Apache Sparkは、もともと2009年にカリフォルニア大学バークレー校のAPM研究所で生まれ、2010年にオープンソース化されました。現在、Apache SoftwareFoundationの下でトップのオープンソースプロジェクトの1つです。Sparkの目標は、データ分析を迅速に実行できるプログラミングモデルを設計することです。Sparkはメモリコンピューティングを提供し、IOオーバーヘッドを削減します。さらに、SparkはScalaに基づいて作成されており、インタラクティブなプログラミング体験を提供します。10年間の開発の後、Sparkはホットなビッグデータ処理プラットフォームになり、最新バージョンはSpark3.0です。この記事は主にSparkの概要を説明することを目的としており、フォローアップコンテンツでは具体的な詳細について説明します。この記事の主な内容は次のとおりです。
- Sparkの注意分析
- Sparkの機能
- Sparkのいくつかの重要な概念
- Sparkコンポーネントの概要
- Sparkオペレーティングアーキテクチャの概要
- Sparkプログラミングの最初の経験
Sparkの関心分析
概要概要
下の図は、過去1年間のSpark、Hadoop、Flinkの国内検索トレンドを示しています。
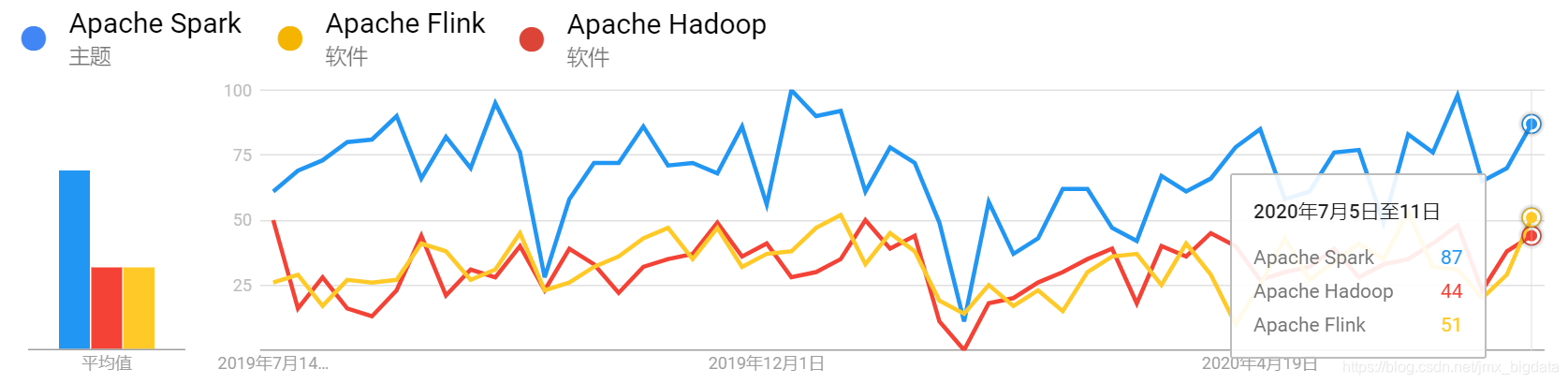
過去1年間のSpark、Hadoop、Flinkの世界的な検索トレンドは次のとおりです。

過去1年間のSpark、Hadoop、およびFlinkの国内検索インタレストの地域分布(Flink検索インタレストの降順):

過去1年間のSpark、Hadoop、およびFlinkのグローバル検索インタレストの地域分布(Flink検索インタレストの降順):

分析
上記の4つの写真から、過去1年間、国内であろうと世界的であろうと、Sparkの人気はHadoopやFlinkの人気よりも常に高かったことがわかります。近年、Flinkは急速に発展し、中国のAliによって承認されています。Flinkの自然なストリーム処理特性により、Flinkはストリームアプリケーションを開発するための好ましいフレームワークになっています。Flinkは中国では非常に人気がありますが、それでも世界ではSparkほど人気がないことがわかります。そのため、Sparkテクノロジーを学び、習得することは依然として良い選択です。テクノロジーには多くの類似点があります。Sparkを習得してからFlinkを習得した場合は、慣れていると思います。
Sparkの機能
-
高速
Apache Sparkは、DAGスケジューラ、クエリオプティマイザ、および物理実行エンジンを使用して、バッチおよびストリーム処理に高いパフォーマンスを提供します。
-
使いやすい
Java、Scala、Python、R、およびSQLの使用をサポートして、アプリケーションをすばやく作成します。Sparkは、並列アプリケーションを簡単に構築するための80を超える高度な操作オペレーターを提供します。
-
通用性
Sparkは、SQLクエリ、ストリームコンピューティング、マシンラーニング、グラフコンピューティングなどのコンポーネントを含む、非常に豊富なエコロジカルスタックを提供します。これらのコンポーネントは、1つのアプリケーションにシームレスに統合でき、ワンストップ展開を通じて、さまざまな複雑なコンピューティングシナリオを処理できます。
-
さまざまな動作モード
Sparkは、スタンドアロンモードで実行することも、Hadoop、Apache Mesos、Kubernetesなどの環境で実行することもできます。また、HDFS、Alluxio、Apache Cassandra、Apache HBase、ApacheHiveなどの複数のデータソースからデータにアクセスできます。
Sparkのいくつかの重要な概念
-
RDD
分散メモリの抽象的な概念である復元力のある分散データセットは、高度に制限された共有メモリモデルを提供します
-
日
RDD間の依存関係を反映した有向非周期グラフ
-
応用
Sparkユーザー作成プログラム、ドライバープログラム、および実行者の構成
-
アプリケーションjar
ユーザー作成アプリケーションJARパッケージ -
ドライバープログラム
は、プログラムmain()関数のプロセスを使用してSparkContextを作成します -
クラスターマネージャー
クラスターマネージャーは、リソース要求の割り当てに使用される外部サービスです(スタンドアロンマネージャー、Mesos、YARNなど)。 -
デプロイモード
展開モードは、ドライバープロセスを実行する場所を決定します。それがある場合は、クラスタモード、フレームワーク自体は、クラスタ内のマシン上のドライバのプロセスを開始します。それは内にある場合はクライアントモード、ドライバプロセスは、プログラムが提出されているマシン上で起動されます
-
ワーカーノード
クラスタ内でアプリケーションを実行しているノードExecutorは、Worknodeノードで実行されているプロセスであり、特定のタスクの実行とアプリケーションのデータの保存を担当します。
-
executorで実行されている作業のタスクユニット -
ジョブ
ジョブには、複数のRDDと、RDDで実行されている一連のオペレーター操作が含まれています。ジョブは、アクション操作(保存、収集など)によってトリガーされる必要があります。 -
ステージ
各ジョブは、一連のタスクで構成されるステージによって分割されます。
Sparkコンポーネントの概要
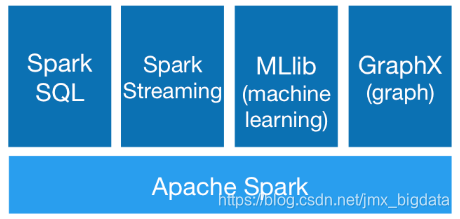
次の図に示すように、Sparkエコシステムには、主にSpark Core、SparkSQL、SparkStreaming、MLlib、GraphXなどのコンポーネントが含まれています。
-
Spark Core
Sparkコアは、メモリコンピューティング、タスクスケジューリング、展開モード、ストレージ管理など、Sparkの基本機能を含むSparkのコアです。SparkCoreは、他の高レベルAPIの基礎となるRDDベースのAPIを提供し、その主な機能はバッチ処理を実装することです。
-
Spark SQL
Spark SQLは、構造化データと半構造化データを処理するように設計されています。SparkSQLを使用すると、ユーザーはSparkプログラムでSQL、DataFrame、およびDataSetAPIを使用して構造化データを照会でき、Java、Scala、Python、およびR言語をサポートします。DataFrame APIは、さまざまなデータソース(Hive、Avro、Parquet、ORC、JDBCなど)にアクセスするための統一された方法を提供するため、ユーザーは同じ方法で任意のデータソースに接続できます。さらに、Spark SQLはHiveメタデータを使用できるため、Hiveとの完全な統合を実現できます。ユーザーはSparkで直接Hiveジョブを実行できます。Spark SQLには、spark-sqlシェルコマンドを使用してアクセスできます。
-
SparkStreaming
SparkStreamingは、Sparkの非常に重要なモジュールであり、リアルタイムデータストリームのスケーラビリティ、高スループット、およびフォールトトレラントなストリーム処理を実現できます。内部的には、その作業方法は、リアルタイムの入力データストリームを一連のマイクロバッチに分割し、Sparkエンジンによって処理することです。SparkStreamingは、kafka、Flume、TCPソケットなどの複数のデータソースをサポートします。
-
MLlib
MLlibは、Sparkが提供する機械学習ライブラリです。ユーザーはSpark APIを使用して機械学習アプリケーションを構築できます。Sparkは特に反復コンピューティングに優れており、そのパフォーマンスはHadoopの100倍です。libには、ロジスティック回帰、サポートベクトルマシン、分類、クラスタリング、回帰、ランダムフォレスト、協調フィルタリング、主成分分析などの一般的なマシン学習アルゴリズムが含まれています。
-
GraphX
GraphXは、Sparkでのグラフコンピューティング用のAPIです。これは、SparkでのPregelの書き直しと最適化と見なすことができます。GraphXは、優れたパフォーマンス、豊富な機能と演算子を備えており、大量のデータに対して複雑なグラフアルゴリズムを自由に実行できます。GraphXには、有名なPageRankアルゴリズムなど、多くの組み込みグラフアルゴリズムがあります。
Sparkオペレーティングアーキテクチャの概要
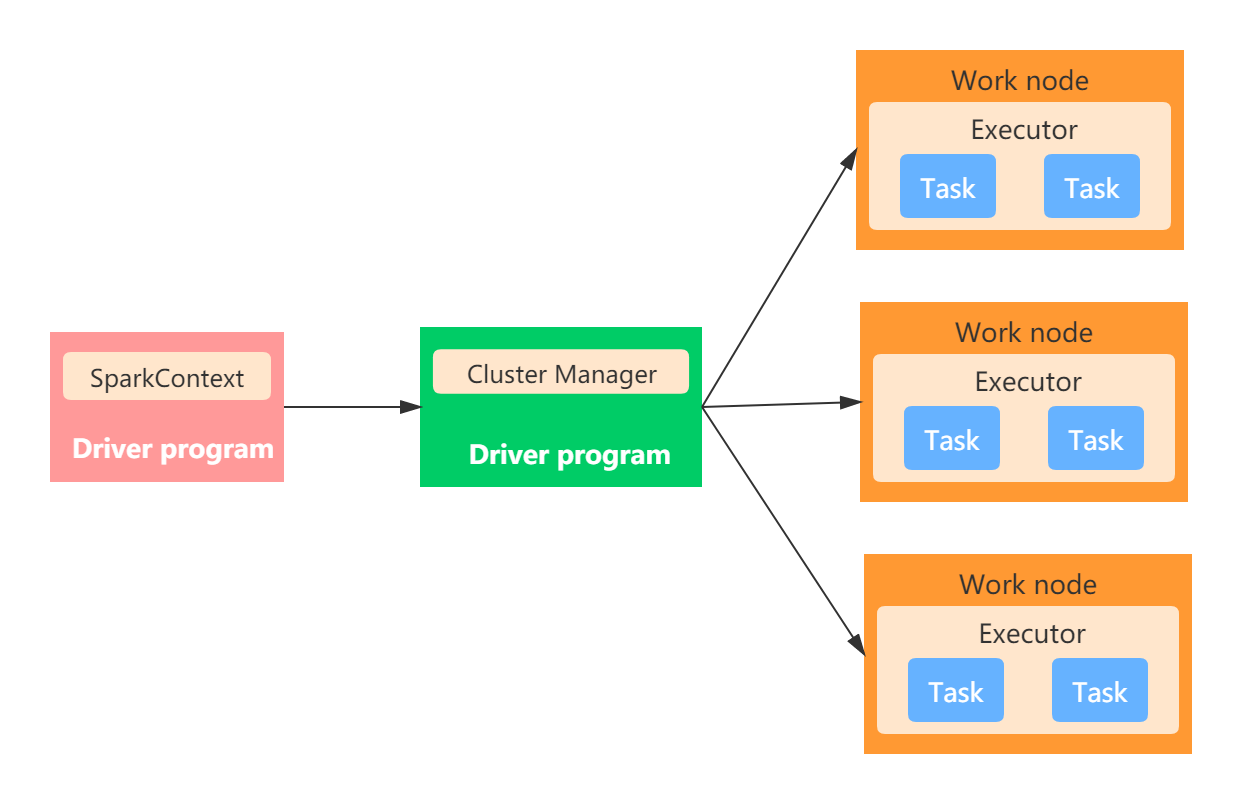
全体として、Sparkアプリケーションアーキテクチャには次の主要部分が含まれています。
- ドライバープログラム
- マスターノード
- 作業ノード
- エグゼキュータ
- タスク
- SparkContext
スタンドアロンモードで動作してアーキテクチャを以下の図に示されています。
ドライバープログラム
ドライバープログラムは、Sparkアプリケーションのmain()関数です(SparkContextおよびSparkセッションを作成します)。Driverプロセスを実行しているノードはDriverノードと呼ばれます。DriverプロセスはClusterManagerと通信し、スケジュールされたタスクをExecutorに送信します。
クラスターマネージャー
これはクラスターマネージャーと呼ばれ、主にクラスターの管理に使用されます。一般的なクラスターマネージャーには、YARN、Mesos、およびスタンドアロンが含まれます。スタンドアロンクラスターマネージャーには、2つの長時間実行バックグラウンドプロセスが含まれ、1つはマスターノードにあり、もう1つはワークノードにあります。フォローアップクラスター展開モードの記事では、この部分の内容について詳しく説明します。これが一般的な印象です。
ワーカーノード
Hadoopに精通している友人は、Hadoopにnamenodeノードとdatanodeノードが含まれていることを知っておく必要があります。Sparkも同様で、Sparkは特定のタスクを実行するノードをワーカーノードと呼びます。ノードは、現在のノードの使用可能なリソースをマスターノードに報告します。通常、各ワーカーノードで作業バックグラウンドプロセスが開始され、エグゼキューターが起動および監視されます。
エグゼキュータ
マスターノードはリソースを割り当て、クラスター内の作業ノードを使用してエグゼキューターを作成し、ドライバーはこれらのエグゼキューターを使用して特定のタスクを割り当てて実行します。各アプリケーションには独自のExecutorプロセスがあり、複数のスレッドを使用して特定のタスクを実行します。Executorは、主にタスクの実行とデータの保存を担当します。
仕事
タスクは、Executorに送信される作業の単位です。
SparkContext
SparkContextはSparkセッションへの入り口であり、Sparkクラスターに接続するために使用されます。アプリケーションを送信する前に、まずSparkContextを初期化する必要があります。SparkContextは、ネットワーク通信、ストレージシステム、コンピューティングエンジン、WebUI、およびその他のコンテンツを意味します。JVMプロセスにはSparkContextが1つしか存在できないことに注意してください。新しいSparkContextを作成する場合は、元のSparkContextでstop()メソッドを呼び出す必要があります。
Sparkプログラミングトライアル
グループ化とtopNケースのSpark実装
説明:HDFSの注文データ用のorder.txtファイルがあります。ファイルフィールドにはセグメンテーション記号 "、"があり、フィールドは注文ID、商品ID、トランザクション金額を順番に示します。サンプルデータは次のとおりです。
Order_00001,Pdt_01,222.8
Order_00001,Pdt_05,25.8
Order_00002,Pdt_03,522.8
Order_00002,Pdt_04,122.4
Order_00002,Pdt_05,722.4
Order_00003,Pdt_01,222.8
質問:sparkcoreを使用して、各注文で最大の売上高を持つ製品のIDを見つけます
実装コード
import org.apache.spark.sql.Row
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.{SparkConf, SparkContext}
object TopOrderItemCluster {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("top n order and item")
val sc = new SparkContext(conf)
val hctx = new HiveContext(sc)
val orderData = sc.textFile("data.txt")
val splitOrderData = orderData.map(_.split(","))
val mapOrderData = splitOrderData.map { arrValue =>
val orderID = arrValue(0)
val itemID = arrValue(1)
val total = arrValue(2).toDouble
(orderID, (itemID, total))
}
val groupOrderData = mapOrderData.groupByKey()
/**
***groupOrderData.foreach(x => println(x))
***(Order_00003,CompactBuffer((Pdt_01,222.8)))
***(Order_00002,CompactBuffer((Pdt_03,522.8), (Pdt_04,122.4), (Pdt_05,722.4)))
***(Order_00001,CompactBuffer((Pdt_01,222.8), (Pdt_05,25.8)))
*/
val topOrderData = groupOrderData.map(tupleData => {
val orderid = tupleData._1
val maxTotal = tupleData._2.toArray.sortWith(_._2 > _._2).take(1)
(orderid, maxTotal)
}
)
topOrderData.foreach(value =>
println("最大成交额的订单ID为:" + value._1 + " ,对应的商品ID为:" + value._2(0)._1)
/**
***最大成交额的订单ID为:Order_00003 ,对应的商品ID为:Pdt_01
***最大成交额的订单ID为:Order_00002 ,对应的商品ID为:Pdt_05
***最大成交额的订单ID为:Order_00001 ,对应的商品ID为:Pdt_01
*/
)
//构造出元数据为Row的RDD
val RowOrderData = topOrderData.map(value => Row(value._1, value._2(0)._1))
//构建元数据
val structType = StructType(Array(
StructField("orderid", StringType, false),
StructField("itemid", StringType, false))
)
//转换成DataFrame
val orderDataDF = hctx.createDataFrame(RowOrderData, structType)
// 将数据写入Hive
orderDataDF.registerTempTable("tmptable")
hctx.sql("CREATE TABLE IF NOT EXISTS orderid_itemid(orderid STRING,itemid STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'")
hctx.sql("INSERT INTO orderid_itemid SELECT * FROM tmptable")
}
}
上記のコードをパッケージ化し、クラスターに送信して実行します。hivecliまたはspark-sqlシェルを入力して、Hiveでデータを表示できます。
総括する
この記事では、主にSparkの検索人気分析、Sparkの主な機能、Sparkのいくつかの重要な概念、Sparkの実行アーキテクチャなど、Spark全体を紹介し、最後にSparkプログラミングの事例を示します。この記事は、Sparkシリーズで共有される最初の記事です。最初にSparkのグローバルな展望を感じることができます。次の記事では、SparkCoreプログラミングガイドを共有します。
