文字列とタプルは非常に似ており、一度定義すると簡単に変更することはできません。
変更する必要がある場合は、スライスと連結を
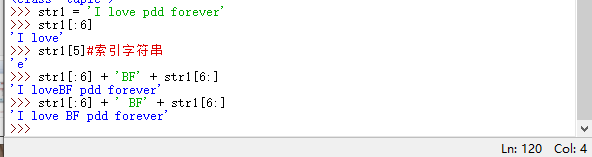
使用して、古い文字列str1がそのまま残り、割り当て後に上書きされるようにすることができます。Pythonのガベージコレクションメカニズムは、タグのない文字列を削除します。

文字列の組み込みメソッド
| 方法 | 意味 |
|---|---|
| Capitalize() | 文字列の最初の文字を大文字に変更し、他のすべての文字を小文字に変更します |
| casefold() | 新しい文字列のすべての文字が小文字になります |
| center(width、fillchar = '') | 中央に配置された新しい文字列を返します(幅<=文字列の長さ、新しい文字列=元の文字列、幅>文字列の幅、すべての文字が中央に配置され、左右はfillcharパラメータで指定された文字で埋められます) |
| count(sub [、start [、end]]) | 文字列内の重複しないsubの出現回数を返します。オプションのパラメータstartおよびendは、開始位置と終了位置を指定するために使用されます。 |
| extendswith(suffix [、start [、end]]) | 文字列が接尾辞で指定された部分文字列で終わる場合はTrueを返し、そうでない場合はFalseを返します。オプションのパラメータstartとendは、開始位置と終了位置を指定するために使用されます。 |
| expandtabs([tabsize = 8]) | スペースを使用してタブを置き換える新しい文字列を返します。tabsizeパラメータが指定されていない場合、デフォルトで1タブ= 8スペース |
| find(sub [、start [、end]]) | 文字列内の部分部分文字列を見つけて、一致の最小インデックス値を返します。オプションのパラメータstartとendは、開始位置と終了位置を指定するために使用されます。部分文字列が一致しない場合は、-1を返します。 |
| join(iterable) | 複数の文字列を連結して新しい文字列を返します。このメソッドを呼び出す文字列を区切り文字として使用し、iterableパラメータで指定された各文字列の中央に挿入します。 |
| encode(encoding = 'utf-8'、errors = 'strict') | 文字列をencodingパラメーターで指定されたエンコード形式でエンコードします。errorsパラメーターは、エンコードエラーが発生したときの解決策を指定します。デフォルトの「strict」は、エラーが発生した場合にUnicodeEncodeErrorがスローされることを意味します。その他の使用可能なパラメーター値は、「ignore」、「replace」、および「xmlcharrefreplace」です。 |
| format(* args、** kwargs) | 新しいフォーマットされた文字列を返します。位置パラメータ(args)とキーワード引数(kwargs)を使用して置き換えます |
| format_map(mapping) | 新しいフォーマットされた文字列を返します。マッピングパラメータ(マッピング)を使用して置き換えます |
| index(sub [、start [、end]]) | 文字列内の部分部分文字列を見つけて、一致の最小インデックス値を返します。オプションのパラメータstartとendは、開始位置と終了位置を指定するために使用されます。部分文字列が一致しない場合、ValueError例外がスローされます。 |
| isalnum() | 文字列に少なくとも1つの文字があり、すべての文字が文字または数字の場合はTrueを返し、そうでない場合はFalseを返します。 |
| isalpha() | 文字列に少なくとも1つの文字があり、すべての文字が文字である場合はTrueを返し、そうでない場合はFalseを返します。 |
| isascii() | 文字列内のすべての文字がASCIIの場合はTrueを返し、そうでない場合はFalseを返します。ASCII文字のエンコード範囲はU + 0000〜U + 007Fで、空の文字列もASCIIです。 |
| isdecimal() | 文字列に少なくとも1文字があり、すべての文字が10進数の場合は、Trueを返します。それ以外の場合は、Falseを返します。 |
| isdigit() | 文字列に少なくとも1つの文字があり、すべての文字が数字の場合はTrueを返し、そうでない場合はFalseを返します。 |
| 識別子() | 文字列が有効なPython識別子である場合はTrueを返し、そうでない場合はFalseを返します。keyword.iskeyword(s)を呼び出して、文字列が予約済み識別子( "if"や "for"など)であるかどうかを確認します。 |
| islower() | 文字列に大文字と小文字が区別される英語の文字が少なくとも1つ含まれていて、これらの文字がすべて小文字の場合はTrueを返し、そうでない場合はFalseを返します。 |
| isnumeric() | 文字列に少なくとも1つの文字があり、すべての文字が数字の場合はTrueを返し、そうでない場合はFalseを返します。 |
| 印刷可能() | 文字列が印刷可能な場合はTrueを返し、そうでない場合はFalseを返します。 |
| isspace() | 文字列に少なくとも1つの文字があり、すべての文字がスペースの場合はTrueを返し、そうでない場合はFalseを返します。 |
| リスト() | 文字列がタイトル付き文字列の場合(すべての単語が大文字で始まり、残りの文字は小文字です)、Trueを返します。それ以外の場合は、Falseを返します。 |
| isupper() | 文字列に大文字と小文字が区別される英語の文字が少なくとも1つ含まれ、これらの文字がすべて大文字の場合はTrueを返し、そうでない場合はFalseを返します |
| join(iterable) | 複数の文字列を連結して新しい文字列を返します。このメソッドを呼び出す文字列を区切り文字として使用し、iterableパラメータで指定された各文字列の中央に挿入します。 |
| 明るい(幅) | 文字が左揃えの新しい文字列を返します(幅<=文字列の長さ、新しい文字列=元の文字列、幅>文字列の幅、すべての文字が左揃えで、右側はfillcharパラメータで指定された文字で埋められます) |
| lower() | すべての英字を小文字に変換した新しい文字列を返します |
| lstrip(chars = None) | 左の空白文字が削除された新しい文字列を返します。charsパラメータを使用して、削除する文字列を指定できます。 |
| パーティション(9月) | 文字列内のsepパラメータで指定された区切り文字を検索します。見つかった場合は3タプル( 'sepの前の部分'、 'sep'、 'sepの後の部分')を返します。見つからない場合は( '元の文字列'、' '、' ') |
| removeprefix(prefix) | prefixパラメータで指定されたプレフィックス部分文字列が存在する場合は、プレフィックスが削除された新しい文字列を返します。存在しない場合は、元の文字列のコピーを返します。 |
| removesuffix(suffix) | 接尾辞パラメーターで指定された接尾辞部分文字列がある場合は、接尾辞が削除された新しい文字列を返します。存在しない場合は、元の文字列のコピーを返します。 |
| replace(old、new、count = -1) | 返回一个将所有 old 参数指定的子字符串替换为 new 的新字符串;count 参数指定替换的次数,默认是 -1,表示替换全部 |
| rfind(sub[, start[, end]]) | 在字符串中自右向左查找 sub 子字符串,返回匹配的最高索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,返回 -1 |
| rindex(sub[, start[, end]]) | 在字符串中自右向左查找 sub 子字符串,返回匹配的最高索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,抛出 ValueError 异常 |
| rjust(width, fillchar=’ ') | 返回一个字符右对齐的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符右对齐,左侧使用 fillchar 参数指定的字符填充) |
| rpartition(sep) | 在字符串中自右向左搜索sep参数指定的分隔符,如果找到,返回一个 3 元组 (‘在sep前面的部分’, ‘sep’, ‘在sep后面的部分’);如果未找到,则返回 (’’, ‘’, ‘原字符串’) |
| rsplit(sep=None, maxsplit=-1) | 将字符串自右向左进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit 参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制 |
| rstrip(chars=None) | 返回一个去除右侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串 |
| split(sep=None, maxsplit=-1) | 将字符串进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制 |
| splitlines(keepends=False) | 将字符串按行分割,并将结果以列表的形式返回;keepends 参数指定是否包含换行符,True 是包含,False 是不包含 |
| startswith(prefix[, start[, end]]) | 如果存在 prefix 参数指定的前缀子字符串,则返回 True,否则返回 False;可选参数 start 和 end 用于指定起始和结束位置;prefix 参数允许以元组的形式提供多个子字符串 |
| strip(chars=None) | 返回一个去除左右两侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串 |
| swapcase() | 返回一个大小写字母翻转的新字符串 |
| title() | 返回标题化(所有的单词都是以大写开始,其余字母均小写)的字符串。 |
| translate(table) | 返回一个根据 table 参数转换后的新字符串;table 参数应该提供一个转换规则(可以由 str.maketrans(‘a’, ‘b’) 进行定制,例如 “FishC”.translate(str.maketrans(“FC”, “15”)) -> ‘1ish5’) |
| upper() | 返回一个所有英文字母都转换成大写后的新字符串 |
| zfill(width) | 返回一个左侧用 0 填充的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符右对齐,左侧使用 0 进行填充) |
capitalize():将字符串的第一个字符修改为大写,其他字符全部改为小写

casefold() :新字符串的所有字母变为小写

center(width, fillchar=’ ') : 返回一个字符居中的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符居中,左右使用 fillchar 参数指定的字符填充)

count(sub[, start[, end]]): 返回 sub 在字符串中不重叠的出现次数,可选参数 start 和 end 用于指定起始和结束位置

endswith(suffix[, start[, end]]): 如果字符串是以 suffix 指定的子字符串为结尾,那么返回 True,否则返回 False;可选参数 start 和 end 用于指定起始和结束位置

expandtabs([tabsize=8]) :返回一个使用空格替换制表符的新字符串,如果没有指定 tabsize 参数,那么默认 1 个制表符 = 8 个空格

find(sub[, start[, end]]) :在字符串中查找 sub 子字符串,返回匹配的最低索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,返回 -1

index(sub[, start[, end]]) :在字符串中查找 sub 子字符串,返回匹配的最低索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,抛出 ValueError 异常
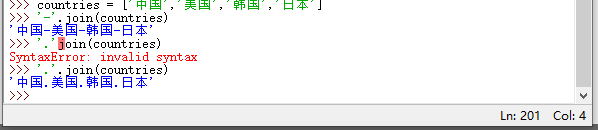
join(iterable) :连接多个字符串并返回一个新字符串;以调用该方法的字符串作为分隔符,插入到 iterable 参数指定的每个字符串的中间;
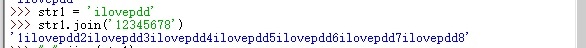
join()方法代替加号来拼接字符串
istitle():如果字符串是标题化字符串(所有的单词都是以大写开始,其余字母均小写)则返回 True,否则返回 False

lstrip(chars=None):返回一个去除左侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串
rstrip(chars=None):返回一个去除右侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串

partition(sep) 在字符串中搜索 sep 参数指定的分隔符,如果找到,返回一个 3 元组 (‘在sep前面的部分’, ‘sep’, ‘在sep后面的部分’);如果未找到,则返回 (‘原字符串’, ‘’, ‘’)
replace(old, new, count=-1) 返回一个将所有 old 参数指定的子字符串替换为 new 的新字符串;count 参数指定替换的次数,默认是 -1,表示替换全部

split(sep=None, maxsplit=-1) 将字符串进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制

strip(chars=None) 返回一个去除左右两侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串


swapcase() 返回一个大小写字母翻转的新字符串

translate(table) 返回一个根据 table 参数转换后的新字符串;table 参数应该提供一个转换规则(可以由 str.maketrans(‘a’, ‘b’) 进行定制,例如 “FishC”.translate(str.maketrans(“FC”, “15”)) -> ‘1ish5’)

Task
0. 还记得如何定义一个跨越多行的字符串吗(请至少写出两种实现的方法)?
【1】三重引号字符串
【2】转义字符\n

【3】
>>> str3 = ('待卿长发及腰,我必凯旋回朝。'
'昔日纵马任逍遥,俱是少年英豪。'
'东都霞色好,西湖烟波渺。'
'执枪血战八方,誓守山河多娇。'
'应有得胜归来日,与卿共度良宵。'
'盼携手终老,愿与子同袍。')
1. 三引号字符串通常我们用于做什么使用?
三引号字符串不赋值的情况下,通常当作跨行注释使用
2. file1 = open( 'C:\ windows \ temp \ readme.txt'、 'r')は、テキストファイル「C:\ windows \ temp \ readme.txt」を読み取り専用モードで開くことを意味しますが、実際にはこのステートメントはエラーを報告します、あなたは理由を知っていますか?どのように変更しますか?
「\ T」と「\ r」は、それぞれ「水平タブ(TAB)」と「キャリッジリターン」を表します。
>>> file1 = open(r'C:\windows\temp\readme.txt', 'r')
3.文字列があります:str1 = '<a href="http://www.fishc.com/dvd" target="_blank"> Fish Cリソースパッケージング'、部分文字列を抽出する方法: 'www.fishc。 com '
>>> str1 = '<a href="http://www.fishc.com/dvd" target="_blank">鱼C资源打包</a>'
>>> str1[16:29]

4.スライス操作の指標値として負の数を使用した場合、3番目の質問に従って結果を正しく視覚的に検出できますか?
>>> str1 = '<a href="http://www.fishc.com/dvd" target="_blank">鱼C资源打包</a>'
>>> str1[-45:-32]

5.問題の文字列です。3。次の文には何が表示されますか?
>>> str1[20:-36]
「fishc」
6. IQが150を超える魚油のみがこの文字列のロックを解除できると言われています(意味のある文字列に戻されます):str1 = 'i2sl54ovvvb4e3bferi32s56h; $ c43.sfc67o0cm99'

(よくわかりません、?????)
7.パスワードセキュリティチェックのコードを書いてください:check.py(考えて...)
# 密码安全性检查代码
#
# 低级密码要求:
# 1. 密码由单纯的数字或字母组成
# 2. 密码长度小于等于8位
#
# 中级密码要求:
# 1. 密码必须由数字、字母或特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)任意两种组合
# 2. 密码长度不能低于8位
#
# 高级密码要求:
# 1. 密码必须由数字、字母及特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)三种组合
# 2. 密码只能由字母开头
# 3. 密码长度不能低于16位
