mysqlチューニング-クエリ最適化
記事のディレクトリ
1.クエリ速度に影響を与える要因
ネットワーク、CPU、IO、コンテキストスイッチ、システムコール、統計の生成(監視タイプ)、ロック待機時間。
2.テーブルデータを最適化する
1.データの量
クエリが遅い主な理由は、アクセスできないデータが多すぎることです。一部のクエリでは、必然的に大量のデータをフィルタリングする必要があります。これは、アクセスされるデータの量を減らすことで最適化できます。クエリが必要以上の大量のデータを取得しているかどうか、およびmysqlサーバー層が必要以上の多数のデータ行を分析しているかどうかを確認する必要があります。
SQLが不要なデータをクエリしたかどうかを確認します。limitを使用できる場合は、必要なだけ使用してみてください。複数のテーブルが関連付けられている場合、select *を使用せずに、必要な列のみがフェッチされます。これは、クエリのパフォーマンスに影響します。データを複数回クエリする必要がある場合は、キャッシュを使用してデータのこの部分をキャッシュできます。
三、実行プロセスの最適化
1.クエリキャッシュ
クエリキャッシュがオンになっている場合、mysqlは最初にクエリがクエリキャッシュ内のデータにヒットするかどうかを確認します。クエリがクエリキャッシュにヒットする場合、結果を返す前にユーザーの権限を確認します。権限が正しい場合、mysqlはすべてのステージをスキップします。キャッシュから直接結果を取得し、クライアントに返します。
キャッシュ関連情報の表示:「%query_cache%」などの変数を表示します
。query_cache_typeはONで開いた状態、OFFは閉じた状態です。query_cache_sizeはキャッシュの最大サイズです。
キャッシュスイッチがオフの場合は、構成ファイルに移動して、関連する構成を変更する必要があります
。my.cnfファイルのmysqldに追加します。
query_cache_type = ON
query_cache_size = 10M
2.構文パーサーの前処理
mysqlは、sql内のキーワードを解析して解析ツリーを生成し、次にmysql構文ルールの検証と解析クエリを介して前処理して解析ツリーが妥当かどうかを確認します。
3.クエリオプティマイザ
1>、オプティマイザー最適化戦略
静的最適化:解析ツリーを直接分析し、最適化を完了します。
動的最適化:クエリのコンテキストに関連し、値とインデックスに対応する行数にも関連する場合があります
。mysql静的最適化クエリのみ1回かかり、実行するたびに動的最適化を再評価する必要があります
。2>、オプティマイザ最適化タイプ
は、関連付けられたテーブルの順序を定義します。複数のテーブルが関連付けられている場合、実行されません。 sqlによって記述された、ただし最適化された関連テーブルの順序でデバイスが順序を決定します。
外部結合を内部結合に
変換します。これはより効率的です。同等の変換ルールを使用します。同等の変更を使用して式を簡略化および計画します
。count()を最適化します。、min()、max():特定の列の最小値を見つけるなど、対応するインデックスの左端の値を直接クエリし、テーブル全体のスキャンを回避します。
変換定数式:式が次のようになることが検出された場合定数に変換されると、式は定数として処理されます。
カバーリングインデックス:列のインデックスにクエリで使用する必要のあるすべての列が含まれている場合は、カバーリングインデックスを使用します。
サブクエリの最適化:サブクエリは生成します一時テーブル、場合によってはサブクエリがより効率的な形式に変換され、サブクエリデータがキャッシュに入れられ、データにアクセスするための複数のクエリが複数回削減されます;
等価伝播:2つの列の値は次のように関連付けられます方程式、およびmysqlは1つの列のwhere条件を別の列に渡します。
4.関連付けクエリ
1>、関連付けられたクエリプロセス:
mysqlは、すべての関連付けに対してネストされたループ関連付け操作を実行します。つまり、mysqlは最初にテーブル内の単一のデータをループアウトし、次に次のテーブルにネストして一致する行を見つけてから、テーブル内の一致するすべての行が停止していることがわかります。次に、各テーブルの一致する行に従って、クエリに必要な各列を返します。
2>、結合モードの実現原理(3つのタイプ):
単純なネストループ結合:2つの接続されたテーブルは、一方を駆動テーブルとして使用し、もう一方をマッチングテーブルとして使用します。外部ループは、駆動テーブルを行ごとに消費します。各レコードは一致するテーブルと一致し、最終的にデータをマージするため、多くのデータベースが消費されます。下の図の左側はドライブテーブルのデータであり、右側は一致するテーブルのデータです。
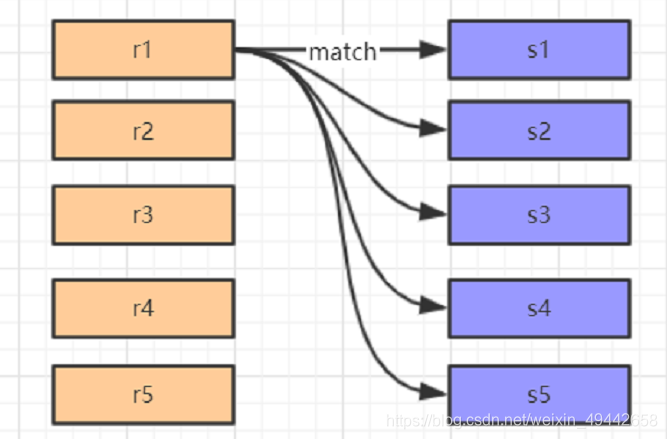
インデックスネストループ結合:一致するテーブルにインデックスがあり、そのインデックスを使用して比較の数を減らし、クエリを高速化できます。クエリを実行すると、ドライブテーブルは関連するフィールドのインデックスに従って検索し、インデックスを照合した後、テーブルにクエリを返します。最高のパフォーマンスは、一致するテーブルの関連付けられたキーが主キーである場合です。
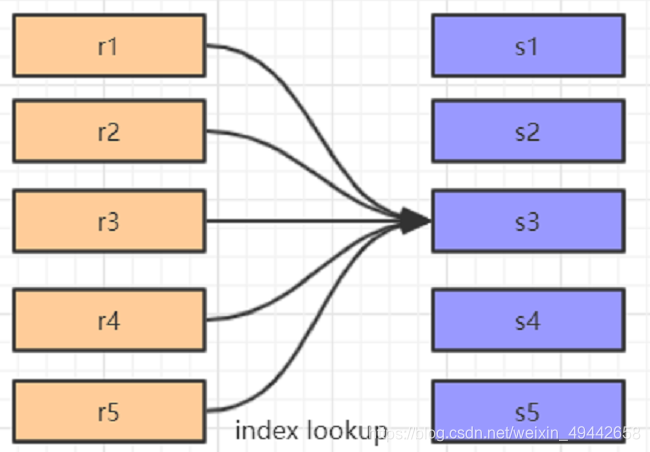
ブロックネストループ結合:最初のメソッドの改良版。結合列にインデックスがない場合は、このメソッドを使用します。中央に結合バッファがあります。最初に、駆動テーブルのすべての結合関連の列が結合バッファにキャッシュされ、一致するテーブルのアクセス頻度を減らすために、一致するテーブルとバッチで一致します。(デフォルトのjoin_buffer_sizeは256Kです)

拡張:結合バッファー:結合バッファーは、結合列だけでなく、クエリに参加しているすべての列をキャッシュします。5.1.22より前のjoin_buffer_sizeの最大値は4Gであり、それ以降のバージョンは4Gより大きくなる可能性があります。ブロックネストループ結合アルゴリズムの使用オプティマイザー管理が必要オプティマイザースイッチを構成し、block_nested_loopをオンに設定し、デフォルトで開きます。現在の情報を表示すると、「%optimizer_switch%」などの変数が表示されます。
3つの特定のタイプのクエリ最適化
1. count()クエリを最適化する
概算値を使用できます。完全に正確な値が必要ない場合は、explainを使用して概算値を取得するか、hyperloglogアルゴリズムを使用して概算値を取得できます(gitHubには多くのプラグインがあります)。より実用的な方法は、インデックスカバレッジスキャンを使用するか、サマリーテーブルを増やすか、外部キャッシュシステムを導入して値をキャッシュすることです。
2.関連するクエリを最適化する
on句またはusing句の列にインデックスがあることを確認します。インデックスを作成するときは、関連付けの順序を考慮する必要があります
。groupbyおよびorder byの式には、テーブルの列のみが含まれます。このプロセスを最適化します。
3.制限ページングを最適化する
最も効果的なのは、すべての列にクエリを実行する代わりに、カバーインデックスを使用することです。
オフセットが非常に大きい場合、以前のデータのほとんどが破棄され、無駄が発生します。次の2つの実行プランを比較してください。
explain select id,user_name from ur_user order by age limit 5000000,5;
explain select t1.id,t1.user_name from ur_user AS t1 inner join (select id from ur_user order by age limit 5000000,5) AS t2 using(id);
4.ユニオンクエリを最適化する
MySQLは、一時テーブルを作成してデータを設定することにより、ユニオンクエリを実行します。多くの最適化戦略は、ユニオンクエリではうまく使用できません。オプティマイザーが最適化のためにこれらの条件を最大限に活用できるように、where、limit、order by、およびその他の句を各サブクエリに手動でプッシュダウンする必要があります。
union allを使用できる場合は、それを使用してみてください。allキーワードがない場合は、クエリ時に個別のキーワードを一時テーブルに追加します。この操作は非常にコストがかかります。
4つのカスタム変数
カスタム変数を使用する方が便利です。
1.基本的な使用法
基本赋值:set @rank :=1;
查询/表达式赋值:set @min_user_id :=(select min(user_id) from ur_user);
2.制限
クエリキャッシュを使用できません。
テーブル名、列名、制限句など、定数または識別子が使用されているカスタム変数を使用できません。カスタム変数
のタイプを明示的に宣言できません。
代入記号:=優先度が非常に低いため、必要です。代入式を使用するときに括弧を明示的に使用するため。
ユーザーレベルのカスタム変数のライフサイクルは接続で有効であり、接続間の通信には使用できません。
3.アプリケーションのシナリオと注意事項
アプリケーションシナリオ:クエリランキング
set @rank :=0;
select staff_name,@rank:=@rank+1 as rank from incom_table order by incom desc limit 10;
注:値の順序を確認してください。次の例は、オプティマイザーによる最適化後の実行順序を示しています。
查询ur_user表中一条数据
因为where和select在查询的不同阶段执行,所以查询到两条记录,不符合预期。
set @usernum:=0;
select user_id,@usernum:=@usernum+1 as usernum from ur_user where @usernum<=1;
引入了order by后,打印出了全部结果,因为order by引入了文件排序,而where条件是在文件排序操作之前取值的。
set @usernum:=0;
select user_id,@rownum:=@rownum+1 as usernum from ur_user where @rownum<=1 order by age;
解决问题的关键在于让变量的赋值和取值发生在执行查询的同一阶段,正确如下。
set @usernum:=0;
select user_id,@usernum as usernum from ur_user where (@usernum:=@usernum+1)<=1;
総括する
この記事では、主に実行プロセスの最適化と特定のタイプのクエリの最適化を、前の記事の実行プランとインデックスの最適化と組み合わせて紹介します。