
著者:少しヘルパー
出典:Dingdianがお手伝いします
前回の記事では、タイタニック号の難破船での乗客の生存率を使用して、記述的なデータ分析を紹介し、さまざまなキャビンでの乗客の生存率を計算しました。今日は、画像を使用して直感的に表現する方法を見ていきます。
titanic.csvの内容を簡単に確認しましょう。
#データをインポートする titanic <-read.csv( "// Users // Desktop // titanic.csv"、header = TRUE) names(titanic)#titanic head(titanic)で変数名を表示する#titanic の最初の6行を表示する
前回の記事で計算した、さまざまなクラスの乗客の死亡者数と生存者数は次のとおりです。
テーブル(タイタニック$はチタンの$ PCLASS、生き残った)
第一第二第三は、
死亡した123 158 528
200 119 181を生き延びました
さまざまなキャビンの生存率:
survpct = paste(round(tab1 [2、] / apply(tab1,2、sum)* 100,2)、 "%"、sep = "") survpct [1] "61.92%" "42.96%" "25.53% 「」
さまざまなクラスの乗客の生存率を視覚的に説明する場合は、次のアプローチを使用できます。
ヒストグラムを描く
barplot(table(titanic $ Survived、titanic $ pclass))
barplot()は、ヒストグラムを描画するための関数です。この関数の括弧内のコマンドは、描画に必要なデータです。これは、以前に計算したさまざまなキャビンでの死亡者と生存者の数です。
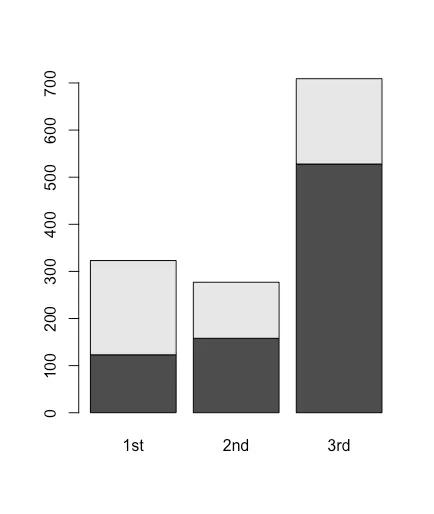
ヒストグラムの色も調整できます。次のコードでは、colはヒストグラムの色を変更するコマンドです。
barplot(table(titanic $ Survived、titanic $ pclass)、
col = c( "yellow"、 "dark blue"))
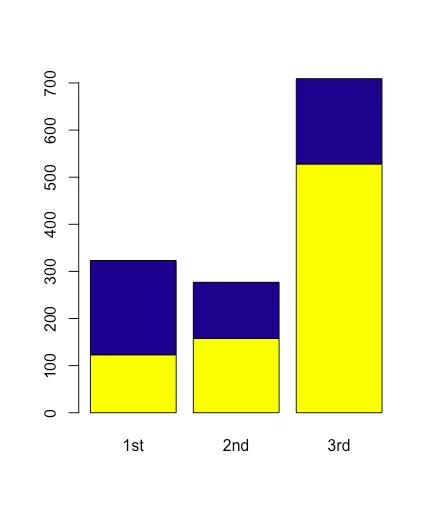
各コンパートメントの死者と生存者の数の配置も調整できます。「beside」はヒストグラムの配置を変更するコマンドです。beside= Tは2つの列が並んでいることを意味し、beside = Fは2つの列が互いに積み重ねられていることを意味します。
barplot(table(titanic $ Survived、titanic $ pclass)、
col = c( "yellow"、 "dark blue")、beside = T)

この時点で、数字を直感的な画像に変えることができますが、黄色と青の列は生存者または死者を表していますか?さらに、画像のタイトルなどの重要な情報はマークされていないため、次の手順で画像の読みやすさを向上させる必要があります。
凡例、タイトル、軸ラベルなどを設定します。
この方法は比較的簡単です。上記のコードに基づいて、いくつかのコマンドを追加します。
barplot(table(titanic $ Survived、titanic $ pclass)、
col = c( "yellow"、 "dark blue")、
beside = T、legend = T、args.legend = list(x = "topleft")、
main = "乗客クラス別の生存率(Pct)"、
xlab = "Class"、ylab = "Count"、
ylim = c(0,600))
legendは、凡例を設定するコマンドです。args.legendは、凡例の位置を設定するコマンドです。
mainは、図のタイトルを設定するコマンドです。
xlabとylabは、それぞれx軸とy軸の名前を設定するコマンドです。
ylimは、y軸の範囲を設定するコマンドです。
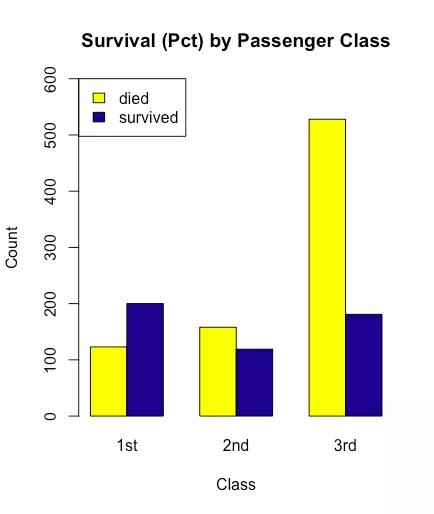
この画像から、ファーストクラスのキャビンの生存者数は3つのキャビンの中で最も多く、サードクラスのキャビンの死亡者数は他の2つのキャビンよりもはるかに多いことがはっきりとわかります。しかし、この画像には、各コンパートメントの生存率という1つの情報がまだ不足しています。各コンパートメントの柱に、次のようにマークを付けることができます。
text(c(2,5,8)、c(250,250,570)、survpct、cex = 1.2)
text()は、画像にテキストを追加する関数です。
最初の2つのコマンドはテキストの位置情報です。最初のコマンドはx軸方向のテキストの位置情報です。c(2,5,8)は、テキストが2、5、8のx値に配置されることを意味します。
2番目のコマンドは、テキストのy軸方向の位置情報を追加します。c(250、250、570)は、テキストをそれぞれ250、250、570のy値に配置することを意味します。
3番目のコマンドはテキストの特定の内容であり、survpctは前のプログラムの結果であり、1級、2級、および3級の乗客の生存率です。
4番目のコマンドcexはテキストのフォントサイズで、デフォルト値は1で、ここでは1.2に設定されています。これは、デフォルトのフォントサイズよりも20%大きいことを意味します。

上記のコードのデフォルトは英語のタイトル、x軸、y軸のテキストですが、中国語に設定する必要がある場合もあります。現時点では、上記のコードに「font(family)」コマンドを追加するだけで済みます。テキストは中国語に設定されています。
barplot(table(titanic $ Survived、titanic $ pclass)、col = c( "red"、 "blue")、
beside = T、legend = T、args.legend = list(x = "topleft")、
main = "異なるクラスの乗客の生存数(レート) "、xlab =" class "、ylab ="人数 "、family =" SimHei "、
ylim = c(0,600))
familyコマンドでは、フォントの英語名を割り当てる必要があります。この記事では、フォントを太字の「SimHei」に設定します。

他のフォントもここで設定できます。一般的な中国語フォントの英語名は次のリンクにまとめられており、必要に応じて選択できます。

一部のフォントの中国語と英語の名前。情報は以下のリンクから取得されます。
http://guangzheng.name/2017/12/18/%E5%A6%82%E4%BD%95%E8%B0%83%E6%95%B4R%E8%AF%AD%E8%A8%80 %E7%BB%98%E5%9B%BE%E7%9A%84%E5%AD%97%E4%BD%93 /