OneHotエンコーディングを使用する過程でこのような問題が発生したかどうかはわかりません。たとえば、トレーニングサンプルの特定の列の値(ディスクリート)は「緑」「赤」「黄」であり、ワンホットエンコードされています。 、効果は次のとおりです。

実稼働環境で新しいデータをリアルタイムで読み取ると、「緑」、「青」など、トレーニングサンプルには見られなかったデータが表示され、そのワンホットエンコーディングは次のようになります。
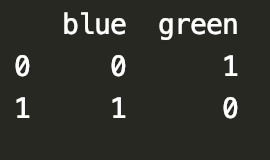
したがって、この場合、データディメンションは不整合になりますが、トレーニングされたモデルの入力ディメンションが決定されるため、モデルが正常に計算されない可能性があります。この問題を解決するにはどうすればよいですか。
パンダでCategoricalを使用して、この問題を解決できます。具体的なコードは次のとおりです。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'Seven'
import pandas as pd
train_words = ['green', 'red', 'yellow']
product_words = pd.Series(['green', 'blue'])
product_words_op = pd.Categorical(product_words, categories=train_words)
print(pd.get_dummies(product_words_op))実装効果は次のとおりです。

緑の既知のカテゴリのリストにあるため、緑のワンホットコードエントリはすべてゼロです。本番データで新しいデータを見つけた場合、対応する行はすべて0である必要があります。この方法は、実稼働環境の次元の問題をある程度解決することができ、モデルを計算することはできません。