Greenplumの基本概念
https://gp-docs-cn.github.io/docs/admin_guide/intro/arch_overview.html
Greenplum Databaseは、大規模な分析データウェアハウスとビジネスインテリジェンスのワークロードを管理するために特別に設計されたアーキテクチャを備えた超並列処理(MPP)データベースです。MPP(シェアードナッシングアーキテクチャとも呼ばれます)は、操作を実行するために協調する複数のプロセッサを備えたシステムを指し、各プロセッサには独自のメモリ、オペレーティングシステム、およびディスクがあります。Greenplumは、この高性能システムアーキテクチャを使用して、数テラバイトのデータウェアハウスの負荷を分散し、システムのすべてのリソースを使用してクエリを並列処理できます。
Greenplum Databaseは、PostgreSQL 8.3.23に基づいて開発されたディスク指向のデータベースインスタンスであり、緊密に統合されたデータベース管理システム(DBMS)を形成します。そのSQLサポート、機能、構成オプション、およびエンドユーザー関数は、ほとんどの場合PostgreSQLと非常によく似ています。Greenplum Databaseを操作するデータベースユーザーは、通常のPostgreSQLDBMSを使用していると感じるでしょう。
Greenplum Databaseは、追加最適化(AO)ストレージ形式を使用して、データをバッチでロードおよび読み取りでき、HEAPテーブルのパフォーマンスを向上させることができます。追加の最適化されたストレージは、データ保護、圧縮、および行/列の方向のチェックサムを提供します。行または列の追加用に最適化されたテーブルは圧縮できます。
GreenplumデータベースとPostgreSQLの主な違いは次のとおりです。
- Greenplum Databaseの並列構造をサポートするために、PostgreSQLの内部が変更または追加されました。たとえば、システムカタログ、オプティマイザ、クエリエグゼキュータ、およびトランザクションマネージャのコンポーネントは、すべての並列PostgreSQLデータベースインスタンスで同時にクエリを実行できるように変更または拡張されています。Greenplumの相互接続(ネットワーク層)により、異なるPostgreSQLインスタンス間の通信が可能になり、システムが論理データベースとして動作できるようになります。
- Greenplum Databaseは、列ベースのストレージを選択できます。データは論理的にテーブルに編成されますが、行と列は、行としてではなく、列指向の形式で物理的に格納されます。列型ストレージは、追加最適化テーブルでのみ使用できます。カラム型ストレージは圧縮可能です。ユーザーが関心のある列のみを返す必要がある場合、列ストレージはパフォーマンスを向上させることができます。すべての圧縮アルゴリズムは行または列のストレージテーブルで使用できますが、ランレングスエンコーディング(RLE)圧縮は列のストレージテーブルでのみ使用できます。Greenplum Databaseは、列指向ストレージを使用するすべての追加最適化テーブルの圧縮を提供します。
Greenplumデータベースクエリは、火山クエリエンジンモデルを使用します。このモデルでは、実行エンジンが実行プランを取得し、それを使用して物理演算子ツリーを生成し、物理演算子を使用してテーブルを計算し、最後にクエリ応答として結果を返します。
データを分散し、複数のサーバーまたはホストで負荷を処理することにより、大量のデータを保存および処理します。Greenplum Databaseは、PostgreSQL 8.3に基づくデータベースの配列です。配列内のデータベースは連携して、単一のデータベースを提供します。マスターはGreenplumデータベースシステムへの入り口です。クライアントはこのデータベースインスタンスに接続し、SQLステートメントを送信します。マスターは、システム内のセグメントと呼ばれる他のデータベースインスタンスを調整し、操作します。セグメントは、データの保存と処理を担当します。
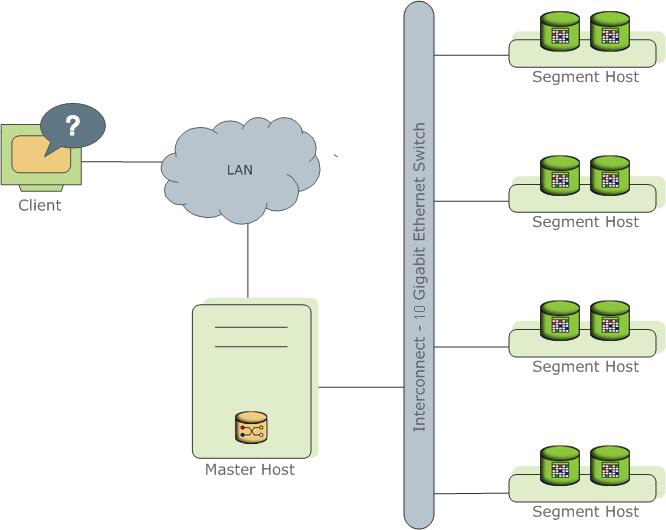
Greenplumのマスター
Greenplumデータベースマスターは、Greenplumデータベースシステム全体への入り口です。接続とSQLクエリを受け入れ、セグメントインスタンスに作業を分散します。Greenplumデータベースと(マスターを介して)対話するとき、彼らは典型的なPostgreSQLデータベースと対話していると感じます。 。psqlなどのクライアントまたはJDBC、ODBC、libpq(PostgreSQL C言語API)などのアプリケーションプログラミングインターフェイス(API)を使用して、データベースに接続できます。
マスターは、グローバルシステムカタログの場所です。グローバルシステムカタログには、Greenplumデータベースシステム自体のメタデータに関連するシステムテーブルが含まれます。マスターにはユーザーデータは含まれず、データはセグメントにのみ存在します。マスターは、クライアント接続を認証し、着信SQLコマンドを処理し、ワークロードをセグメント間で分散し、各セグメントから返される結果を調整し、最終結果をクライアントプログラムに提示します。
Greenplum Databaseは、先行書き込みログ(WAL)を使用して、プライマリ/スタンバイミラーリングを実装します。WALベースのログでは、処理中の操作のデータ整合性を確保するために、すべての変更が適用される前にログに書き込まれます。
Greenplumのセグメント
Greenplum DatabaseのSegmentインスタンスは、独立したPostgreSQLデータベースであり、各データベースはデータの一部を格納し、クエリ処理の主要部分を実行します。ユーザーがGreenplumMasterを介してデータベースに接続し、クエリを発行すると、クエリを処理するために各セグメントデータベースにいくつかのプロセスが作成されます。
ユーザー定義のテーブルとそのインデックスはセグメントで使用でき、セグメントにはデータのさまざまな部分が含まれます。セグメントデータを提供するデータベースサーバープロセスは、対応するセグメントインスタンスの下で実行されます。ユーザーは、マスターを介してGreenplumデータベースシステムのセグメントと対話します。セグメントホストは通常、CPUコア、RAM、ストレージ、ネットワークインターフェイス、およびワークロードの数に応じて、2〜8個のGreenplumセグメントを実行します。セグメントホストも同じように構成する必要があります。Greenplum Databaseから最高のパフォーマンスを得る秘訣は、データとワークロードを同じ機能を持つ多数のセグメントに均等に分散して、すべてのセグメントが同時にタスクの作業を開始し、同時に作業を完了することができるようにすることです。 。
Greenplumクエリの配布
マスターは分析を受け取り、クエリを最適化します。結果のクエリプランは、並列または方向性があります。マスターは、並列クエリプランをすべてのセグメントに配布します。ターゲットクエリプランを単一のセグメントに配布します。各セグメントは、独自のデータセットに対してローカルデータベース操作を実行する責任があります。ほとんどのデータベース操作(テーブルスキャン、結合、集計、並べ替えなど)は、すべてのセグメントで並列に実行されます。セグメントデータベースで実行される各操作は、他のセグメントデータベースに格納されているデータから独立しています。
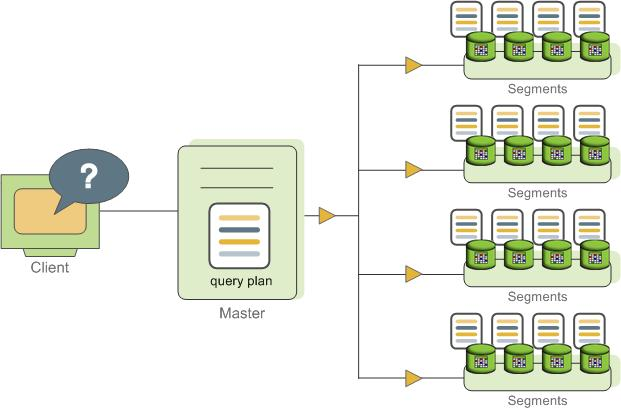
一部のクエリは、単一行のINSERT、UPDATE、DELETE、またはSELECT操作や、テーブル配布キー列でフィルタリングされたクエリなど、単一セグメントのデータにのみアクセスできます。これらのクエリでは、クエリプランはすべてのセグメントに配布されるのではなく、影響を受ける行または関連する行を含むセグメントに送信されます。
Greenplum Databaseには、通常のデータベース操作(テーブルスキャン、結合など)に加えて、「移動」操作もあります。移動には、セグメント間のタプルの移動が含まれます。すべてのクエリに移動操作が必要なわけではありません(ダイレクトクエリプランにはデータが必要ありません)。 Greenplumは、クエリの実行中に最大の並列処理を実現するために、クエリプランの作業をスライスに分割します。スライスは、セグメントが独立して機能できる計画されたセグメントです。移動操作がプランに表示されている限り、クエリプランはスライスされ、移動の両端にスライスが表示されます。2つのテーブル間の結合を含む次の単純なクエリについて考えてみます。
SELECT customer, amount
FROM sales JOIN customer USING (cust_id)
WHERE dateCol = '04-30-2016';この例の再配布の移動が必要であり、接続を完了するにはタプルをセグメント間で移動する必要があります。これは、customerテーブルがセグメントのcust_idに従って配布され、salesテーブルがsale_idに従って配布されるためです。接続を実行するには、cust_idに従って販売タプルを再配布する必要があり、再配布移動操作の両側でプランが切り替えられ、スライス1とスライス2が形成されます。このクエリプランは別で構成されて移動操作と呼ばコレクト動きます。収集操作は、セグメントが結果をマスターに送り返すタイミングを示し、マスターは結果をクライアントに提示します。クエリプランは移動がある限りスライスされるため、このプランにはトップレベルに暗黙のスライス(スライス3)もあります。すべてのクエリプランにコレクションの移動が含まれるわけではありません。たとえば、タプルはすべてマスターではなく新しく作成されたテーブルに送信されるため、CREATE TABLE x AS SELECT ...ステートメントは収集および移動されません。
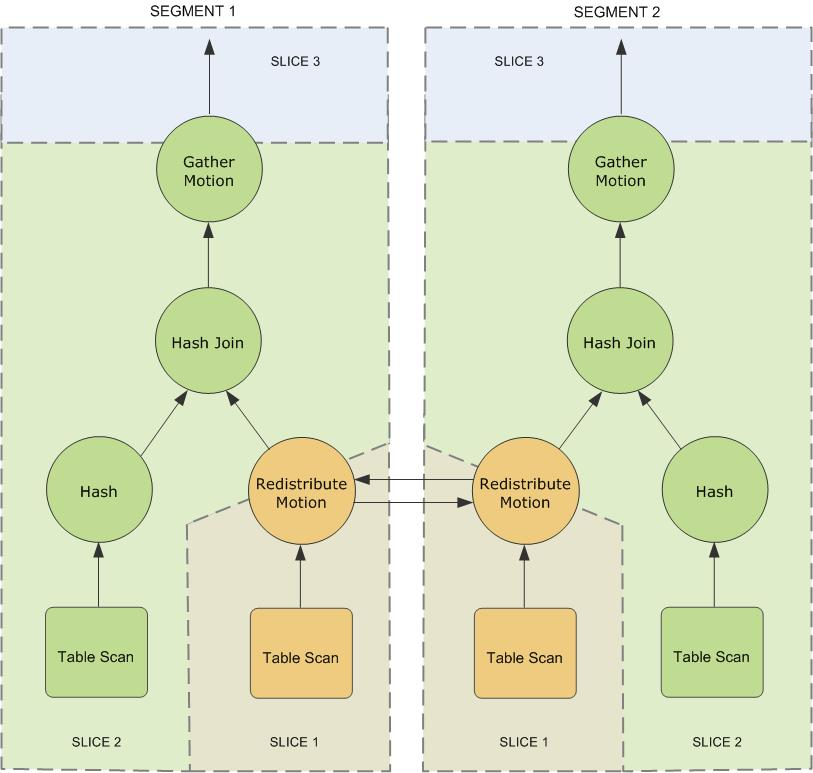
Greenplumは、クエリの作業を処理するためにいくつかのデータベースプロセスを作成します。マスターでは、クエリワーカープロセスはクエリディストリビューター(QD)と呼ばれます。QDは、クエリプランの作成と配布を担当します。また、最終結果を収集して表現します。セグメントでは、クエリワーカープロセスはクエリエグゼキューター(QE)と呼ばれます。QEは、その作業のその部分を完了し、その中間結果を他のワーカープロセスと伝達する責任があります。クエリプランの各スライスには、少なくとも1つのワーカープロセスを割り当てる必要があります。ワーカープロセスは、割り当てられたクエリプランの一部で独立して機能します。クエリの実行中、各セグメントには、クエリに対して並行して機能する複数のプロセスがあります。
クエリプランの同じスライスで機能するが、異なるセグメントに配置されている関連プロセスは、ギャングと呼ばれます。作業の一部が完了すると、タプルはクエリプランの1つのプロセスグループから次のグループに流れます。セグメント間のこのプロセス間通信は、GreenplumDatabaseの相互接続コンポーネントと呼ばれます。

Greenplumデータベースクラスターの管理とステータスの表示
Greenplum Databaseは、一般的な監視および管理タスクを実行するための標準のコマンドラインツールを提供します。Greenplumのコマンドラインツールは$ GPHOME / binディレクトリにあり、マスターホストで実行されます。Greenplumは、次の管理タスクのための実用的なツールを提供します。
- Greenplumデータベースをアレイにインストールします
- Greenplumデータベースシステムを初期化します
- Greenplumデータベースの開始と停止
- ホストを追加または削除する
- 配列を展開し、新しいセグメントでテーブルを再配布します
- 失敗したセグメントインスタンスを回復する
- 失敗したマスターインスタンスのフェイルオーバーとリカバリを管理する
- データベースのバックアップと復元(並列)
- データを並列にロードする
- Greenplumデータベース間でデータを転送する
- システムステータスレポート
1.セグメントノードのステータスを表示します
select * from gp_segment_configuration;
pgdb=# select * from gp_segment_configuration;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
------+---------+------+----------------+------+--------+------+-------------+-------------+-----------------------------
1 | -1 | p | p | n | u | 5432 | greenplum-1 | greenplum-1 | /data/gpdata/master/gpseg-1
2 | 0 | p | p | n | u | 6000 | greenplum-2 | greenplum-2 | /data/gpdata/pdata/gpseg0
3 | 1 | p | p | n | u | 6000 | greenplum-3 | greenplum-3 | /data/gpdata/pdata/gpseg1
4 | 0 | m | m | n | d | 7000 | greenplum-3 | greenplum-3 | /data/gpdata/mdata/gpseg0
5 | 1 | m | m | n | d | 7000 | greenplum-2 | greenplum-2 | /data/gpdata/mdata/gpseg12.セグメントノードの障害などの履歴情報を表示します
select * from gp_configuration_history order by 1 desc ;3. gpstateツールは、データベースシステムのステータス情報を表示し、セグメントインスタンスの同期ステータスを確認するために提供されます
gpstate -mこのコマンドは、各ノードインスタンスの同期ステータスを出力します。各ノードのステータスが「同期中」の場合は異常です。データがある場合は、セグメントインスタンスが同期していることを意味します。数分ごとに再実行してください。がインスタンスの場合、同期を長時間完了できません。、さらに監視するためにDBAに報告する必要があります
。4。セグメントノードのディスクアイドル状態を確認します。
SELECT * FROM gp_toolkit.gp_disk_free;5.スタンバイ同期ステータスを確認します
gpstate -fこのコマンドは、スタンバイマスターの同期ステータスを出力します。これは、スタンバイマスターのステータスが「同期中」の場合は異常です。Greenplumデータベースアレイの構成に関する詳細情報を表示するには、gpstateを-sオプションとともに使用します。
gpstate -s6. Greenplumは、次のようなバッチでpgクラスターのノードを操作できるpgsshコマンドを提供します。
gpssh -f ~/gpconfigs/hostfile_segonly -e "df -h |grep /data"
[gpadmin@greenplum-1 gpconfigs]$ gpssh -f ~/gpconfigs/hostfile_segonly -e "df -h |grep /data"
[greenplum-3] df -h |grep /data
[greenplum-3] /dev/vdb 197G 724M 187G 1% /data
[greenplum-2] df -h |grep /data
[greenplum-2] /dev/vdb 197G 724M 187G 1% /data7.すべての構成が完了したら、データベースを初期化します。-cの後に初期システムパラメータ、-hの後にセグメントリストを入力します。
gpinitsystem -c /home/gpadmin/gpconfigs/gpinitsystem_config -h /home/gpadmin/gpconfigs/hostfile_segonly8.クラスターを開始します
gpstart9.クラスターを再起動します
gpstop -r10.データディスクを表示する
マスターデータとセグメントデータがいっぱいになると、通常のデータベースアクティビティを続行できなくなります。ディスクがいっぱいになると、データベースサーバーがシャットダウンする可能性があります。gp_toolkit管理ソリューションのgp_disk_free外部テーブルを使用して、セグメントホストファイルシステムの残りの空き領域(キロバイト単位)を確認できます。
SELECT * FROM gp_toolkit.gp_disk_free ORDER BY dfsegment;11.各ライブラリのストレージ委託販売を表示します
データベースの全体的なサイズ(バイト単位)、gp_toolkit管理スキームgp_size_of_databaseビューの使用を参照してください。例えば:
SELECT * FROM gp_toolkit.gp_size_of_database ORDER BY sodddatname;12.テーブルが占めるディスクサイズを表示します
SELECT relname AS name, sotdsize AS size, sotdtoastsize
AS toast, sotdadditionalsize AS other
FROM gp_toolkit.gp_size_of_table_disk as sotd, pg_class
WHERE sotd.sotdoid=pg_class.oid ORDER BY relname;