HahsMapの知識を整理するために、記事の構造とアイデアは次のとおりです。

目次
アレイ+リンクリスト+赤黒ツリー(JDK1.8は赤黒ツリー部分を追加します)
1.7および1.8でのhashMapの最適化について話します
HashMapスレッドは安全ですか?安全にスレッドを作成する方法はありますか
いくつかの主要な関数get()、put()、resize()、replace()、remove()の論理的なアイデアについて話します
1.主な機能
- 基礎となる実装は、リンクリスト配列+赤黒ツリー、ジッパーメソッドです。
- キーはSetに保存され、繰り返しは許可されません。キーをオブジェクトとして使用する場合は、hashCodeメソッドとequalsメソッドを書き直す必要があります。
- 空のキーと空の値を許可しますが、空のキーは1つだけです
- 要素は無秩序であり、順序は時々変更されます
- 挿入と取得の時間の複雑さは基本的にO(1)です(適切なハッシュ関数があり、要素が均一な位置に分散されている場合)
- 2つの重要な要素:初期容量、負荷率
2.継承
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {


3、データ構造
アレイ+リンクリスト+赤黒ツリー(JDK1.8は赤黒ツリー部分を追加します)
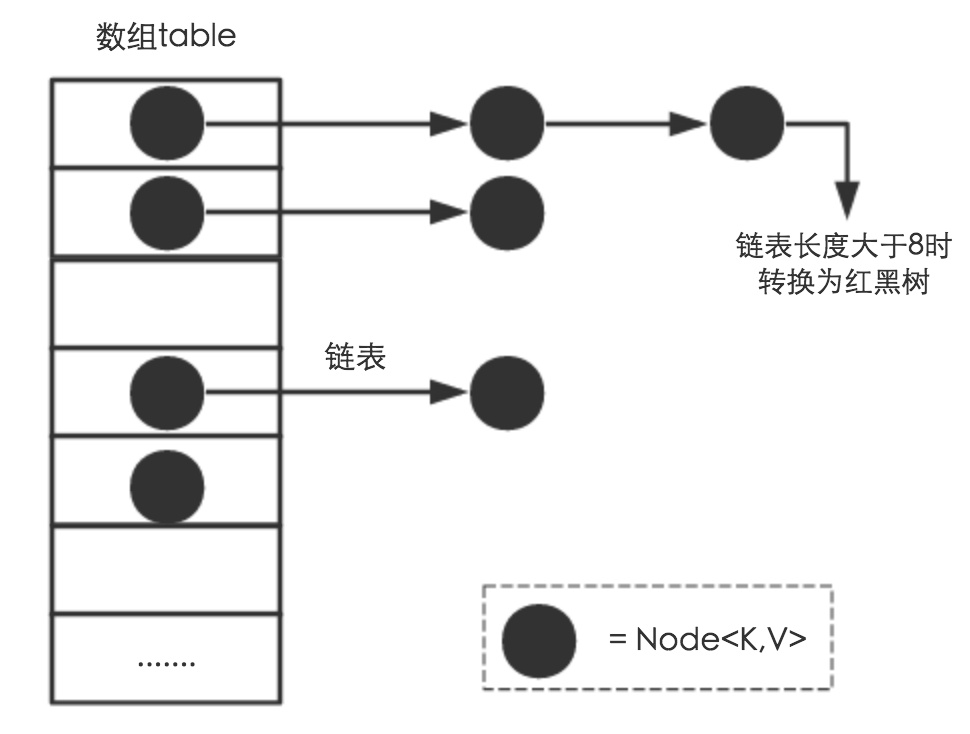
主な要素
/**
* 默认初始容量16——必须是2的幂
* 01向左补四位,2的四次方
* hashCode & (length-1); 15位与14位相比,与hashcode相与会有更多的结果,且不浪费空间
* 所以将length定位二次幂,在进行hash运算时,不同的key算得index相同的几率较小,那么数据在数组上分布就比较均匀,
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* 最大容量,必须是2的幂 2的30次方
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 载荷因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* treeify_threshold由链表转化为红黑书的阀值
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 红黑树节点转换链表节点的阈值
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* 转红黑树时数组应该满足的长度
* 至少是 4 * TREEIFY_THRESHOLD ,节省效率
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* 基本的哈希节点,链表节点, 继承自Entry
* k,v是Map<k,v>传入的数据类型
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
@Override
public final K getKey() { return key; }
@Override
public final V getValue() { return value; }
@Override
public final String toString() { return key + "=" + value; }
@Override
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
@Override
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
@Override
public final boolean equals(Object o) {
//存储位置相同
if (o == this) {
return true;
}
//instanceof是Java中的一个双目运算符,用来测试一个对象是否为一个类的实例
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return Objects.equals(key, e.getKey()) && Objects.equals(value,
e.getValue());
}
return false;
}
}
//将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会被序列化。
//table数组
transient Node<K,V>[] table;
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set<Map.Entry<K,V>> entrySet;
// 大小
transient int size;
transient int modCount;
/**
* 转化为红黑树的阀值
*/
int threshold;
/**
* 哈希表的负载系数。
*/
final float loadFactor;優れたハッシュアルゴリズムと拡張メカニズムにより、ハッシュの衝突の可能性を小さくすることができ、ハッシュバケット配列(Node []テーブル)が占めるスペースが少なくなります。
第四に、コアメソッド分析
ハッシュ()
最初のステップはkey.hashCode()を取得することです
上位16ビットの排他的OR操作の2番目のステップ
(>>>は、論理右シフトとも呼ばれる符号なし右シフトを意味します。つまり、数値が正の場合、上位ビットは0で埋められ、数値が負の場合、上位ビットは右シフト後も同じです。補数0)
ハッシュアルゴリズムは、基本的に3つのステップです。キーのhashCode値の取得、高次操作、およびモジュロ操作です。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
これは、key.hashcode()を添え字に変更するプロセス全体を示す図です。
この計算プロセスを通じて、生成されたアレイインデックスは、「外乱」の増加による衝突の可能性を低減することがわかります。
比較可能なClassFor()
/**
* Returns x's Class if it is of the form "class C implements
* Comparable<C>", else null.
*/
static Class<?> comparableClassFor(Object x) {
if (x instanceof Comparable) {
Class<?> c; Type[] ts, as; Type t; ParameterizedType p;
if ((c = x.getClass()) == String.class) // bypass checks
return c;
if ((ts = c.getGenericInterfaces()) != null) {
for (int i = 0; i < ts.length; ++i) {
if (((t = ts[i]) instanceof ParameterizedType) &&
((p = (ParameterizedType)t).getRawType() ==
Comparable.class) &&
(as = p.getActualTypeArguments()) != null &&
as.length == 1 && as[0] == c) // type arg is c
return c;
}
}
}
return null;
}
/**
* Returns k.compareTo(x) if x matches kc (k's screened comparable
* class), else 0.
*/
@SuppressWarnings({"rawtypes","unchecked"}) // for cast to Comparable
static int compareComparables(Class<?> kc, Object k, Object x) {
return (x == null || x.getClass() != kc ? 0 :
((Comparable)k).compareTo(x));
}
tableSizeFor()
【機能】所定の目標容量の2倍の累乗に戻します。着信容量を2 ^ Nより大きく最も近い値に設定します
[解釈]
詳細については、以下を参照してください。2^ Nより大きくて最も近い数を見つける
//补位,将原本为0的空位填补为1,最后加1时,最高有效位进1,其余变为0,如此就可以取到最近的2的幂
static final int tableSizeFor(int cap) {
//减一后,最右一位肯定和cap的最右一位不同,即一个为0,一个为1
int n = cap - 1;
//(>>>)无符号右移一位,(|)按位或
n |= n >>> 1;
//(>>>)无符号右移两位,(|)按位或
n |= n >>> 2;
//(>>>)无符号右移四位,(|)按位或
n |= n >>> 4;
//(>>>)无符号右移八位,(|)按位或
n |= n >>> 8;
//(>>>)无符号右移十六位,(|)按位或,为何到16呢,存疑
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}HashMap()
初期容量と負荷率を指定し、パラメータを確認します。
初期容量を負の数値にしたり、最大容量を超えたりすることはできません1 << 30(2 ^ 30)
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0) {
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
}
if (initialCapacity > MAXIMUM_CAPACITY) {
initialCapacity = MAXIMUM_CAPACITY;
}
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
}
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
/**
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public HashMap1(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}取得する()
public V get(Object key) {
Node<K,V> e;
//还是先计算 哈希值
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//tab 指向哈希表,n 为哈希表的长度,first 为 (n - 1) & hash 位置处的桶中的头一个节点
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//如果桶里第一个元素就相等,直接返回
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//否则就得慢慢遍历找
if ((e = first.next) != null) {
if (first instanceof TreeNode)
//如果是树形节点,就调用树形节点的 get 方法
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
//do-while 遍历链表的所有节点
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
put()
これは偉大な神、Zhihuからの関連する回答です。写真の説明は非常に鮮やかで、次のように引用されています。
(回答へのリンクは次のとおりです:https://zhuanlan.zhihu.com/p/21673805)
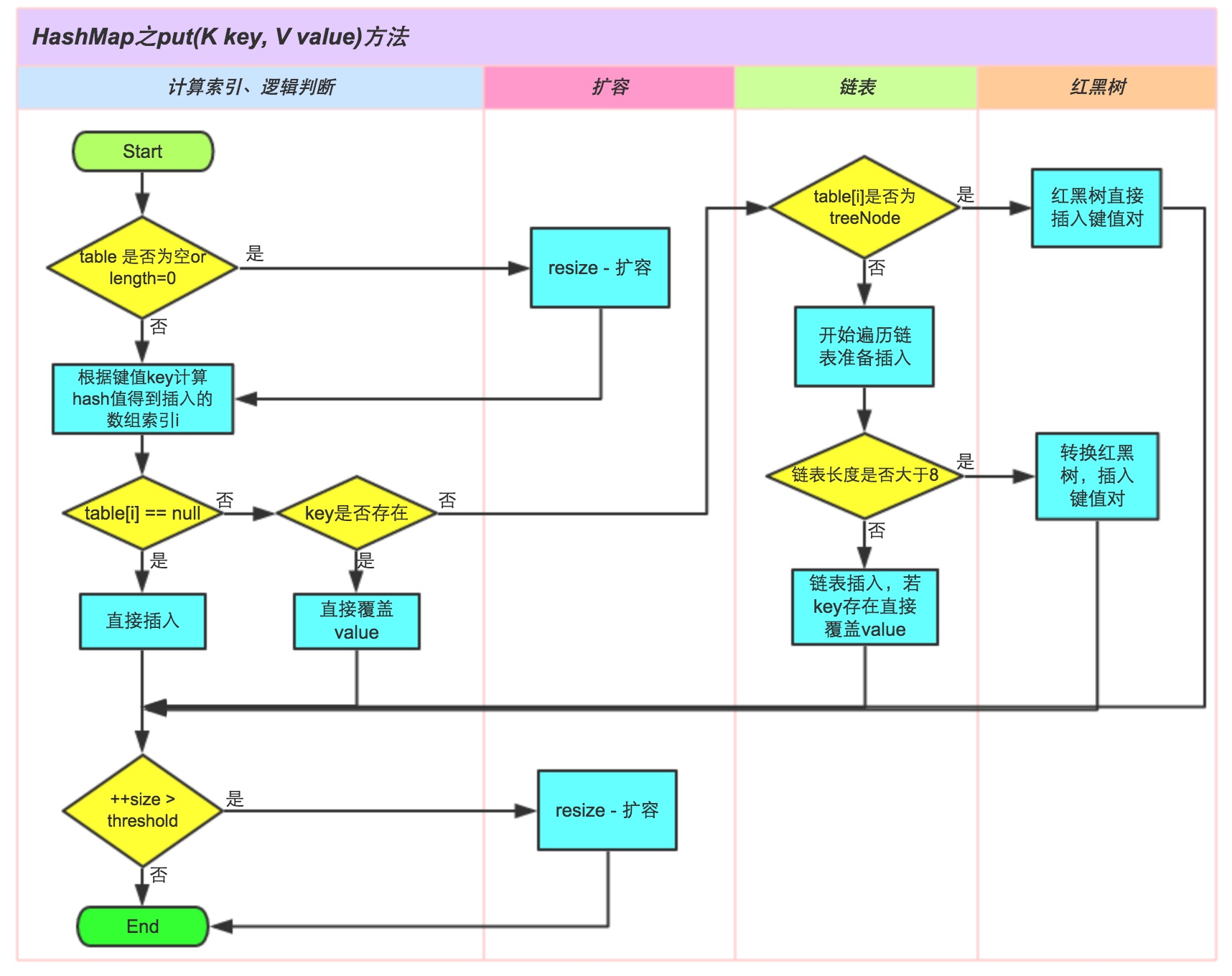
アレイは、直接要素を挿入しない位置に配置されている場合、
標的配列要素が挿入されたキーと場所比較する必要がある場合
、同じキーカバーが直接場合
、キーが同じでない場合、pはツリーノードであるか否かが判断される
場合はいの場合は、e =((TreeNode <K、V>)p).putTreeVal(this、tab、hash、key、value)を呼び出して要素を追加します。
そうでない場合は、リストの最後をトラバースして挿入します。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 1.校验table是否为空或者length等于0,如果是则调用resize方法进行初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 2.通过hash值计算索引位置,将该索引位置的头节点赋值给p,如果p为空则直接在该索引位置新增一个节点即可
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// table表该索引位置不为空,则进行查找
Node<K,V> e; K k;
// 3.判断p节点的key和hash值是否跟传入的相等,如果相等, 则p节点即为要查找的目标节点,将p节点赋值给e节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 4.判断p节点是否为TreeNode, 如果是则调用红黑树的putTreeVal方法查找目标节点
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 5.走到这代表p节点为普通链表节点,则调用普通的链表方法进行查找,使用binCount统计链表的节点数
for (int binCount = 0; ; ++binCount) {
// 6.如果p的next节点为空时,则代表找不到目标节点,则新增一个节点并插入链表尾部
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 7.校验节点数是否超过8个,如果超过则调用treeifyBin方法将链表节点转为红黑树节点,
// 减一是因为循环是从p节点的下一个节点开始的
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
// 8.如果e节点存在hash值和key值都与传入的相同,则e节点即为目标节点,跳出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e; // 将p指向下一个节点
}
}
// 9.如果e节点不为空,则代表目标节点存在,使用传入的value覆盖该节点的value,并返回oldValue
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); // 用于LinkedHashMap
return oldValue;
}
}
++modCount;
// 10.如果插入节点后节点数超过阈值,则调用resize方法进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict); // 用于LinkedHashMap
return null;
}resize()
拡張、1.7の拡張では、長さを変更した後にすべてのハッシュコードを再計算する必要があり、これには多くの費用がかかります。1.8の拡張では、メカニズムはより巧妙になり、計算を節約し、特定の変更後に学習します。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
// 1.老表的容量不为0,即老表不为空
if (oldCap > 0) {
// 1.1 判断老表的容量是否超过最大容量值:如果超过则将阈值设置为Integer.MAX_VALUE,并直接返回老表,
// 此时oldCap * 2比Integer.MAX_VALUE大,因此无法进行重新分布,只是单纯的将阈值扩容到最大
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 1.2 将newCap赋值为oldCap的2倍,如果newCap<最大容量并且oldCap>=16, 则将新阈值设置为原来的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// 2.如果老表的容量为0, 老表的阈值大于0, 是因为初始容量被放入阈值,则将新表的容量设置为老表的阈值
else if (oldThr > 0)
newCap = oldThr;
else {
// 3.老表的容量为0, 老表的阈值为0,这种情况是没有传初始容量的new方法创建的空表,将阈值和容量设置为默认值
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 4.如果新表的阈值为空, 则通过新的容量*负载因子获得阈值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 5.将当前阈值设置为刚计算出来的新的阈值,定义新表,容量为刚计算出来的新容量,将table设置为新定义的表。
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// 6.如果老表不为空,则需遍历所有节点,将节点赋值给新表
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) { // 将索引值为j的老表头节点赋值给e
oldTab[j] = null; // 将老表的节点设置为空, 以便垃圾收集器回收空间
// 7.如果e.next为空, 则代表老表的该位置只有1个节点,计算新表的索引位置, 直接将该节点放在该位置
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 8.如果是红黑树节点,则进行红黑树的重hash分布(跟链表的hash分布基本相同)
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 9.如果是普通的链表节点,则进行普通的重hash分布
Node<K,V> loHead = null, loTail = null; // 存储索引位置为:“原索引位置”的节点
Node<K,V> hiHead = null, hiTail = null; // 存储索引位置为:“原索引位置+oldCap”的节点
Node<K,V> next;
do {
next = e.next;
// 9.1 如果e的hash值与老表的容量进行与运算为0,则扩容后的索引位置跟老表的索引位置一样
if ((e.hash & oldCap) == 0) {
if (loTail == null) // 如果loTail为空, 代表该节点为第一个节点
loHead = e; // 则将loHead赋值为第一个节点
else
loTail.next = e; // 否则将节点添加在loTail后面
loTail = e; // 并将loTail赋值为新增的节点
}
// 9.2 如果e的hash值与老表的容量进行与运算为非0,则扩容后的索引位置为:老表的索引位置+oldCap
else {
if (hiTail == null) // 如果hiTail为空, 代表该节点为第一个节点
hiHead = e; // 则将hiHead赋值为第一个节点
else
hiTail.next = e; // 否则将节点添加在hiTail后面
hiTail = e; // 并将hiTail赋值为新增的节点
}
} while ((e = next) != null);
// 10.如果loTail不为空(说明老表的数据有分布到新表上“原索引位置”的节点),则将最后一个节点
// 的next设为空,并将新表上索引位置为“原索引位置”的节点设置为对应的头节点
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 11.如果hiTail不为空(说明老表的数据有分布到新表上“原索引+oldCap位置”的节点),则将最后
// 一个节点的next设为空,并将新表上索引位置为“原索引+oldCap”的节点设置为对应的头节点
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
// 12.返回新表
return newTab;
}treeifyBin()
/**
* 将链表节点转为红黑树节点
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 1.如果table为空或者table的长度小于64, 调用resize方法进行扩容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
// 2.根据hash值计算索引值,将该索引位置的节点赋值给e,从e开始遍历该索引位置的链表
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
// 3.将链表节点转红黑树节点
TreeNode<K,V> p = replacementTreeNode(e, null);
// 4.如果是第一次遍历,将头节点赋值给hd
if (tl == null) // tl为空代表为第一次循环
hd = p;
else {
// 5.如果不是第一次遍历,则处理当前节点的prev属性和上一个节点的next属性
p.prev = tl; // 当前节点的prev属性设为上一个节点
tl.next = p; // 上一个节点的next属性设置为当前节点
}
// 6.将p节点赋值给tl,用于在下一次循环中作为上一个节点进行一些链表的关联操作(p.prev = tl 和 tl.next = p)
tl = p;
} while ((e = e.next) != null);
// 7.将table该索引位置赋值为新转的TreeNode的头节点,如果该节点不为空,则以以头节点(hd)为根节点, 构建红黑树
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}compute()
@Override
public V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
if (remappingFunction == null)
throw new NullPointerException();
int hash = hash(key);
Node<K,V>[] tab; Node<K,V> first; int n, i;
int binCount = 0;
TreeNode<K,V> t = null;
Node<K,V> old = null;
if (size > threshold || (tab = table) == null ||
(n = tab.length) == 0)
n = (tab = resize()).length;
if ((first = tab[i = (n - 1) & hash]) != null) {
if (first instanceof TreeNode)
old = (t = (TreeNode<K,V>)first).getTreeNode(hash, key);
else {
Node<K,V> e = first; K k;
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
old = e;
break;
}
++binCount;
} while ((e = e.next) != null);
}
}
V oldValue = (old == null) ? null : old.value;
V v = remappingFunction.apply(key, oldValue);
if (old != null) {
if (v != null) {
old.value = v;
afterNodeAccess(old);
}
else
removeNode(hash, key, null, false, true);
}
else if (v != null) {
if (t != null)
t.putTreeVal(this, tab, hash, key, v);
else {
tab[i] = newNode(hash, key, v, first);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
}
++modCount;
++size;
afterNodeInsertion(true);
}
return v;
}5、インタビューの質問
hashMapとhashTableの違い
- HashMapではキーと値をnullにすることができますが、Hashtableではできません。
- HashMapのデフォルトの初期容量は16で、Hashtableは11です。
- HashMapの展開は2倍になり、Hashtableの展開は2倍になります。
- HashMapはスレッドセーフではなく、Hashtableはスレッドセーフです。
- HashMapのハッシュ値が再計算され、HashtableはhashCodeを直接使用します。
- HashMapは、Hashtableのcontainsメソッドを削除します。
- HashMapはAbstractMapクラスを継承し、HashtableはDictionaryクラスを継承します。
1.7および1.8でのhashMapの最適化について話します
- 基になるデータ構造により、赤黒のツリー構造が追加されます。デフォルトの変更しきい値は、配列長> 64、リンクリスト長> 8です。検索操作では、ノード配列ノードの下のリンクリストをトラバースする必要があります。バケット長が長すぎると、クエリが削減されます。効率が良いため、1.8で赤黒ツリーが追加されます。この構造は、データ量が多い場合に追加、削除、変更、およびチェックを高速化します。リンクリストの長さが6未満になると、赤黒ツリーは再びリンクリストに変換されます。リンクリストO(n)、黒い木O(logn)
- 高レベルの操作用にハッシュアルゴリズムを最適化します。h^(h >>> 16)、4つの摂動が1つの摂動になり、効率が向上します
- 追加すると、ヘッドプラグがテールプラグになり、ヘッドプラグ方式でリンクリストが反転します。マルチスレッド環境では、ヘッドプラグでループが発生し、テールプラグが反転しないので安全です。
- 拡張メカニズム、resize()拡張メカニズム、拡張しきい値=設定容量*負荷係数(16 * 0.75)を最適化します。しきい値に達すると、拡張は現在の2倍になります。最もコストのかかるパフォーマンスは、1.8で最適化された、展開後のインデックス値の再計算です。index= h&(length-1)。展開後、要素は元の位置にあるか、元の位置に2の累乗で移動します。 、およびリンクされたリストの順序は変更されません
HashMapスレッドは安全ですか?安全にスレッドを作成する方法はありますか
- スレッドセーフではありません。1.7では、リンクされたリストループ、繰り返しの挿入があり、ソースコードにロック操作はありません。
- スレッドの安全性を実現するには、Tablemap、ConcerrentHashMap、Collections.synchronizedMapの3つのメソッドがあり、tableMapは操作メソッド全体をロックし、粒度が大きすぎます。基本的に適切な使用シナリオはありません。Collections.synchronizedMapはCollectionsの内部クラスであり、マップが渡されます。ロック付きの内部定義のsynchronizedMapオブジェクトに、スレッドの安全性を実現できます。ConcerrentHashMapは、セグメント化されたロック(現在のノードをロック)を使用し、CAS +同期し、ロックの粒度を減らし、同時実行量を増やします。
ハッシュ関数はどのように設計されていますか
最初にキーのハッシュコード(32ビット)を取得してから、ハッシュコードの上位16ビットと下位16ビットでXOR操作を実行します。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
詳細を教えていただけますか、メリットは何ですか?
これは摂動関数と呼ばれ、ハッシュコードの上位16ビットと下位16ビットに対して排他的OR演算を実行します
。2つの利点があります。
- ビット操作はアルゴリズムの効率を向上させることができます
- 高レベルが添え字の計算に参加していないために衝突が増加することはなく、ハッシュコードのハッシュコードが増加します。
この設計がハッシュ性を向上させる理由
key.hashCode()は、キー自体のハッシュ値から派生しますが、これは大きすぎるため、配列の長さ-1(0は0)とAND演算する必要があります。
この操作により、数値を小さくすることができますが、問題が発生します。つまり、最後の数桁だけが取得され、衝突の可能性が高くなります。
したがって、変調するデータの変動性を高める方法が必要です。上記のハッシュの高次XOR演算は、この問題を解決するように設計されています。
これは、元のハッシュコードの上位ビットと下位ビットをXORに結合します。これにより、低い位置のランダム性が高まります。
LinkedHashMapはどのように整然と達成しますか
LinkedHashMapは、ヘッドノードとテールノードを含む単一リンクリストを内部的に維持します。同時に、LinkedHashMapノードエントリは、HashMapのNode属性を継承するだけでなく、フロントノードとリアノード
を識別するために使用される前後もあります。挿入順またはアクセス順で並べ替えることができます。
いくつかの主要な関数get()、put()、resize()、replace()、remove()の論理的なアイデアについて話します
put&replace、removeなどの変更を伴う操作には、次の検証と処理が必要です。
配列が空かどうか-put&replace操作で作成され、remove操作で返されます
ターゲット配列が存在するかどうか、およびキーが存在するかどうか-ノードは配列が存在するかどうかを判断し、put&replace操作(ノードが存在する場合はreplace、ノードが存在しない場合はcreate)、remove操作(ノードが存在する場合はdelete、ノードが存在しない場合はreturn)を判断します。
ノードストレージはリンクリストまたは赤黒ツリーを形成していますか
操作が完了した後、拡張/縮小のしきい値に達しているかどうか-拡張/赤黒ツリーとリンクリストの変換
その他の詳細な分析については、上記の主なメソッド分析を参照してください。
6、参考資料
https://blog.csdn.net/java_wxid/article/details/106896221?utm_source=app
https://zhuanlan.zhihu.com/p/21673805
https://blog.csdn.net/v123411739/article/details/78996181
https://blog.csdn.net/u012211603/article/details/79879944
https://blog.csdn.net/qq_41345773/article/details/92066554