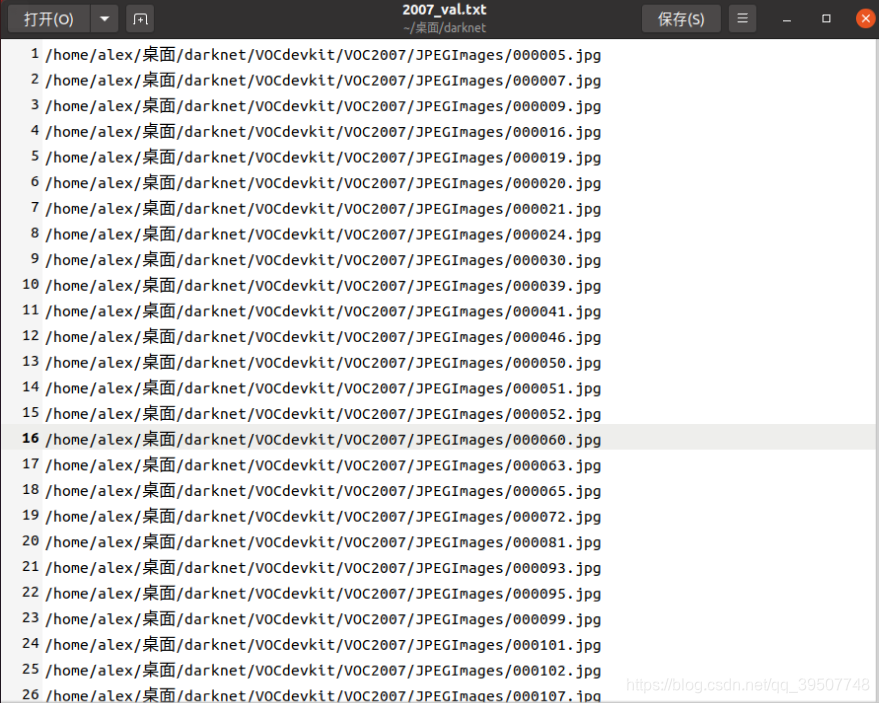
では、上記で生成されたファイルの具体的な内容は何ですか?
2007_train.txt,2007_val.txt,2007_test.txt
格納され、以下に示すようにtrain.txt、val.txt、test.txtファイル名のフルパスは、画像に格納されています。そのtrain.txt、val.txt、test.txtフルパス名に店内だけプット絵に比べて、他の数の点で、対応する絵はまったく同じです。
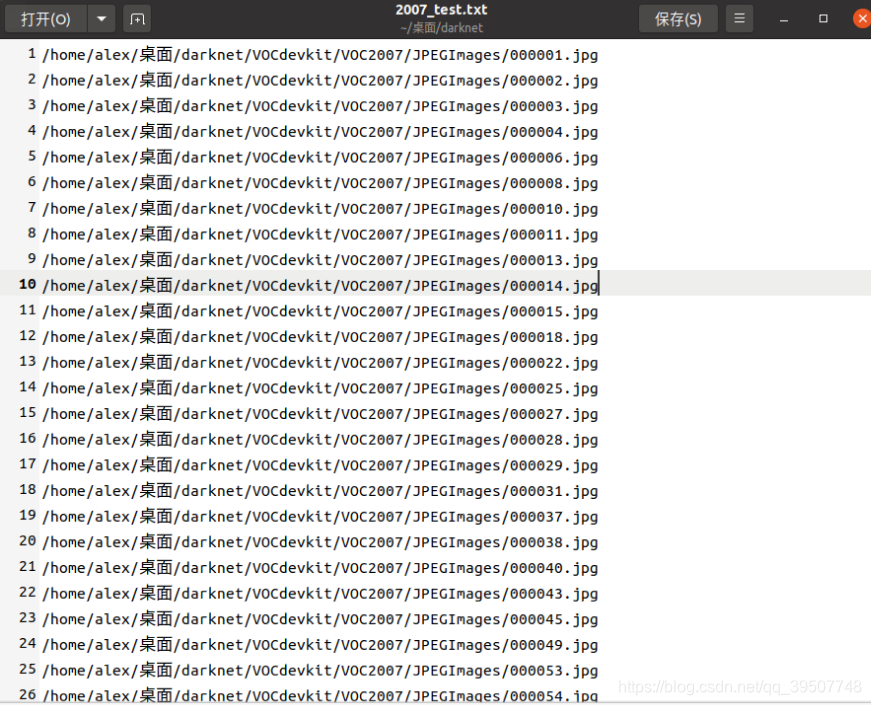
labels文件夹
このフォルダに保存されているファイル.txtは、すべての画像(トレーニング+検証+テスト)、1つの画像と1つのファイルに対応しており、名前はすべて同じです。各ファイルに保存されるのは、以下に示すように、カテゴリと座標情報です。
4、まとめ
フォーマットされたデータセットをフォーマットにvoc_label.py変換することによって、いくつかの新しい再編成されたファイルが生成されることはすでに知っていますが、これらのファイルはどのように使用する必要がありますか?トレーニングの使い方については、次の記事までお待ちください!上記のコンテンツがお役に立てば幸いです。VOCyolo