NumPy配列の次元はランクと呼ばれます。ランクは軸の数、つまり配列の次元です。1次元配列のランクは1で、2次元配列のランクは2です。
目次
NumPyでは、各線形配列は軸(axis)、つまり次元(dimensions)と呼ばれます。たとえば、2次元配列は2つの1次元配列と同等であり、最初の1次元配列の各要素は1次元配列です。したがって、1次元配列はNumPyの軸であり、最初の軸は下の配列と同等であり、2番目の軸は下の配列の配列です。軸の数-ランクは、配列の次元です。多くの場合、軸を宣言できます。axis = 0は、0番目の軸に沿って動作する、つまり各列で動作することを意味します。axis= 1は、1番目の軸に沿って動作する、つまり各行で動作することを意味します。
NumPy配列でより重要なndarrayオブジェクト属性は次のとおりです。
| 属性 | 説明 |
|---|---|
| ndarray.ndim | 軸の数または次元の数であるランク |
| ndarray.shape | 行列の場合の配列の次元、n行およびm列 |
| ndarray.size | .shapeのn * mの値に相当する配列要素の総数 |
| ndarray.dtype | ndarrayオブジェクトの要素タイプ |
| ndarray.itemsize | ndarrayオブジェクトの各要素のサイズ(バイト単位) |
| ndarray.flags | ndarrayオブジェクトのメモリ情報 |
| ndarray.real | ndarray要素の実数部 |
| ndarray.imag | ndarray要素の虚数部 |
| ndarray.data | 実際の配列要素を含むバッファ。要素は通常、配列のインデックスによって取得されるため、この属性は通常必要ありません。 |
- ndarray.ndimは、ランクに等しい配列の次元を返すために使用されます。
- ndarray.shapeは配列の次元を表し、タプルを返します。このタプルの長さは、次元の数、つまりndim属性(ランク)です。たとえば、2次元配列の場合、その次元は「行数」と「列数」を表します。
- ndarray.itemsizeは、配列内の各要素のサイズをバイト単位で返します。
- ndarray.flagsは、ndarrayオブジェクトのメモリ情報を返します。
NumPyは配列を作成します
NumPyの最も重要な機能の1つは、同じタイプの一連のデータのコレクションであるN次元配列オブジェクトndarrayです。コレクション内の要素のインデックスは0添え字で始まります。
ndarrayオブジェクトは、同じタイプの要素を格納するために使用される多次元配列です。
ndarrayの各要素には、メモリ内に同じストレージサイズの領域があります。
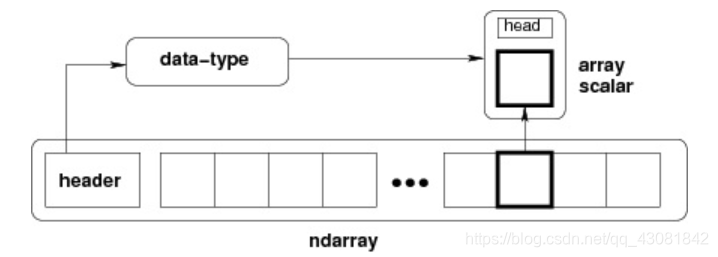
ndarrayは、内部的に次のもので構成されています。
-
データへのポインタ(メモリ内のデータまたはメモリマップトファイル)。
-
配列内の固定サイズ値のグリッドを記述するデータ型またはdtype。
-
配列の形状を表すタプルで、各次元のタプルを表します。
-
ストライド。整数は、現在の次元の次の要素に進むための「ストライド」のバイト数を指します。
ndarrayの内部構造:
スパンは負の数にすることができます。これにより、スライス内のobj [::-1]やobj [:、::-1]など、配列がメモリ内で後方に移動します。
ndarrayを作成するには、NumPyの配列関数を呼び出すだけです。
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
| 名前 | 説明 |
|---|---|
| オブジェクト | 配列またはネストされたシーケンス |
| dtype | 配列要素のデータ型、オプション |
| コピー | オブジェクトをコピーする必要があるかどうか、オプション |
| 注文 | 配列のスタイルを作成します。Cは行の方向、Fは列の方向、Aは任意の方向です(デフォルト) |
| 試してみてください | デフォルトでは、基本型と一致する配列を返します |
| ndmin | 生成された配列の最小次元を指定します |
numpy.empty
numpy.emptyメソッドは、指定された形状(shape)とデータ型(dtype)を持つ初期化されていない配列を作成するために使用されます。
numpy.empty(shape, dtype = float, order = 'C')
numpy.zeros
は指定されたサイズの配列を作成し、配列要素は0で埋められます。
numpy.zeros(shape, dtype = float, order = 'C')
numpy.ones
は指定された形状の配列を作成し、配列要素は1で埋められます。
numpy.ones(shape, dtype = None, order = 'C')
NumPyは既存の配列から配列を作成します
numpy.asarray
numpy.asarrayはnumpy.arrayに似ていますが、numpy.asarrayには3つのパラメーターしかなく、numpy.arrayより2つ少なくなっています。
numpy.asarray(a, dtype = None, order = None)
| パラメータ | 説明 |
|---|---|
| A | リスト、リストのタプル、タプル、タプルのタプル、タプルのリスト、多次元配列などの任意の入力パラメーター |
| dtype | データ型、オプション |
| 注文 | オプションで、2つのオプション「C」と「F」があります。これらはそれぞれ、行優先と列優先の、コンピュータメモリ内のストレージ要素の順序を表します。 |
import numpy as np
x = [[1,2,3],[4,5,6],[7,8,9]]
arrays = np.asarray(x)
print(arrays)
NumPyは値の範囲から配列を作成します
numpy.arange
numpyパッケージのarange関数を使用して、数値範囲を作成し、ndarrayオブジェクトを返します。関数の形式は次のとおりです。
numpy.arange(start, stop, step, dtype)
startとstopで指定された範囲と、stepで設定されたステップサイズに従って、ndarrayが生成されます。
| パラメータ | 説明 |
|---|---|
| 開始 | 開始値、デフォルトは0です |
| やめる | 最終値(含まれていません) |
| ステップ | ステップサイズ、デフォルトは1 |
| dtype | ndarrayのデータ型を返します。指定されていない場合は、入力データ型が使用されます。 |
import numpy as np
x = np.arange(5)
print (x)
[0 1 2 3 4]
NumPyデータ型
numpyは、Pythonの組み込み型よりもはるかに多くのデータ型をサポートし、基本的にC言語のデータ型に対応でき、一部の型はPythonの組み込み型に対応します。次の表に、NumPyの一般的な基本タイプを示します。
| 名前 | 説明 |
|---|---|
| bool_ | ブールデータ型(TrueまたはFalse) |
| int_ | デフォルトの整数型(C言語のlong、int32、またはint64と同様) |
| インテル | Cのint型と同じで、通常はint32またはint 64 |
| intp | インデックス作成に使用される整数型(Cのssize_tと同様、通常はint32またはint64) |
| int8 | バイト(-128〜127) |
| int16 | 整数(-32768〜32767) |
| int32 | 整数(-2147483648から2147483647) |
| int64 | 整数(-9223372036854775808から9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
NumPy 切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。
ndarray 数组可以基于 0 - n 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。
import numpy as np
a = np.arange(10)
s = slice(2,7,2) # 从索引 2 开始到索引 7 停止,间隔为2
print (a[s])
[2 4 6]
以上实例中,我们首先通过 arange() 函数创建 ndarray 对象。 然后,分别设置起始,终止和步长的参数为 2,7 和 2。
我们也可以通过冒号分隔切片参数 start:stop:step 来进行切片操作:
import numpy as np
a = np.arange(10)
b = a[2:7:2] # 从索引 2 开始到索引 7 停止,间隔为 2
print(b)
[2 4 6]
冒号 : 的解释:如果只放置一个参数,如 [2],将返回与该索引相对应的单个元素。如果为 [2:],表示从该索引开始以后的所有项都将被提取。如果使用了两个参数,如 [2:7],那么则提取两个索引(不包括停止索引)之间的项。
import numpy as np
a = np.arange(10) # [0 1 2 3 4 5 6 7 8 9]
b = a[5]
print(b)
5
print(a[2:])
[2 3 4 5 6 7 8 9]
print(a[2:5])
[2 3 4]
NumPy 高级索引
NumPyは、通常のPythonシーケンスよりも多くのインデックス作成方法を提供します。以前に見た整数とスライスを使用したインデックス付けに加えて、配列は整数配列、ブールインデックス、およびファンシーインデックスによってインデックス付けできます。
整数配列インデックス
次の例では、配列内の位置(0,0)、(1,1)、および(2,0)の要素を取得します。
import numpy as np
x = np.array([[1, 2], [3, 4], [5, 6]])
y = x[[0,1,2], [0,1,0]]
print (y)
[1 4 5]
ブールインデックス:ブール配列を介してターゲット配列にインデックスを付けることができます。ブールインデックスは、ブール演算(比較演算子など)を介して指定された条件を満たす要素の配列を取得します。次の例では、5より大きい要素を取得します。
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print ('我们的数组是:')
print (x)
print ('\n')
# 现在我们会打印出大于 5 的元素
print ('大于 5 的元素是:')
print (x[x > 5])
我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
大于 5 的元素是:
[ 6 7 8 9 10 11]
次の例では、〜(補数演算子)を使用してNaNをフィルタリングします。
import numpy as np
a = np.array([np.nan, 1,2,np.nan,3,4,5])
print (a[~np.isnan(a)])
[ 1. 2. 3. 4. 5.]
NumPy反復配列
NumPyイテレータオブジェクトnumpy.nditerは、1つ以上の配列要素にアクセスするための柔軟な方法を提供します。イテレータの最も基本的なタスクは、配列要素へのアクセスを完了することができます。次に、arange()関数を使用して2X3配列を作成し、nditerを使用してそれを反復処理します。
import numpy as np
a = np.arange(6).reshape(2,3)
print ('原始数组是:')
print (a)
print ('\n')
print ('迭代输出元素:')
for x in np.nditer(a):
print (x, end=", " )
print ('\n')
原始数组是:
[[0 1 2]
[3 4 5]]
迭代输出元素:
0, 1, 2, 3, 4, 5,
トラバーサル順序を制御する
- np.nditer(a、order = 'F')のxの場合:Fortranの順序。列の順序が最初です。
- np.nditer(aT、order = 'C')のxの場合:Cの順序、これは最初の行の順序です。
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print ('原始数组是:')
print (a)
print ('\n')
print ('原始数组的转置是:')
b = a.T
print (b)
print ('\n')
print ('以 C 风格顺序排序:')
c = b.copy(order='C')
print (c)
for x in np.nditer(c):
print (x, end=", " )
print ('\n')
print ('以 F 风格顺序排序:')
c = b.copy(order='F')
print (c)
for x in np.nditer(c):
print (x, end=", " )
原始数组是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
原始数组的转置是:
[[ 0 20 40]
[ 5 25 45]
[10 30 50]
[15 35 55]]
以 C 风格顺序排序:
[[ 0 20 40]
[ 5 25 45]
[10 30 50]
[15 35 55]]
0, 20, 40, 5, 25, 45, 10, 30, 50, 15, 35, 55,
以 F 风格顺序排序:
[[ 0 20 40]
[ 5 25 45]
[10 30 50]
[15 35 55]]
0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55,
nditerオブジェクトを明示的に設定することにより、特定の順序を使用するように強制できます。
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print ('原始数组是:')
print (a)
print ('\n')
print ('以 C 风格顺序排序:')
for x in np.nditer(a, order = 'C'):
print (x, end=", " )
print ('\n')
print ('以 F 风格顺序排序:')
for x in np.nditer(a, order = 'F'):
print (x, end=", " )
原始数组是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
以 C 风格顺序排序:
0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55,
以 F 风格顺序排序:
0, 20, 40, 5, 25, 45, 10, 30, 50, 15, 35, 55,