Pythonは、スーパーロトの過去の宝くじデータをクロールして分析します
ブロガーは、クローラーの初心者として、リクエストとbeautifulsoupライブラリを使用して今回のデータをクロールします
ウェブサイトをクロールする:http://datachart.500.com/dlt/history/history.shtml —500彩票所属
(分析の結果、ウェブサイトのソースコードはページジャンプで別のデータを見つけることではないことがわかりました。 F12列からネットワークを見つけて、すべての過去の宝くじの結果を実際に保存しているWebページを見つけることができます)
示されているように: クローラー部分:
クローラー部分:
from bs4 import BeautifulSoup #引用BeautifulSoup库
import requests #引用requests
import os #os
import pandas as pd
import csv
import codecs
lst=[]
url='http://datachart.500.com/dlt/history/newinc/history.php?start=07001&end=21018'
r = requests.get(url)
r.encoding='utf-8'
text=r.text
soup = BeautifulSoup(text, "html.parser")
tbody=soup.find('tbody',id="tdata")
tr=tbody.find_all('tr')
td=tr[0].find_all('td')
for page in range(0,14016):
td=tr[page].find_all('td')
lst.append([td[0].text,td[1].text,td[2].text,td[3].text,td[4].text,td[5].text,td[6].text,td[7].text])
with open("Lottery_data.csv",'w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['期号','号码1', '号码2', '号码3', '号码4', '号码5', '号码6', '号码7'])
writer.writerows(lst)
csvfile.close()
データ分析:
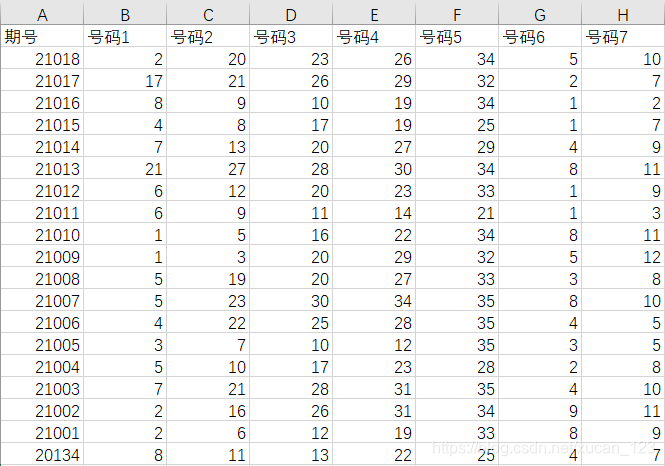
最初にすべての宝くじ番号と対応する当選番号を表示します
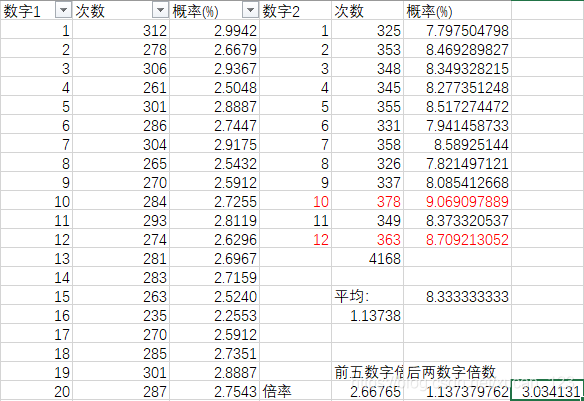
次に、5 + 2モードを使用して、最も頻度の高い2つのデータの組み合わせのグループをそれぞれ分析し、この組み合わせに勝つ確率を、平均勝率の3倍として漠然と計算しました(最終結果は直接表示されず、マークが付けられます)。 csvファイルに赤で表示)
ソースコードと対応するcsvファイル
リンク:https
://pan.baidu.com/s/16wEHnpvrzMsK1ijW0AkhiA抽出コード:nmjx
ヒント:ワンクリックトリプル接続をありがとうございます〜さらに、ブロガーに直接欠陥を指摘することができます!!