目次
前回のブログでは、Redisのインストール方法を紹介しましたが、 Redis の解凍ディレクトリに非常に重要な構成ファイル redis.conf(/opt/redis-4.0.9ディレクトリの下)があります。Redisの多くの機能の構成はこちらです。これは、前回の講義で述べたように、ファイルで行われます。通常、インストールされたファイルを損傷しないようにするため、工場出荷時のデフォルト構成を変更しないことをお勧めします。そのため、この構成ファイルを/ etc / redis /ディレクトリにコピーしました。
このファイルをvim /etc/redis/redis.confコマンドで開きます。以下に、この構成ファイルを詳しく紹介します。
ps:これらの構成の意味を理解していなくてもかまいません。後で具体例で紹介します。最初に慣れるだけです。
1.最初に
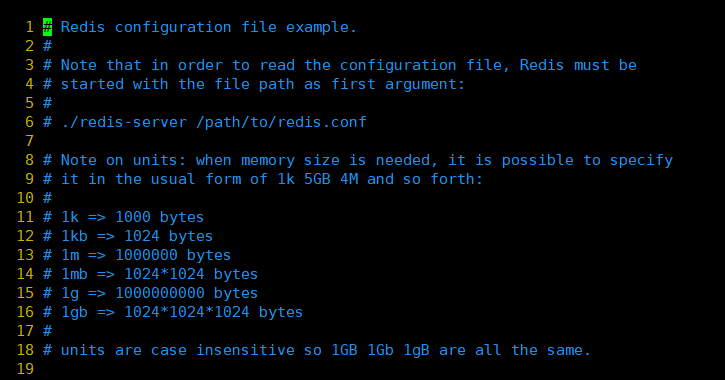
ここで何も言うことはありませんが、後でメモリサイズを使用する必要がある場合は、単位を通常k、gb、mの形式で指定でき、単位では大文字と小文字が区別されないことに注意してください。
2、含む
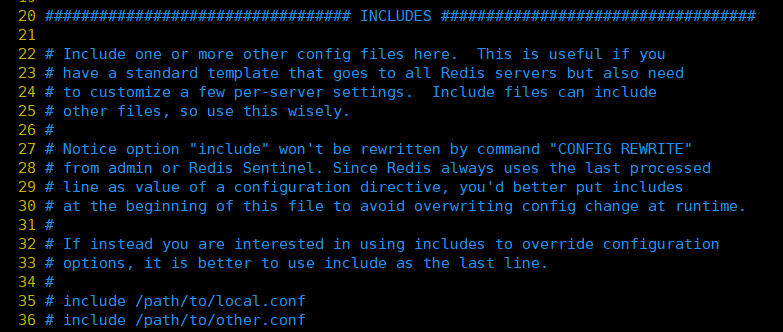
Redisには構成ファイルが1つしかないことがわかっています。複数の人が開発および保守している場合は、そのような構成ファイルが複数必要です。現時点では、/ path / to / local.confを使用して複数の構成ファイルをここで構成できます。 redis.conf設定ファイルはマスターゲートとして機能します。
ps:struts2開発を使用した場合、プロジェクトチームでの複数人による開発の場合、通常は複数のstruts2.xmlファイルがあり、これらもクラス構成を通じて導入されます。
また、注意が必要な場合、この構成をredis.confファイルの先頭に書き込むと、後続の構成によってインポートされたファイルの構成が上書きされます。インポートされたファイルの構成に焦点を当てる場合は、include構成をredis.confに書き込む必要がありますファイルの終わり。
3、モジュール

redis3.0の爆発的な機能はクラスターの追加であり、redis4.0は3.0に基づいて多くの新しい機能を追加します。ここでのカスタムモジュール構成はそのうちの1つです。ここでのロードモジュール構成を通じて、いくつかの機能を追加するためのカスタムモジュールが導入されます。
4、ネットワーク
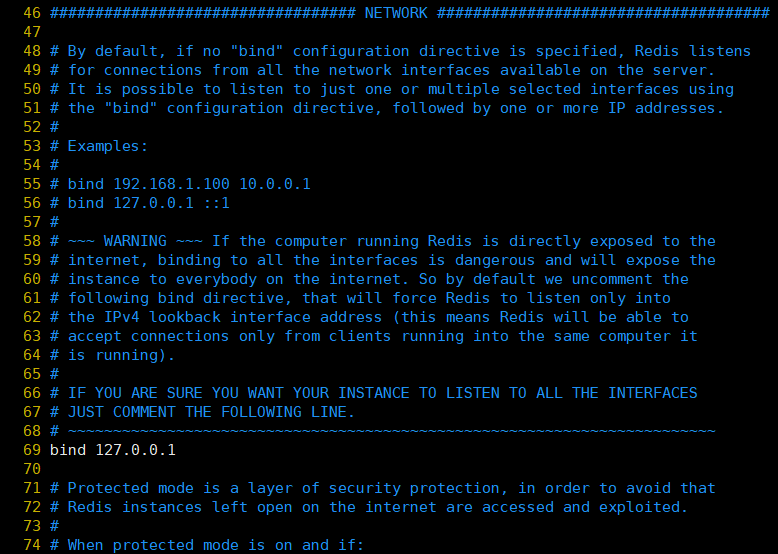
ps:ここでの構成は長く、一部のみをインターセプトしました。以下も同じです。
①、バインド:redisサーバーのネットワークカードIPをバインドします。デフォルトは127.0.0.1で、これはローカルループバックアドレスです。この場合、redisサービスへのアクセスは、ローカルクライアント接続を介してのみ可能であり、リモート接続を介することはできません。bindオプションが空の場合、使用可能なネットワークインターフェイスからのすべての接続を受け入れます。
②、ポート:redisが実行されるポートを指定します。デフォルトは6379です。Redisはシングルスレッドモデルであるため、単一のマシンで複数のRedisプロセスが開かれると、ポートが変更されます。
③、タイムアウト:クライアント接続時のタイムアウト時間を秒単位で設定します。クライアントがこの期間内に指示を出さない場合、接続は閉じられます。デフォルト値は0で、閉じていないことを意味します。
④、tcp-keepalive:単位は秒です。つまり、SO_KEEPALIVEを定期的に使用して、サーバーがブロックされないようにクライアントがまだ健全な状態にあるかどうかを検出します。公式の推奨値は300秒です。0に設定すると、定期的には行われません検出。
5、一般
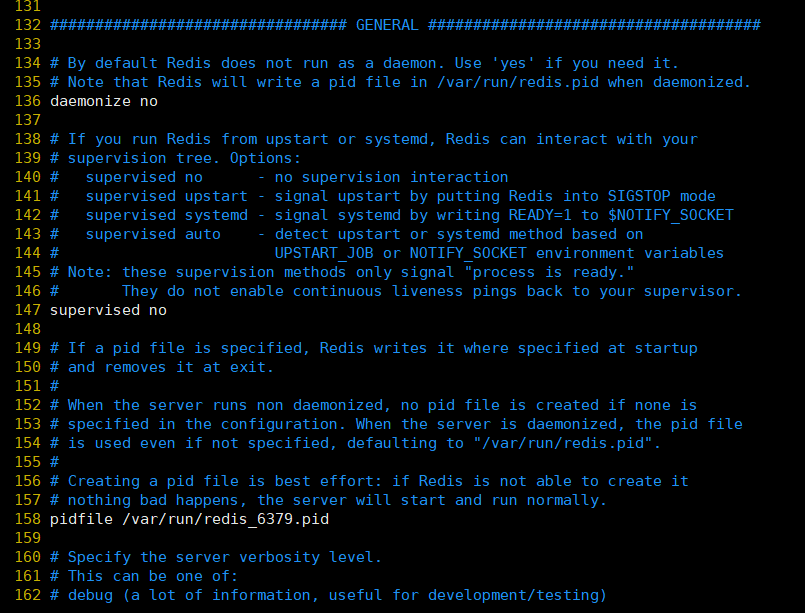
詳細な構成の詳細:
①、daemonize:yesに設定して、Redisがデーモンとして開始されることを指定します(バックグラウンドスタート)。デフォルト値はnoです。
②、pidfile:PIDファイルパスを設定します。redisがデーモンとして実行されている場合、デフォルトでpidを/var/redis/run/redis_6379.pidファイルに書き込みます。
③、ログレベル:ログレベルを定義します。デフォルト値はnoticeで、次の4つの値があります。
デバッグ(大量のログ情報を記録し、開発およびテスト段階に適しています)
詳細(詳細なログ情報)
通知(本番環境で使用される適切なログ情報)
警告(一部の重要で重要な情報のみが記録されます)
④、ログファイル:デフォルトでコマンドラインターミナルウィンドウに表示されるログファイルアドレスを設定します
⑤データベース:データベースの数を設定します。デフォルトのデータベースはDB 0です。select<dbid>コマンドを使用して、接続ごとに異なるデータベースを選択できます。dbidは0からdatabases-1までの値です。デフォルト値は16です。これは、Redisにデフォルトで16のデータベースがあることを意味します。
6、スナップショット
ここでの設定は主に永続化操作に使用されます。
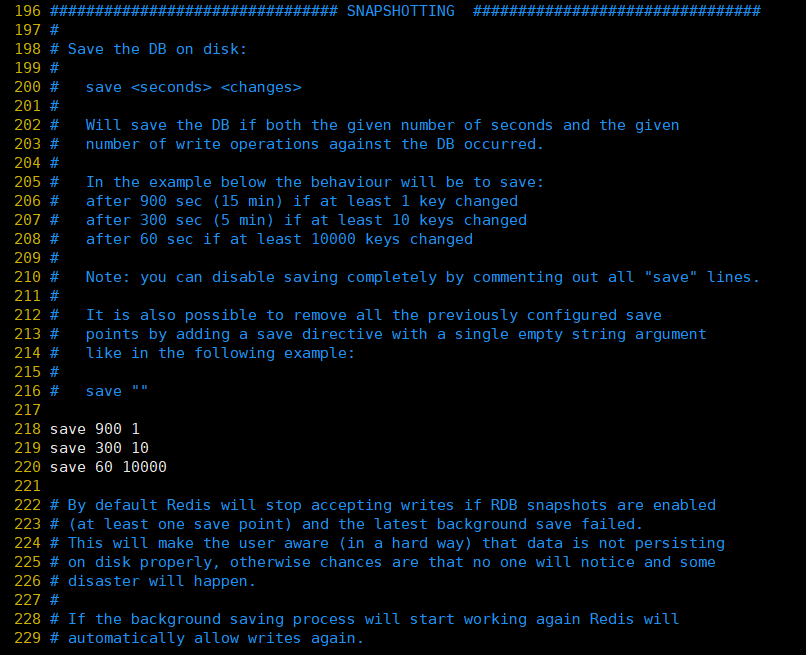
①、保存:これは、Redisをトリガーする永続化条件、つまりメモリ内のデータをハードディスクに保存するタイミングを構成するためのものです。デフォルトの構成は次のとおりです。
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存
save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存
save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存もちろん、Redisのキャッシュ機能のみを使用し、永続化が必要ない場合は、すべての保存行をコメント化して、保存機能を無効にすることができます。空の文字列で直接無効にできます: ""を保存します
②、stop-writes-on-bgsave-error:デフォルト値はyesです。RDBが有効で、バックグラウンドでデータを最後に保存したときに、Redisがデータの受信を停止するかどうか。これにより、ユーザーはデータがディスクに適切に永続化されないことに気付くでしょう。そうでなければ、災害が発生したことに誰も気付かないでしょう。Redisが再起動したら、データの受信を再開できます
③、rdbcompression;デフォルト値はyesです。ディスクに保存されているスナップショットについては、ストレージを圧縮するかどうかを設定できます。その場合、redisはLZFアルゴリズムを使用して圧縮します。圧縮のためにCPUを消費したくない場合は、この機能をオフに設定できますが、ディスクに保存されるスナップショットは大きくなります。
④、rdbchecksum:デフォルト値はyesです。スナップショットを保存した後、データ検証にCRC64アルゴリズムをredisに使用させることもできますが、これによりパフォーマンスの消費量が約10%増加します。最大のパフォーマンス向上を得たい場合は、この機能をオフにできます。
db、dbfilename:スナップショットのファイル名を設定します。デフォルトはdump.rdbです。
⑥。dir:スナップショットファイルのストレージパスを設定します。この構成項目は、ファイル名ではなくディレクトリである必要があります。上記のdbfilenameを保存ファイル名として使用します。
7、複製

①、slave-serve-stale-data:デフォルト値はyesです。スレーブがマスターとの接続を失うか、レプリケーションが進行中の場合、スレーブには2つの動作があります。
1)「はい」の場合、スレーブは引き続きクライアント要求に応答しますが、返されたデータが古いか、または最初の同期中にデータが空である可能性があります
2)いいえの場合、情報を除いて他のコマンドを実行すると、スレーブは「SYNC with master in progress」エラーを返します。
②スレーブ読み取り専用:Redisのスレーブインスタンスが書き込み操作を受け入れるかどうか、つまりスレーブが読み取り専用のRedisかどうかを構成します。デフォルト値はyesです。
③、repl-diskless-sync:マスター/スレーブデータレプリケーションがディスクレスレプリケーション機能を使用するかどうか。デフォルト値はnoです。
④、repl-diskless-sync-delay:ハードディスクのバックアップが有効になっていない場合、サーバーはRDBファイルをソケット経由でスレーブステーションに送信する前に一定時間待機します。この待機時間は設定可能です。送信が開始されると、新しく到着したスレーブにサービスを提供することができないため、これは重要です。スレーブは次のRDB送信のためにキューに入れられます。したがって、サーバーはさらにスレーブが到着するまでしばらく待機します。遅延時間は秒単位で、デフォルトは5秒です。この機能をオフにするには、これを0秒に設定するだけで、送信がすぐに開始されます。デフォルト値は5です。
⑤repl-disable-tcp-nodelay:同期後にスレーブステーションでTCP_NODELAYを無効にするかどうか[はい]を選択すると、redisは少量のTCPパケットと帯域幅を使用してスレーブステーションにデータを送信します。しかし、これはスレーブステーションで少しのデータ遅延を引き起こします。Linuxカーネルのデフォルト設定では、最大40ミリ秒の遅延があります。「いいえ」を選択すると、スレーブのデータ遅延はそれほど大きくありませんが、バックアップに必要な帯域幅は比較的大きくなります。デフォルトでは、潜在的な要因を最適化しますが、高負荷状態またはマスターステーションとスレーブステーションの両方がジャンプしている場合は、yesに切り替えることをお勧めします。デフォルト値はnoです。
8、セキュリティ

①、rename-command:コマンドrename、次のようないくつかの危険なコマンドの場合:
flushdb(データベースをクリア)
flushall(すべてのレコードをクリア)
config(クライアントが接続された後でサーバーを構成できます)
キー(クライアントの接続後、既存のすべてのキーを表示できます)
サーバーredis-serverとして、サーバーをより安全にするために上記のコマンドを無効にする必要があることがよくあります。
- 名前変更コマンドFLUSHALL ""
コマンドを保持することもできますが、使いやすくはありません。このコマンドの名前を変更するだけです。
- 名前変更コマンドFLUSHALL abcdefg
この方法では、サーバーを再起動した後、新しいコマンドを使用して操作を実行する必要があります。そうしないと、サーバーが不明なコマンドエラーを報告します。
②、requirepass:redis接続パスワードを設定します
例:requirepass 123は、redis接続パスワードが123であることを意味します。
9、クライアント

①、maxclients:同時クライアント接続の最大数を設定しますデフォルトは無制限ですRedisが同時に開くことができるクライアント接続の数は、Redisプロセスが開くことができる最大のファイルです。maxclientsを0に設定した場合、記述子の数-32(redisサーバー自体がいくつかを使用します)。制限がないことを示します。クライアント接続の数が制限に達すると、Redisは新しい接続を閉じ、最大数のクライアントに達したというエラーメッセージをクライアントに返します。
10、メモリ管理

①、maxmemory:0に設定されている場合、Redisの最大メモリを設定します。制限がないことを示します。これは通常、以下で説明するmaxmemory-policyパラメーターと組み合わせて使用されます。
②、maxmemory-policy:メモリ使用量がmaxmemoryで設定された最大値に達すると、redisが使用するメモリクリア戦略。いくつかのオプションがあります:
1)Volatile-lruはLRUアルゴリズムを使用して、有効期限付きのキーを削除します(LRU:Least Recently Used)
2)allkeys-lruはLRUアルゴリズムを使用してキーを削除します
3)volatile-randomは、有効期限が設定されたランダムなキーを削除します
4)allkeys-randomはランダムkeを削除します
5)volatile-ttlは、有効期限が近づいているキーを削除します(マイナーTTL)
6)noeviction noevictionはキーを削除しませんが、デフォルトのオプションである書き込みエラーを返します
③、maxmemory-samples:LRUアルゴリズムと最小TTLアルゴリズムは正確なアルゴリズムではなく、比較的正確なアルゴリズムです(メモリを節約するため)。テストのサンプルサイズは自由に選択できます。Redisはデフォルトで3つのサンプルをテスト用に選択します。サンプルの数はmaxmemory-samplesで設定できます。
11、追加のみモード

①Appendonly:デフォルトのredisはRDB永続性を使用します。これは多くのアプリケーションで十分です。ただし、redisが途中でクラッシュすると、数分間データが失われる可能性があります。永続性の保存戦略によると、Append Only Fileは、より優れた永続性を提供できるもう1つの永続化方法です。Redisは毎回書き込まれたデータを受信後、appendonly.aofファイルに書き込みます。Redisは最初にこのファイルのデータをメモリに読み込みます。最初にRDBファイルを無視します。デフォルト値はnoです。
②、appendfilename:Aofファイル名、デフォルトは「appendonly.aof」
③、appendfsync:aof永続化戦略の構成。noはfsyncが実行されないことを意味し、オペレーティングシステムはデータがディスクに同期されることを保証します。これは最速です。常に、データがディスクに同期されるように、すべての書き込みに対してfsyncが実行されることを意味します。everysecはすべて毎秒1回fsyncを実行すると、この1秒のデータが失われる可能性があります
④、no-appendfsync-on-rewrite:AOFがRDBファイルを再書き込みまたは書き込むと、大量のIOが実行されます。このとき、EverysecおよびAlwaysのAOFモードの場合、fsyncを実行すると、ブロッキングが長時間発生します。 appendfsync-on-rewriteフィールドは、デフォルトでnoに設定されています。レイテンシ要件が高いアプリケーションの場合、このフィールドはyesに設定できます。それ以外の場合は、noに設定されます。これは、永続化機能にとってより安全な選択です。yesに設定すると、新しい書き込み操作は書き換え中にfsyncされず、一時的にメモリに保存され、書き換えが完了した後に書き込まれます。デフォルトはnoです。yesをお勧めします。Linuxのデフォルトのfsyncポリシーは30秒です。30秒のデータが失われる可能性があります。デフォルト値はnoです。
⑤auto-aof-rewrite-percentage:デフォルト値は100です。Aofは構成を自動的に再書き込みします。現在のAOFファイルのサイズが最後に再書き込みされたAOFファイルのサイズを超えると、再書き込みされます。つまり、AOFファイルが特定のサイズになると、Redisはbgrewriteaofを呼び出してログファイルを再書き込みできます。 。現在のAOFファイルのサイズが、最後のログの書き換えから取得したAOFファイルのサイズの2倍になると(100に設定)、新しいログの書き換えプロセスが自動的に開始されます。
⑥、auto-aof-rewrite-min-size:64MB。合意されたパーセンテージに達してもサイズがまだ小さい場合に、再書き込みを回避するためにファイルの最小aofファイルサイズを設定します。
a、aof-load-truncated:aofファイルが最後に不完全である可能性があるredisが開始されると、aofファイルのデータがメモリにロードされます。特にdata = orderedオプションがext4ファイルシステムに追加されていない場合、redisがダウンしているホストオペレーティングシステムの後に再起動が発生する可能性があります。この現象は、redisがダウンするか、異常終了によってテールが不完全にならない場合に発生し、redisを終了させることができます。 、またはできるだけ多くのデータをインポートします。[はい]を選択した場合、切り捨てられたaofファイルがインポートされると、ログが自動的にクライアントに送信されてロードされます。いいえの場合、ユーザーは手動でredis-check-aofを実行してAOFファイルを修復する必要があります。デフォルト値はyesです。
12、LUAスクリプティング
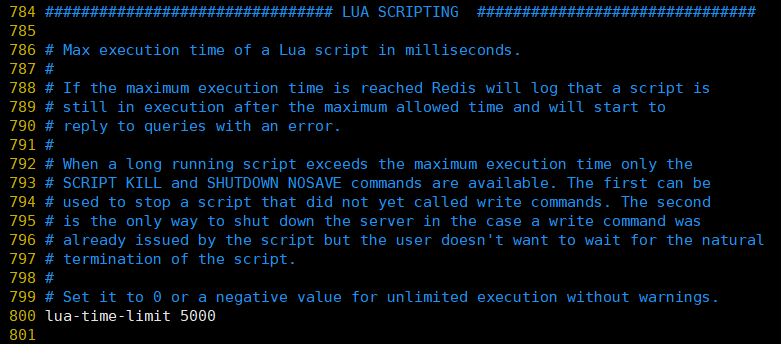
①、lua-time-limit:luaスクリプトを実行する最大時間(ミリ秒)。デフォルト値は5000です。
13、REDISクラスター

①、クラスター対応:クラスタースイッチ、デフォルトではクラスターモードを開きません。
②、cluster-config-file:クラスター構成ファイルの名前。各ノードには、クラスター情報を保持するクラスター関連の構成ファイルがあります。このファイルは手動で構成する必要はありません。この構成ファイルはRedisによって生成および更新されます。各Redisクラスターノードには個別の構成ファイルが必要です。インスタンスが実行されているシステムの構成ファイル名と競合しないことを確認してください。デフォルトの構成は、nodes-6379.confです。
③、cluster-node-timeout:設定可能な値は15000です。ノード相互接続タイムアウトしきい値、クラスターノードタイムアウトミリ秒
④、cluster-slave-validity-factor:値は10に設定できます。フェイルオーバー中は、すべてのスレーブがマスターになることを要求しますが、一部のスレーブが一定期間マスターから切断され、データが古くなりすぎることがあります。そのようなスレーブをマスターに昇格しないでください。このパラメーターは、スレーブノードとマスター間の切断時間が長すぎるかどうかを判断するために使用されます。判断方法は次のとおりです。スレーブ切断の時間を(node-timeout * slave-validity-factor)+ repl-ping-slave-periodと比較します。ノードのタイムアウト時間が30秒で、slave-validity-factorが10の場合、デフォルトのrepl-ping-slave-periodは10秒です。つまり、310秒を超えると、スレーブはフェイルオーバーを試みません。
⑤、cluster-migration-barrier:構成可能な値は1です。マスターのスレーブの数がこの値より大きい場合、スレーブは他の分離されたマスターに移行できます。このパラメーターを2に設定すると、マスターノードに2つの動作中のスレーブノードがある場合にのみ、そのスレーブノードの1つが移行を試みます。
⑥cluster-require-full-coverage:デフォルトでは、クラスター内のすべてのスロットがノードを担当し、サービスを提供するためにクラスターのステータスはOKです。スロットがすべて割り当てられていない場合にサービスを提供するには、noに設定します。この構成を開くことはお勧めしません。これにより、小さいパーティションのマスターがパーティション中に書き込み要求を常に受け入れるようになり、長期間にわたってデータの不整合が発生します。