JVMインラインテクノロジーについては多くの話があります。インライン化によって関数呼び出しのオーバーヘッドを削減できることは間違いありませんが、さらに重要なことに、条件が満たされない場合、JVMは最適化を無効にするか削減します。ただし、柔軟性とインライン機能のバランスをとる方法も検討する必要があります。私の意見では、インライン化の重要性は過大評価されています。この一連の記事では、JMH実験を使用して、インライン障害がC2コンパイラの最適化に与える影響を評価します。この記事はシリーズの最初であり、インライン化がエスケープ分析と予防措置にどのように影響するかを紹介します。
>注釈:コンパイルプロセス最適化理論では、エスケープ分析は、ポインターの動的範囲を決定する方法です-プロセス内でポインターにアクセスできる場所を分析します。Javaは、インラインメソッドを直接指定する手段を提供していません。通常、インライン最適化は、JVMの実行時に実行されます。
インライン化は、データベースの非正規化に似ています。これは、関数呼び出しを関数コードに置き換えるプロセスです。データベースの非正規化は、データレプリケーションのレベルを上げ、データベースのサイズを増やすことにより、結合操作のオーバーヘッドを削減します。インライン化は、コードスペースを犠牲にして関数呼び出しのオーバーヘッドを削減します。この類似性は実際には正確ではありません。関数コードを呼び出し元にコピーすると、C2のようなコンパイラーがメソッドを内部で最適化でき、C2がアクティブに最適化を完了します。ご存知のとおり、インライン化を複雑にする方法は2つあります。コードサイズの設定( `InlineSmallCode`オプションは最大許容インラインコードサイズを指定し、デフォルトは2KBです)と多態性の広範な使用です。JMH`@CompilerControl(DONT_INLINE)`アノテーションを呼び出すこともできます。インラインメカニズムをオフにします。
>注釈:データベースの非正規化により、データの冗長性または同じデータを複数の場所に保存できます。
最初のベンチマークは、意図的に設計されたサンプルプログラムです。この方法は短く、以下の機能的なJavaコードにあります。機能プログラミングは、モナド関数とバインド関数を利用します。モナド関数は一般的な計算をラッパータイプとして表現し、ラップされた操作はユニット関数と呼ばれます。バインド機能は、機能を組み合わせてパッケージタイプに適用できます。それらをブリトスと考えることもできます。Java機能プログラミングの一般的なMonadタイプは、Either、Try、およびOptionalです。どちらかのファンクターには、2つの異なるタイプのインスタンスが含まれています。トライファンクターは、出力を生成するか、例外をスローします。オプションは、JDKの組み込みタイプです。JavaのMonadタイプの欠点の1つは、コンパイラに任せるだけでなく、ラッパータイプを実装する必要があることです。使用中に割り当てが失敗するリスクがあります。
>注釈:Monad functorは、常に単層コンテナを返し、入れ子にならないことを保証します。関連紹介推奨「機能プログラミング紹介チュートリアル」RuanYifeng http://www.ruanyifeng.com/blog/2017/02/fp-tutorial.html
次の `Escapee`インターフェースには、戻りタイプが` Optional`の `map`メソッドが含まれています。ラップされていないタイプ `S`と` T`をマッピングすることにより、タイプ `S`の可能な` null`値を `Optional <T>`に安全にマッピングします。異なる実装によって引き起こされるオーバーヘッドの違いを回避するために、同じ実装が3回採用され、Hotspotに `escapee`へのインライン呼び出しを放棄させるしきい値に達しました。
```java
public interface Escapee<T> {
<S> Optional<T> map(S value, Function<S, T> mapper);
}
public class Escapee1<T> implements Escapee<T> {
@Override
public <S> Optional<T> map(S value, Function<S, T> mapper) {
return Optional.ofNullable(value).map(mapper);
}
}
```ベンチマークでは、1〜4つの実装をシミュレートできます。`null`を入力すると、プログラムは実行するさまざまなブランチを選択するため、さまざまなテスト結果が期待されます。異なるブランチの実行コストの違いを保護するために、同じ関数が呼び出されて、各ブランチにインスタントオブジェクトが割り当てられます。これはこの記事の焦点ではないため、ブランチの予測不可能性はここでは考慮されていません。戻り値は揮発性で不純であるため、 `Instant.now()`を選択します。これにより、呼び出しプロセスは他の最適化の影響を受けません。
```java
@State(Scope.Benchmark)
public static class InstantEscapeeState {
@Param({"ONE", "TWO", "THREE", "FOUR"})
Scenario scenario;
@Param({"true", "false"})
boolean isPresent;
Escapee<Instant>[] escapees;
int size = 4;
String input;
@Setup(Level.Trial)
public void init() {
escapees = new Escapee[size];
scenario.fill(escapees);
input = isPresent ? "" : null;
}
}
// 译注:Blackhole 在 JMH 中定义,cosume 输入的 value,不做处理
// 避免对给定值的计算结果消除 dead-code
@Benchmark
@OperationsPerInvocation(4)
public void mapValue(InstantEscapeeState state, Blackhole bh) {
for (Escapee<Instant> escapee : state.escapees) {
bh.consume(escapee.map(state.input, x -> Instant.now()).orElseGet(Instant::now));
}
}
```C2コンパイラのインライン機能の理解に基づいて、シーンTHREEとシーンFOURはインライン最適化されず、シーンONEはインライン化され、シーンTWOは条件付きでインライン化されると予想されます。`-XX:+ UnlockDiagnosticVMOptions -XX:+ PrintInlining`オプションを使用して結果を出力できます。AlekseyShipilёvによる[権威ある記事] [1]を参照してください。
[1]:https://shipilev.net/blog/2015/black-magic-method-dispatch/
ベンチマークテストは、次のパラメータを使用して実行されました。まず、レイヤードコンパイルを無効にして、C1コンパイラをバイパスします。次に、より大きなヒープを設定して、テスト結果がガベージコレクションの一時停止の影響を受けないようにします。最後に、オーバーヘッドの低い `SerialGC`を選択して、書き込みバリアによって引き起こされる干渉を最小限に抑えます。
```shell
taskset -c 0 java -jar target/benchmarks.jar -wi 5 -w 1 -r 1 -i 5 -f 3 -rf CSV -rff escapee.csv -prof gc
-jvmArgs="-XX:-TieredCompilation -XX:+UseSerialGC -mx8G" EscapeeBenchmark.mapValue$
```>注釈:書き込みバリア。ガベージコレクションプロセスでは、書き込みバリアは、世代別不変を維持するために、各ストレージ操作の前にコンパイラによって呼び出されるコードを参照します。
スループットに絶対的な違いはほとんどありませんが、インラインシナリオのスループットは非インラインシナリオのスループットよりもわずかに高いと予想されますが、実際の結果は非常に興味深いものです。
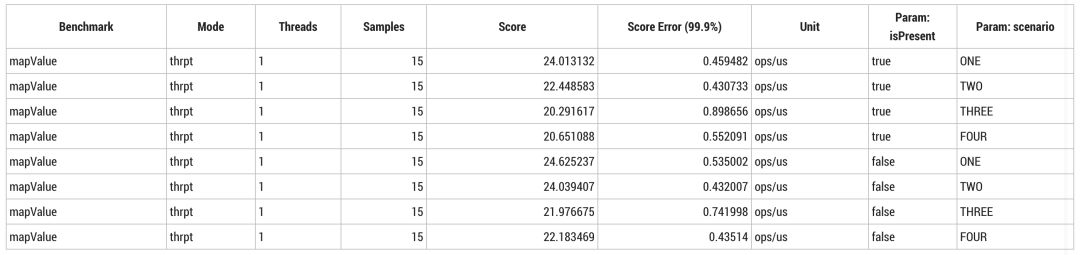
当输入 `null` 时,Megamorphic 内联实现会稍快一些,不加入其他优化可以很容易做到这一点。当输入总是 `null`,或当前只有一种实现(场景 ONE)并且输入不为 `null` 时,标准(normalised)分配速度都是 24B/op。输入非 `null` 时,过半的测试结果为 40B/op。
> 译注:Megamorphic inline caching(超对称内联缓存)。内联缓存技术(Inline Caching)包括 Monomorphic、Polymorphic、Megamorphic三类,通过为特定调用创建代码执行 first-level 方法查找可实现 Megamorphic 内联缓存。
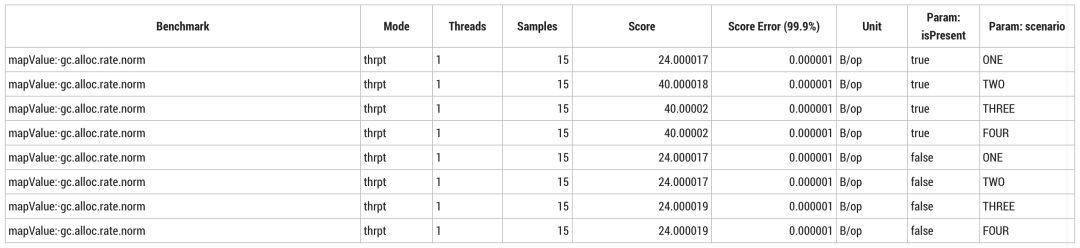
当使用 SerialGC 这样简单的垃圾收集器时,24B/op 表示 `Instant` 类的实例大小,包括8字节1970年到现在的秒数、4字节纳秒数以及12字节对象头。这种情况不会分配包装类型。40B/op 包括 `Optional` 占用的16字节,其中12字节存储对象头,4字节存储压缩过的 `Instance` 对象引用。当方法无法内联优化或者在条件语句中偶尔出现分配时,编译器会放弃内联。在场景 TWO 中,两种实现会引入一个条件语句,这意味着每个操作都为 `optional` 分配了16字节。
这些信息在上面的基准测试中表现得不够明显,几乎都被分配24字节 `Instant` 对象掩盖住了。为了突出差异,我们把后台分配从基准测试中分离出来,再一次跟踪相同的指标。
```java
@State(Scope.Benchmark)
public static class StringEscapeeState {
@Param({"ONE", "TWO", "THREE", "FOUR"})
Scenario scenario;
@Param({"true", "false"})
boolean isPresent;
Escapee<String>[] escapees;
int size = 4;
String input;
String ifPresent;
String ifAbsent;
@Setup(Level.Trial)
public void init() {
escapees = new Escapee[size];
scenario.fill(escapees);
ifPresent = UUID.randomUUID().toString();
ifAbsent = UUID.randomUUID().toString();
input = isPresent ? "" : null;
}
}
@Benchmark
@OperationsPerInvocation(4)
public void mapValueNoAllocation(StringEscapeeState state, Blackhole bh) {
for (Escapee<String> escapee : state.escapees) {
bh.consume(escapee.map(state.input, x -> state.ifPresent).orElseGet(() -> state.ifAbsent));
}
}
```
```shell
taskset -c 0 java -jar target/benchmarks.jar -wi 5 -w 1 -r 1 -i 5 -f 3 -rf CSV -rff escapee-string.csv -prof gc
-jvmArgs="-XX:-TieredCompilation -XX:+UseSerialGC -mx8G" EscapeeBenchmark.mapValueNoAllocation
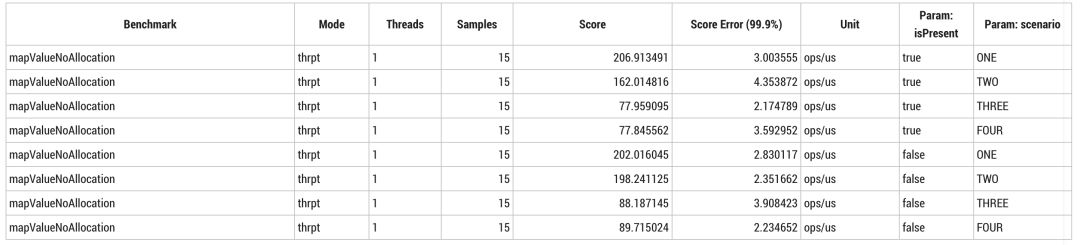
```即使看起来非常简单的实际调用,比如分配时间戳,取消操作也足以减少内联失败的情况。而加入 no-op 的虚拟调用也会让内联失败的情况变得严重。场景 ONE 和场景 TWO 测试结果比其他更快,因为无论输入是否为 `null` 至少都消除了虚函数调用。
很容易想到内存分配被缩减了,只有在使用多态情况下会超过逃逸分析的限值。场景 ONE 不发生分配,一定是逃逸分析起效了。场景 TWO,由于存在条件内联,每次用非 `null` 调用时都会分配16字节 `Optional`;当输入一直为 `null` 时分配减少。然而,内联在场景 THREE 和场景 FOUR 中不起作用,每次调用会额外分配16字节。这个分配与内联无关,变量12字节对象头以及4字节压缩后的 String 引用。你会多久检查一次自己的基准测试,确保测量信息与设想的一致?
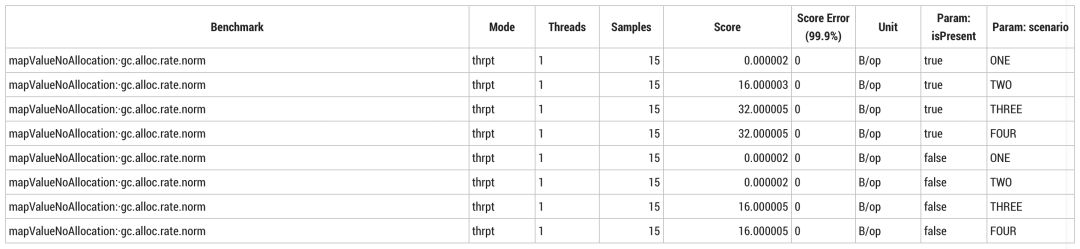
这不是实际编程中可以实用的技术,而是当方法传入 `null` 值,无论是虚函数或内联函数都可以更好地减少内存分配。实际上,`Optional.empty()` 总是返回相同实例,因此从测试开始就没有分配任何内存。
虽然上面通过设计的示例强调了内联失败带来的影响,但值得注意的是,与分配实例和使用不同垃圾回收器带来的开销差异相比内联失败的影响要小得多。一些开发人员似乎没有意识到这一类开销。
```java
@State(Scope.Benchmark)
public static class InstantStoreEscapeeState {
@Param({"ONE", "TWO", "THREE", "FOUR"})
Scenario scenario;
@Param({"true", "false"})
boolean isPresent;
int size = 4;
String input;
Escapee<Instant>[] escapees;
Instant[] target;
@Setup(Level.Trial)
public void init() {
escapees = new Escapee[size];
target = new Instant[size];
scenario.fill(escapees);
input = isPresent ? "" : null;
}
}
@Benchmark
@OperationsPerInvocation(4)
public void mapAndStoreValue(InstantStoreEscapeeState state, Blackhole bh) {
for (int i = 0; i < state.escapees.length; ++i) {
state.target[i] = state.escapees[i].map(state.input, x -> Instant.now()).orElseGet(Instant::now);
}
bh.consume(state.target);
}
```用两种模式运行相同的基准测试:
```shell
taskset -c 0 java -jar target/benchmarks.jar -wi 5 -w 1 -r 1 -i 5 -f 3 -rf CSV -rff escapee-store-serial.csv
-prof gc -jvmArgs="-XX:-TieredCompilation -XX:+UseSerialGC -mx8G" EscapeeBenchmark.mapAndStoreValue$
``````shell
taskset -c 0 java -jar target/benchmarks.jar -wi 5 -w 1 -r 1 -i 5 -f 3 -rf CSV -rff escapee-store-g1.csv
-prof gc -jvmArgs="-XX:-TieredCompilation -XX:+UseG1GC -mx8G" EscapeeBenchmark.mapAndStoreValue$
```改变垃圾回收器触发 Write Barrier(对串行回收器来说很简单,对 G1 来说很复杂)带来的开销与内联失败的开销相当。注意:这并不代表垃圾回收器开销不可接受。
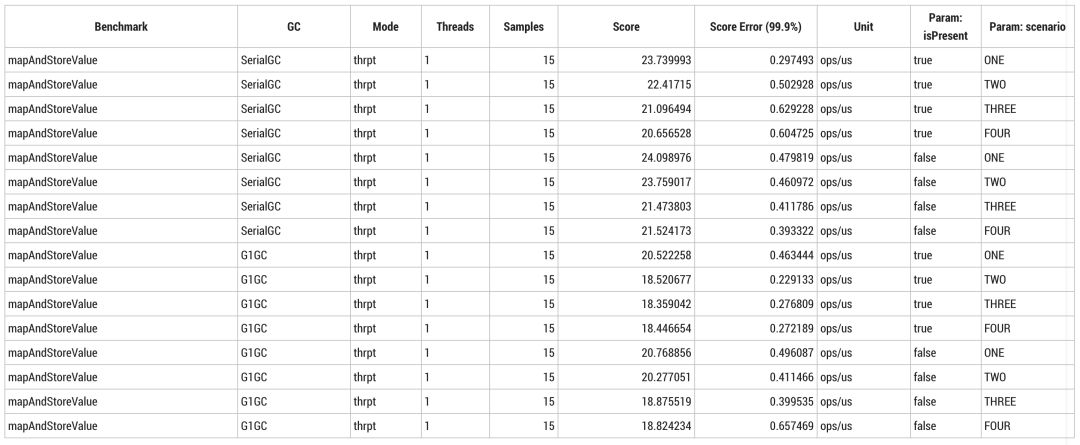
内联优化使逸出分析成为可能,但是仅在只有一种实现时起效。即使出现很小的内存分配也会降低边际效益也会下降,但随着内存分配减少边际效益会逐渐增大。这种差异甚至会比某些垃圾回收器中 Write Barrier 带来的开销更小。基准测试可以在 [github] 上找到,本文的测试环境为 OpenJDK 11+28,操作系统为 Ubuntu 18.04.2 LTS。
[2]:https://github.com/richardstartin/runtime-benchmarks/tree/master/src/main/java/com/openkappa/runtime/inlining/escapee
这种分析也许是肤浅的,许多优化比依赖内联技术的逸出分析更强大。下一篇将讨论类似 hash code 这样的简化操作(Reduction Operation)内联可能带来的好处,或者没有好处。