Webクローラー
1Webクローラーの前奏曲
1.1Webクローラーコースのコンテンツのガイド
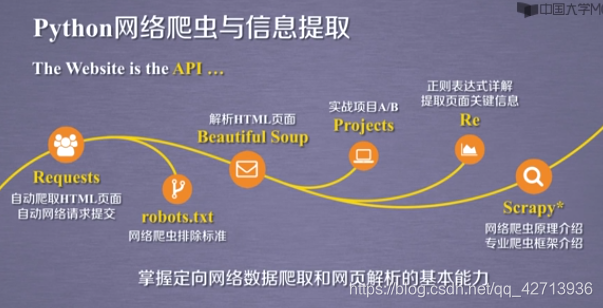
1.2Python言語開発ツールの選択

このレッスンでは、主に次の4種類を使用します

。PythonのIDLEは、Pythonに付属するデフォルトの一般的に使用されるエントリーレベルのオーサリングツールです。
2Webクローラーのルール
2.1Requestsライブラリの使用を開始する
2.1.1リクエストのインストール方法
Requestsライブラリ(http://www.python-requests.org)は、最高のクロールサードパーティライブラリとして認識されています。2つの特徴があります。
- シンプル
- 非常に簡潔で、1行のコードでも、Webページから対応するリソースを取得できます。
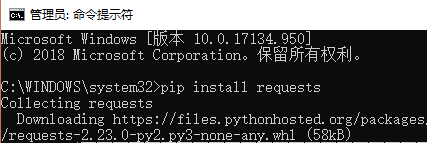
インストール方法:管理者としてコマンド
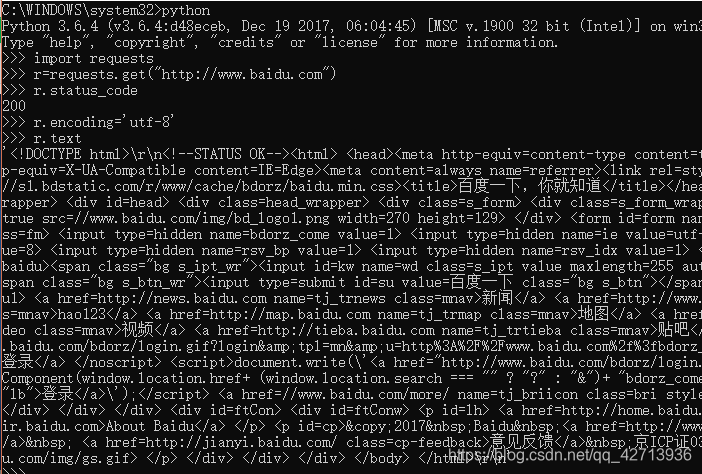
テストを実行します:

2.1.2リクエストライブラリのget()メソッド

Pythonの大文字と小文字の区別

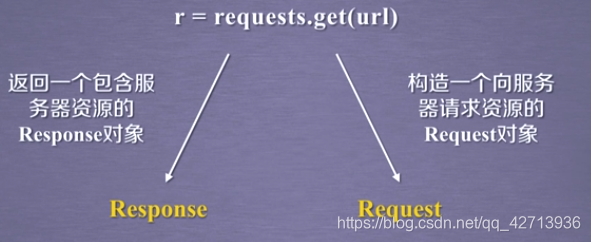
requestメソッドは
Requestsライブラリをカプセル化するために使用され、合計7つの一般的なメソッドを提供します

。requestメソッドは基本メソッドであり、他の6つのメソッドはr.status_codeを達成するためにrequestメソッドを呼び出すことを提供します。ステータスコードを確認します。リクエストの。200の場合は、返品が成功したことを意味します。
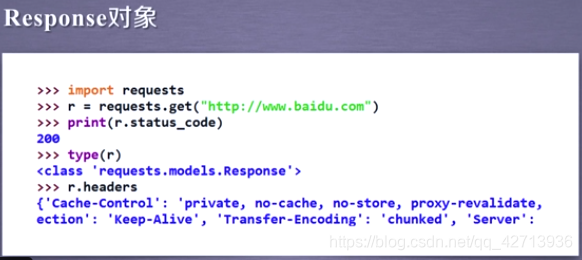
r.headers:ページのヘッダー情報を取得します。Response
オブジェクトには、サーバーから返されたすべての情報とサービスから要求された要求情報が含まれます

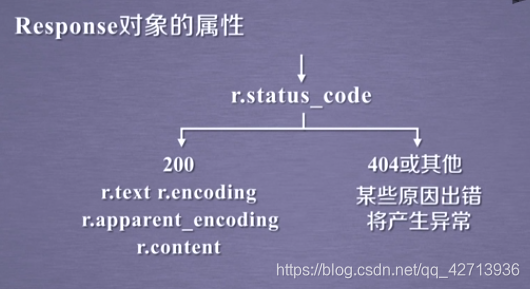


。ネットワーク上のリソースはエンコードされています。エンコードがない場合、読み取り不能になります。
.r.apparent_encodingは、r.encodingよりも読みやすく正確です
2.1.3Webページをクロールするための一般的なコードフレームワーク
GETをすることができ、正確かつ確実にクロール。ネットワーク接続が危険で、例外処理は非常に重要であるため、

。コンテンツを取得するURLリクエストを送信してから、全体のプロセスの例外:タイムアウト
のconnecttimeout:ちょうど、リモートサーバーに接続する


共通コードフレームワークにより、クロールがより安定し、より効果的で信頼性が高くなります
2.1.4HTTPプロトコルとRequestsライブラリメソッド
HTTPプロトコル

ユーザーがリクエストを開始し、サーバーが応答します。
ステートレス要求は、最初と2番目の間に相関関係がないことです。
アプリケーション層プロトコルは、プロトコルがtcpプロトコル(?)の上で機能することを意味します。


これは、ファイルのパスに存在することを除いて、ファイルのパスと同等です。

Requestsライブラリ関数によって提供されるインターネット

HTTPプロトコルは、URLを介してリソースを検索し、一般的に使用される6つの方法でリソースを管理します。各操作は独立しており、ステートレスです
。HTTPプロトコルの世界では、ネットワークチャネルとサーバーはブラックボックスです。彼が見ることができるのは、URLとそれに対応するURLの操作です。

ライブラリメソッドをリクエストします(post()、put())


トラフィックが非常に少ないネットワークリソースの要約情報を取得します
リクエストpost()メソッドのタイプが異なり、得られる結果も異なります:
1.2 
。

2.1.2リクエストライブラリの主なメソッドの分析
リクエスト


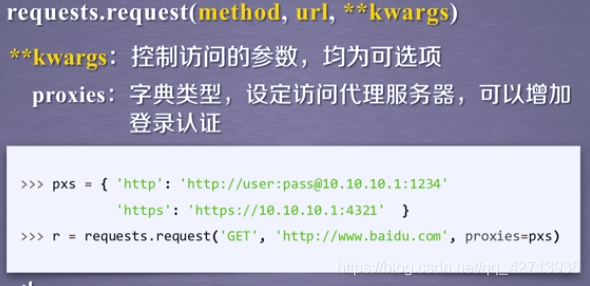
オプション:サーバーがカスタマーサービスとやり取りできるサービスからいくつかのパラメーターを取得します。これはリソースの取得に直接関係しないため、あまり使用されません。


サーバーへのデータの送信

も一般的なデータ送信です

カスタムHTTPヘッダー
Chrome / 10 :Chromeの10番目を表し
ますこのバージョンは、サーバーへのアクセスを送信するために任意のブラウザーをシミュレート



し、ユーザーがWebページをクロールした元のIPアドレスを非表示にすることができます

取得する

頭

役職

置く

パッチ

削除
総括する
なぜこのように設計されているのですか?最後の6つのメソッドでは、特定のパラメーターを使用する必要があるメソッドがあるため、これらのパラメーターは表示定義パラメーターとしてパラメーターに入れられ、その他のパラメーターはオプションのパラメーターに入れられます。get
メソッドは、コンテンツをクロールするために最も一般的に使用されます。サーバー。コンテンツを送信せずに
2.1.3まとめ

getrawlerを
使用するheadを使用してより大きなリソースの概要を取得する


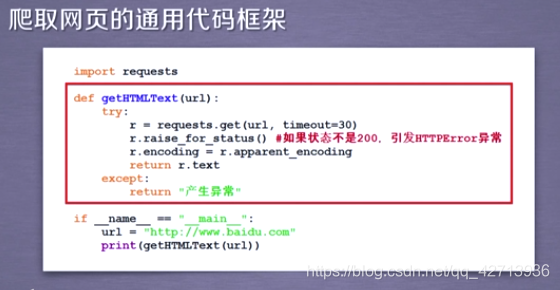
import requests
import time
def getHTMLText(url):
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
except:
print("failed")
if __name__=="__main__":
start=time.perf_counter()
for i in range(100):
getHTMLText("http://www.baidu.com")
end=time.perf_counter()
print("用时%.5f秒"%(end-start))

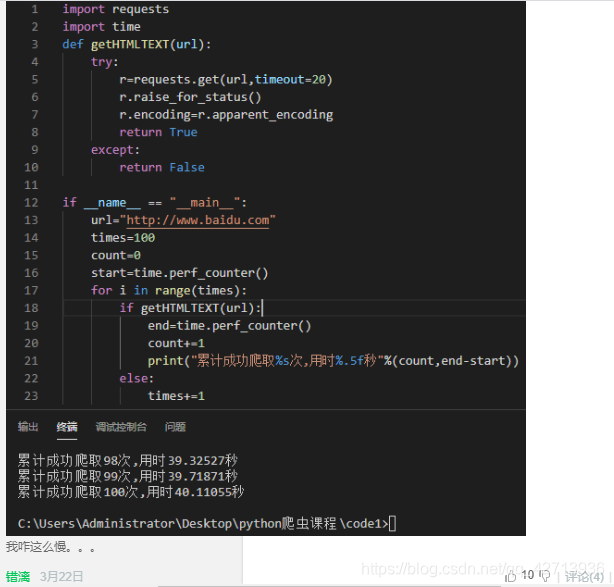
100回クロールに成功したかどうかは考慮していません。。。
2.2Webクローラーの「海賊も盗難」
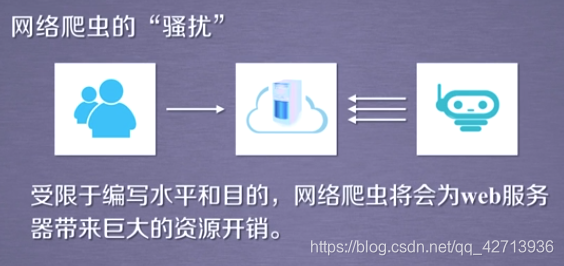
2.2.1Webクローラーによって引き起こされる問題





2.2.2ロボットプロトコル


「?」「popmディレクトリ内のhtmlファイル」は許可されていません。。。

ロボットプロトコルがないということは、任意にクロールできることを意味します
2.2.3ロボット契約を遵守する方法



つまり、訪問は少ないです
2.3リクエストの実際の戦闘ライブラリWebクローラー(5つの例)
クローラーの観点からWebコンテンツを見る
2.3.1JD製品ページのクロール
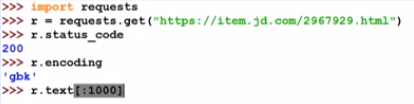
r.encoding:エンコーディング情報はHTTPヘッダーから解析でき、JD.comがエンコーディングを提供します
import requests
import time
def getHTMLText(url):
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[:1000])
except:
print("failed")
if __name__=="__main__":
getHTMLText("https://item.jd.com/100006349587.html")
実際に飛び出したのはログインでした

2.3.2Amazon商品ページのクロール
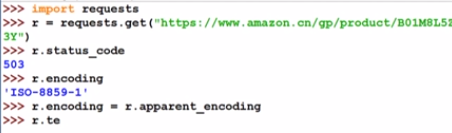

クロールバックできるということは、ネットワークの問題ではないことを意味します。
つまり、ウェブサイトがクローラーのリクエストを拒否しました。
レスポンスオブジェクトrにはリクエストリクエストが含まれている
ため、ヘッダー情報を変更する必要があります。

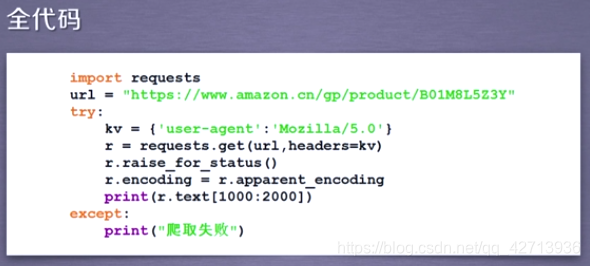
2.3.3 Baidu360検索キーワードの送信

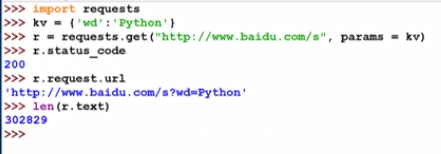
内容を分析した後、それについて話します

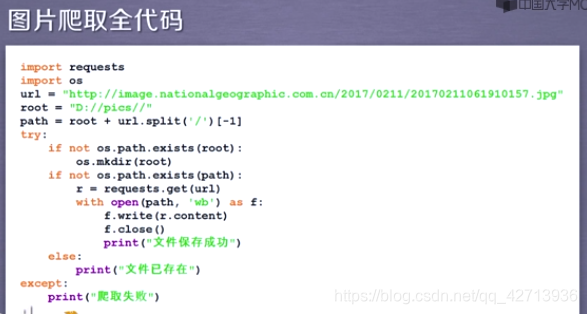
2.3.4ネットワーク画像のクロールと保存

写真はバイナリ形式ですが、ファイルとして保存するにはどうすればよいですか?
- カスタム名
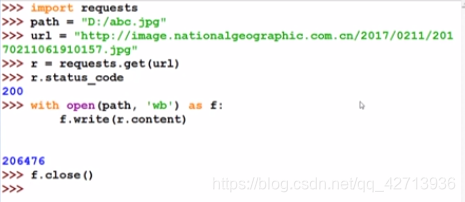
- 元の名前
2.3.5IPアドレス属性の自動クエリ
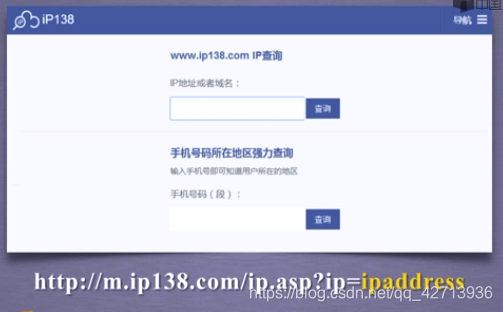
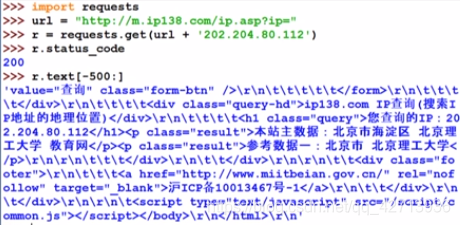
r.text [-500:]などのr.textのサイズを制限してみてください。そうしないと、アイドルの使用に影響します。
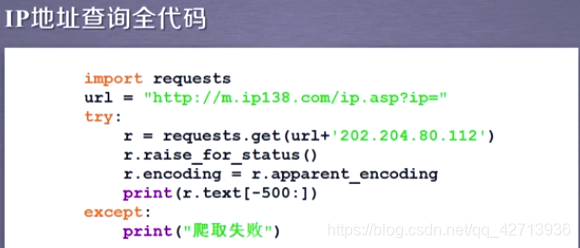
ボタンを押した後にバックグラウンドに送信されるURLの形式を知っている限り、シミュレーション送信をコーディングできます