はじめに:クラウドネイティブコミュニティアクティビティ--- Kubernetesソースコードのフェーズ1と第2週の分析
今週は、K8Sソースコード研究所の第1フェーズの第2週です。学習の内容は、インフォーマーメカニズムを学習することです。この記事は、このトピックから始まります。
今週は勉強会の学長がとても忙しかったので、このコースを来週の終わりまで延期しました。すべて同じです。他の事柄で計画が破られる可能性がありますが、最終的には対応するメインライン、それは何も問題ではありません。オープンソースに参加するのと同じように、最初のオープンソースはほんの始まりに過ぎません。必要なのは持続できることであり、これはしばしば非常に重要です。
さて、テキストを始めましょう。
この記事のトピック:
- インフォーマーメカニズムアーキテクチャ設計の概要
- リフレクターの理解
- DeltaFIFOの理解
- インデクサの理解
リソースのコンテンツが関係している場合、この記事ではデプロイメントリソースを使用して関連するコンテンツを説明します。
インフォーマーメカニズムアーキテクチャ設計の概要
以下は、私が理解に基づいて作成したデータフロー図であり、グローバルな観点からデータの全体的な傾向を示しています。
点線は、コード内のメソッドを表しています。
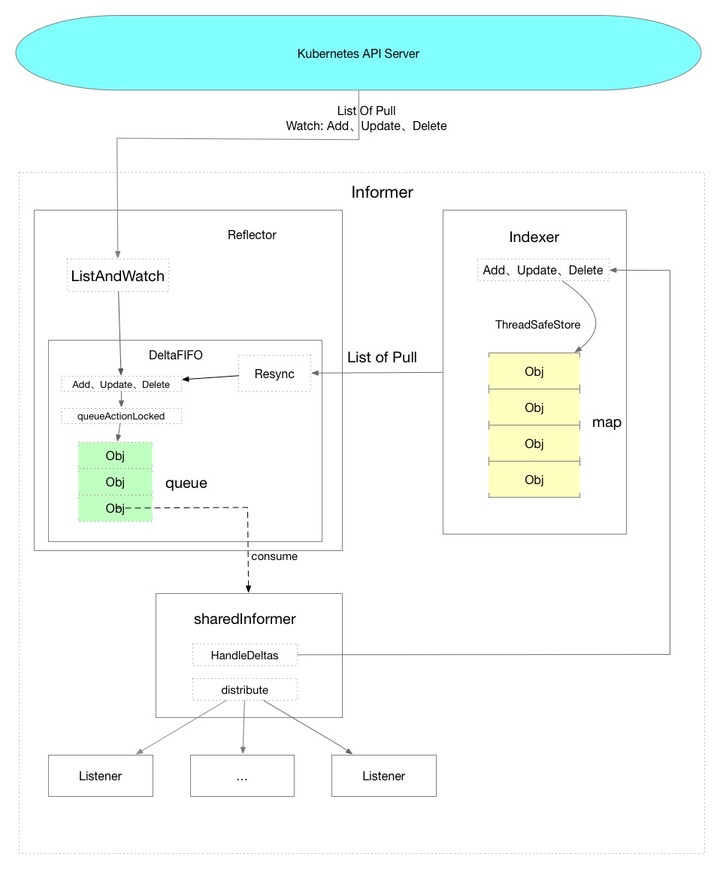
結論について話させてください:
Informerメカニズムを介してデータを取得する場合、リソースに対応するすべてのオブジェクトは初期化中にKubernetes APIサーバーから取得され、APIサーバーによってプッシュされたデータのみがWatchメカニズムを介して受信され、データは受信されません。 APIサーバーからアクティブにプルされます。ローカルキャッシュ内のデータを直接使用して、APIサーバーへの負荷を軽減します。
監視メカニズムはHTTPチャンクの実装に基づいており、長い接続を維持します。これは、要求されたデータの量を減らすための最適化ポイントです。2番目の最適化ポイントはSharedInformerです。これにより、同じリソースで同じInformerを使用できます。たとえば、v1バージョンのDeploymentとv1beta1バージョンのDeploymentが同時に存在する場合、それらは同じInformerを共有します。
上の図では、Informerが3つの部分に分割されていることがわかります。これは、3つの主要なロジックとして理解できます。
その中で、Reflectorは主にAPIサーバーデータから取得したデータをDeltaFIFOキューに入れ、プロデューサーとして機能します。
SharedInformerは、主にDeltaFIFIOキューからデータを取得してデータを配布し、コンシューマーとして機能します。
最後に、インデクサーはローカルキャッシュのストレージコンポーネントとして存在します。
リフレクターの理解
Reflectorでは、主にRun、ListAndWatch、およびwatchHandlerを確認するだけで十分です。
ソースコードの場所はtools / cache /reflector.goです。
// Ruvn starts a watch and handles watch events. Will restart the watch if it is closed.
// Run will exit when stopCh is closed.
//开始时执行Run,上一层调用的地方是 controller.go中的Run方法
func (r *Reflector) Run(stopCh <-chan struct{}) {
klog.V(3).Infof("Starting reflector %v (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name)
wait.Until(func() {
//启动后执行一次ListAndWatch
if err := r.ListAndWatch(stopCh); err != nil {
utilruntime.HandleError(err)
}
}, r.period, stopCh)
}
...
// and then use the resource version to watch.
// It returns error if ListAndWatch didn't even try to initialize watch.
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
// Attempt to gather list in chunks, if supported by listerWatcher, if not, the first
// list request will return the full response.
pager := pager.New(pager.SimplePageFunc(func(opts metav1.ListOptions) (runtime.Object, error) {
//这里是调用了各个资源中的ListFunc函数,例如如果v1版本的Deployment
//则调用的是informers/apps/v1/deployment.go中的ListFunc
return r.listerWatcher.List(opts)
}))
if r.WatchListPageSize != 0 {
pager.Pa1geSize = r.WatchListPageSize
}
// Pager falls back to full list if paginated list calls fail due to an "Expired" error.
list, err = pager.List(context.Background(), options)
close(listCh)
...
//这一部分主要是从API SERVER请求一次数据 获取资源的全部Object
if err != nil {
return fmt.Errorf("%s: Failed to list %v: %v", r.name, r.expectedTypeName, err)
}
initTrace.Step("Objects listed")
listMetaInterface, err := meta.ListAccessor(li
st)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v: %v", r.name, list, err)
}
resourceVersion = listMetaInterface.GetResourceVersion()
initTrace.Step("Resource version extracted")
items, err := meta.ExtractList(list)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v (%v)", r.name, list, err)
}
initTrace.Step("Objects extracted")
if err := r.syncWith(items, resourceVersion); err != nil {
return fmt.Errorf("%s: Unable to sync list result: %v", r.name, err)
}
initTrace.Step("SyncWith done")
r.setLastSyncResourceVersion(resourceVersion)
initTrace.Step("Resource version updated")
...
//处理Watch中的数据并且将数据放置到DeltaFIFO当中
if err := r.watchHandler(start, w, &resourceVersion, resyncerrc, stopCh); err != nil {
if err != errorStopRequested {
switch {
case apierrs.IsResourceExpired(err):
klog.V(4).Infof("%s: watch of %v ended with: %v", r.name, r.expectedTypeName, err)
default:
klog.Warningf("%s: watch of %v ended with: %v", r.name, r.expectedTypeName, err)
}
}
return nil
}
...
}データの作成は終了しました。2つのポイントだけです。
- 初期化中にAPIサーバーにデータを要求する
- Watchからプッシュされた後続のデータを監視する
DeltaFIFOの理解
最初にデータ構造を見てください。
type DeltaFIFO struct {
...
items map[string]Deltas
queue []string
...
}
type Delta struct {
Type DeltaType
Object interface{}
}
type Deltas []Delta
type DeltaType string
// Change type definition
const (
Added DeltaType = "Added"
Updated DeltaType = "Updated"
Deleted DeltaType = "Deleted"
Sync DeltaType = "Sync"
)キューにはオブジェクトのIDが格納され、アイテムにはObjectIDをキーとして持つオブジェクトのイベントリストが格納されます。
このようなデータ構造を想像してみてください。左側にKey、右側に配列オブジェクトがあり、各要素はtypeとobjで構成されています。
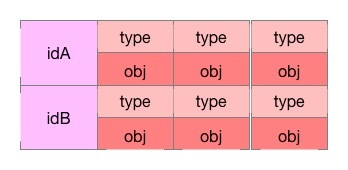
DeltaFIFOは、その名前が示すように、デルタデータを格納する先入れ先出しキューです。これは、ある場所から別の場所にデータを転送するデータ転送ステーションに相当します。
主なコンテンツはqueueActionLocked、Pop、Resyncです
queueActionLockedメソッド:
func (f *DeltaFIFO) queueActionLocked(actionType DeltaType, obj interface{}) error {
...
newDeltas := append(f.items[id], Delta{actionType, obj})
//去重处理
newDeltas = dedupDeltas(newDeltas)
if len(newDeltas) > 0 {
...
//pop消息
f.cond.Broadcast()
...
return nil
}ポップ方式:
func (f *DeltaFIFO) Pop(process PopProcessFunc) (interface{}, error) {
f.lock.Lock()
defer f.lock.Unlock()
for {
for len(f.queue) == 0 {
//阻塞 直到调用了f.cond.Broadcast()
f.cond.Wait()
}
//取出第一个元素
id := f.queue[0]
f.queue = f.queue[1:]
...
item, ok := f.items[id]
...
delete(f.items, id)
//这个process可以在controller.go中的processLoop()找到
//初始化是在shared_informer.go的Run
//最终执行到shared_informer.go的HandleDeltas方法
err := process(item)
//如果处理出错了重新放回队列中
if e, ok := err.(ErrRequeue); ok {
f.addIfNotPresent(id, item)
err = e.Err
}
...
}
}再同期メカニズム:
簡単な要約:ローカルキャッシュインデクサーから取得したデータがDeltaFIFOに置き換えられて、タスクロジックが実行されるたび。
Resyncを開始する場所は、reflector.goのresyncChan()メソッドであり、reflector.goのListAndWatchメソッドの呼び出しが定期的に実行され始めます。
go func() {
//启动定时任务
resyncCh, cleanup := r.resyncChan()
defer func() {
cleanup() // Call the last one written into cleanup
}()
for {
select {
case <-resyncCh:
case <-stopCh:
return
case <-cancelCh:
return
}
//定时执行 调用会执行到delta_fifo.go的Resync()方法
if r.ShouldResync == nil || r.ShouldResync() {
klog.V(4).Infof("%s: forcing resync", r.name)
if err := r.store.Resync(); err != nil {
resyncerrc <- err
return
}
}
cleanup()
resyncCh, cleanup = r.resyncChan()
}
}()
func (f *DeltaFIFO) Resync() error {
...
//从缓存中获取到所有的key
keys := f.knownObjects.ListKeys()
for _, k := range keys {
if err := f.syncKeyLocked(k); err != nil {
return err
}
}
return nil
}
func (f *DeltaFIFO) syncKeyLocked(key string) error {
//获缓存拿到对应的Object
obj, exists, err := f.knownObjects.GetByKey(key)
...
//放入到队列中执行任务逻辑
if err := f.queueActionLocked(Sync, obj); err != nil {
return fmt.Errorf("couldn't queue object: %v", err)
}
return nil
}SharedInformer消費メッセージの理解
主にHandleDeltasメソッドを見てください。このメソッドは、メッセージを消費してからデータを配布し、データをキャッシュに保存します。
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
// from oldest to newest
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Added, Updated:
...
//查一下是否在Indexer缓存中 如果在缓存中就更新缓存中的对象
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
if err := s.indexer.Update(d.Object); err != nil {
return err
}
//把数据分发到Listener
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
} else {
//没有在Indexer缓存中 把对象插入到缓存中
if err := s.indexer.Add(d.Object); err != nil {
return err
}
s.processor.distribute(addNotification{newObj: d.Object}, isSync)
}
...
}
}
return nil
}インデクサの理解
インフォーマーメカニズムで最も重要なのは前のデータの流れだと思うので、このセクションではあまり内容を取り上げません。もちろん、これはデータストレージが重要ではないという意味ではありませんが、最初に全体的な考え方を明確にし、次に、保存されているパーツを後で詳細に更新します。
インデクサーは、threadsafe_store.goのthreadSafeMapを使用してデータを格納します。これは、インデックス機能を備えたスレッドセーフマップです。データはメモリにのみ格納され、関連する各操作はロックされます。
// threadSafeMap implements ThreadSafeStore
type threadSafeMap struct {
lock sync.RWMutex
items map[string]interface{}
indexers Indexers
indices Indices
}インデクサーにはインデックス関連のコンテンツもあるので、ここでは詳しく説明しません。
サンプルコード
-------------
package main
import (
"flag"
"fmt"
"path/filepath"
"time"
v1 "k8s.io/api/apps/v1"
"k8s.io/apimachinery/pkg/labels"
"k8s.io/client-go/informers"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/rest"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/tools/clientcmd"
"k8s.io/client-go/util/homedir"
)
func main() {
var err error
var config *rest.Config
var kubeconfig *string
if home := homedir.HomeDir(); home != "" {
kubeconfig = flag.String("kubeconfig", filepath.Join(home, ".kube", "config"), "[可选] kubeconfig 绝对路径")
} else {
kubeconfig = flag.String("kubeconfig", filepath.Join("/tmp", "config"), "kubeconfig 绝对路径")
}
// 初始化 rest.Config 对象
if config, err = rest.InClusterConfig(); err != nil {
if config, err = clientcmd.BuildConfigFromFlags("", *kubeconfig); err != nil {
panic(err.Error())
}
}
// 创建 Clientset 对象
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err.Error())
}
// 初始化一个 SharedInformerFactory 设置resync为60秒一次,会触发UpdateFunc
informerFactory := informers.NewSharedInformerFactory(clientset, time.Second*60)
// 对 Deployment 监听
//这里如果获取v1betav1的deployment的资源
// informerFactory.Apps().V1beta1().Deployments()
deployInformer := informerFactory.Apps().V1().Deployments()
// 创建 Informer(相当于注册到工厂中去,这样下面启动的时候就会去 List & Watch 对应的资源)
informer := deployInformer.Informer()
// 创建 deployment的 Lister
deployLister := deployInformer.Lister()
// 注册事件处理程序 处理事件数据
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: onAdd,
UpdateFunc: onUpdate,
DeleteFunc: onDelete,
})
stopper := make(chan struct{})
defer close(stopper)
informerFactory.Start(stopper)
informerFactory.WaitForCacheSync(stopper)
// 从本地缓存中获取 default 命名空间中的所有 deployment 列表
deployments, err := deployLister.Deployments("default").List(labels.Everything())
if err != nil {
panic(err)
}
for idx, deploy := range deployments {
fmt.Printf("%d -> %sn", idx+1, deploy.Name)
}
<-stopper
}
func onAdd(obj interface{}) {
deploy := obj.(*v1.Deployment)
fmt.Println("add a deployment:", deploy.Name)
}
func onUpdate(old, new interface{}) {
oldDeploy := old.(*v1.Deployment)
newDeploy := new.(*v1.Deployment)
fmt.Println("update deployment:", oldDeploy.Name, newDeploy.Name)
}
func onDelete(obj interface{}) {
deploy := obj.(*v1.Deployment)
fmt.Println("delete a deployment:", deploy.Name)
} 上記のサンプルコードでは、プログラムは開始後にデプロイメントデータを1回プルし、データがプルされた後、ローカルキャッシュからデフォルトの名前空間にデプロイメントリソースを一覧表示して出力し、60ごとにデプロイメントリソースを再同期します。秒。
QA
なぜ再同期が必要なのですか?
クラスメートが今週1つレイズしました。この問題を見て、Resyncはローカルキャッシュのデータキャッシュからローカルキャッシュへ(最初から最後まで)であるため、なぜデータを再度取り出す必要があるのか、非常に奇妙に感じました。 ?プロセスを通過しますか?当時は理解できませんでしたが、後で別の角度から考えました。
データはAPIサーバーから取得され、処理されてキャッシュに入れられますが、データが正常に処理されない可能性があります。つまり、エラーが報告される可能性があり、この再同期は再試行メカニズムと同等です。
練習することができます:ステートフルサービスをデプロイし、ストレージにLocalPVを使用します(使い慣れたものに変更することもできます)。このとき、ストレージディレクトリが存在しないため、ポッドは起動に失敗します。次に、対応するものを作成します。ポッドの起動に失敗した後のディレクトリ。しばらくするとポッドは正常に起動します。これは私が理解している状況です。
総括する:
インフォーマーメカニズムは、K8Sのさまざまなコンポーネント間のコミュニケーションの基礎です。完全な理解は非常に役立ちます。私はまださらなる理解の過程にあります。コミュニケーションへようこそ。
先読み:
Four Coffee Beansを 起源と しているため、転載のソースを宣言して
ください。GongZong番号に従ってください-> [Four CoffeeBeans]最新のコンテンツを入手してください