KafkaコネクタはKafkaの一部であり、Kafkaと他のテクノロジー間のストリーミングパイプラインを構築するための強力なフレームワークです。複数の場所(データベース、メッセージキュー、テキストファイルを含む)からKafkaにデータをストリーミングし、Kafkaからターゲットエンド(ドキュメントストレージ、NoSQL、データベース、オブジェクトストレージなど)にデータをストリーミングするために使用できます。 。
現実の世界は完璧ではなく、エラーは避けられないため、Kafkaのパイプラインがエラーが発生したときにできる限り適切に処理できることが最善です。一般的なシナリオは、特定のシリアル化形式に一致しないトピックのメッセージを取得することです(たとえば、Avroであることが予想される場合、実際にはJSONであり、その逆も同様です)。Kafka 2.0のリリース以降、Kafkaコネクタにはエラー処理オプション、つまり、メッセージを配信不能キューにルーティングする機能が含まれています。これは、データパイプラインを構築するための一般的な手法です。
この記事では、問題を処理するいくつかの一般的なモードを紹介し、それらを実装する方法を説明します。
障害発生直後に停止
エラーが発生したときにすぐに処理を停止したい場合があります。品質の低いデータは上流の理由が原因であり、上流で解決する必要がある場合があります。他のメッセージの処理を続けても意味がありません。
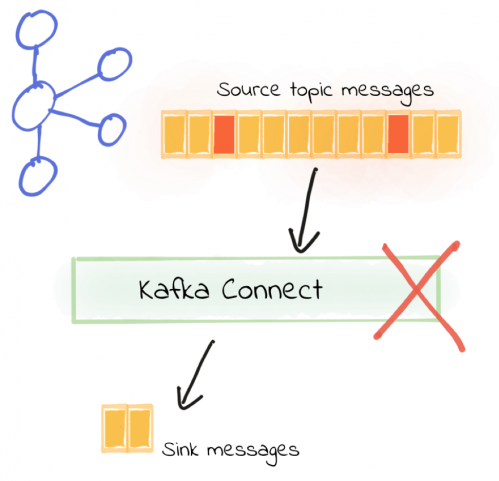
これはKafkaコネクタのデフォルトの動作であり、次の構成項目を使用して明示的に指定することもできます。
errors.tolerance = none
この例では、コネクターはテーマからJSON形式のデータを読み取り、プレーンテキストファイルに書き込むように構成されています。FileStreamSinkConnectorコネクタはデモンストレーションの目的で使用されることに注意してください。本番環境での使用はお勧めしません。
curl -X POST http:// localhost:8083 / connectors -H "Content-Type:application / json" -d '{
"name": "file_sink_01"、 "config":{"connector.class": "org。 apache.kafka.connect.file.FileStreamSinkConnector "、" topics ":" test_topic_json "、" value.converter ":" org.apache.kafka.connect.json.JsonConverter "、" value.converter.schemas.enable ":false 、 "key.converter": "org.apache.kafka.connect.json.JsonConverter"、 "key.converter.schemas.enable":false、 "file": "/ data / file_sink_01.txt"}} '
件名の一部のJSON形式のメッセージは無効です。コネクタはすぐに終了し、次のFAILED状態になります。
$ curl -s "http:// localhost:8083 / connectors / file_sink_01 / status" | \ jq -c -M '[.name、.tasks []。state]' ["file_sink_01"、 "FAILED"]
Kafkaコネクタのワーカーノードのログを確認すると、エラーが記録され、タスクが終了していることがわかります。
org.apache.kafka.connect.errors.ConnectException:
org.apache.kafka.connect.runtime.errors.RetryWithToleranceOperator.execAndHandleError(RetryWithToleranceOperator.java:178)のエラーハンドラーで許容値を超えました…原因:org.apache.kafka。 connect.errors.DataException:byte []からKafka Connectデータへの変換は、シリアル化エラーのために失敗しました:org.apache.kafka.connect.json.JsonConverter.toConnectData(JsonConverter.java:334)で…原因:org.apache.kafka .common.errors.SerializationException:com.fasterxml.jackson.core.JsonParseException:予期しない文字( 'b'(コード98)):[ソース:(byte [])]でフィールド名を開始するには二重引用符が必要でした "{brokenjson -: "バー1"} "; 行:1、列:3]
パイプラインを修正するには、ソーストピックのメッセージの問題を解決する必要があります。事前に指定されていない限り、Kafkaコネクタは無効なメッセージを単に「スキップ」することはありません。構成エラーの場合(たとえば、間違ったシリアル化コンバーターが指定されている場合)は、最善の方法です。修正後、コネクターを再始動してください。ただし、それが実際に件名に対して無効なメッセージである場合は、方法を見つける必要があります。つまり、他のすべての有効なメッセージの処理を妨げないようにする必要があります。
無効なメッセージを黙って無視する
処理を続行したいだけの場合:
errors.tolerance = all
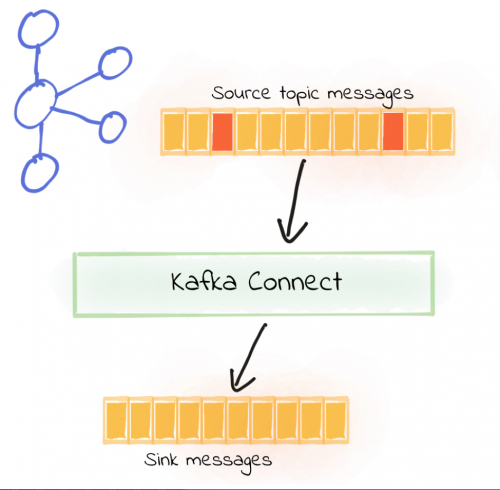
実際には、おおよそ次のようになります。
curl -X POST http:// localhost:8083 / connectors -H "Content-Type:application / json" -d '{
"name": "file_sink_05"、 "config":{"connector.class": "org。 apache.kafka.connect.file.FileStreamSinkConnector "、" topics ":" test_topic_json "、" value.converter ":" org.apache.kafka.connect.json.JsonConverter "、" value.converter.schemas.enable ":false 、 "key.converter": "org.apache.kafka.connect.json.JsonConverter"、 "key.converter.schemas.enable":false、 "file": "/ data / file_sink_05.txt"、 "errors.tolerance ": "すべて" } }'
コネクターを起動した後(有効なメッセージと無効なメッセージの両方を含む元のソーストピック)、実行を続行できます。
$ curl -s "http:// localhost:8083 / connectors / file_sink_05 / status" | \ jq -c -M '[.name、.tasks []。state]' ["file_sink_05"、 "RUNNING"]
この時点で、コネクターによって読み取られたソーストピックに無効なメッセージがあったとしても、Kafkaコネクターワーカーノードの出力にエラーは書き込まれず、期待どおりに有効なメッセージが出力ファイルに書き込まれます。
$ head data / file_sink_05.txt
{foo = bar 1} {foo = bar 2} {foo = bar 3}…
データの損失を感知することは可能ですか?
errors.tolerance = allを構成した後、Kafkaコネクターは無効なメッセージを無視し、デフォルトでは破棄されたメッセージをログに記録しません。errors.tolerance = allの構成を確認する場合は、実際のメッセージの損失を確認する方法と方法を慎重に検討する必要があります。実際には、これは、使用可能なインジケーターに基づく監視/アラーム、および/または障害メッセージのロギングを意味します。
メッセージが破棄されているかどうかを判別する最も簡単な方法は、ソーストピックのメッセージ数を宛先に書き込まれた数と比較することです。
$ kafkacat -b localhost:9092 -t test_topic_json -o begining -C -e -q -X enable.partition.eof = true | wc -l 150 $ wc -l data / file_sink_05.txt 100 data / file_sink_05.txt
このアプローチはあまり洗練されていませんが、メッセージが失われていることがわかります。また、ログにはレコードがないため、ユーザーはメッセージについて何も知りません。
より信頼性の高い方法は、JMXインジケーターを使用して、エラーメッセージ率を積極的に監視および警告することです。
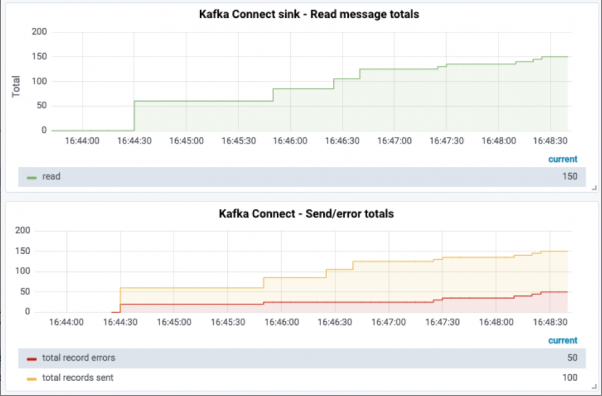
現時点では、エラーが発生したことがわかりますが、メッセージにエラーがあることはわかりませんが、これはユーザーが望んでいることです。実際、これらの破棄されたメッセージが/ dev / nullに書き込まれたとしても、それを実際に知ることができ、まさにデッドレターキューの概念が現れるポイントです。
メッセージを配信不能キューにルーティングする
Kafkaコネクタは、処理できないメッセージ(上記の逆シリアル化エラーなど)を別のKafkaトピックである配信不能キューに送信するように構成できます。有効なメッセージは正常に処理され、パイプラインは引き続き実行されます。その後、デッドレターキューからの無効なメッセージをチェックし、必要に応じて無視または修正して再処理できます。
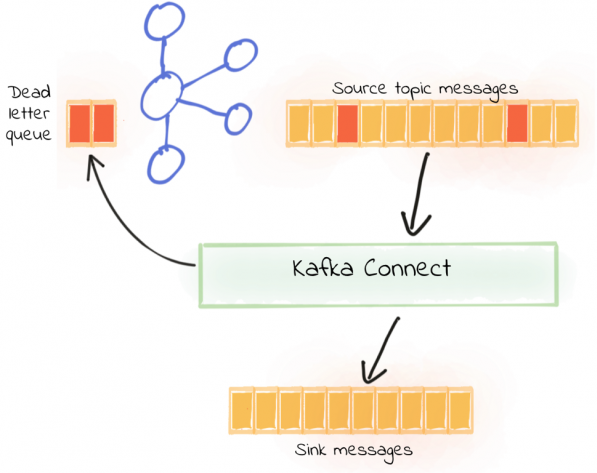
配信不能キューは、次の構成で有効にできます。
errors.tolerance =すべて errors.deadletterqueue.topic.name =
単一ノードのKafkaクラスターで実行している場合は、errors.deadletterqueue.topic.replication.factor = 1も構成する必要があります。デフォルト値は3です。
この構成のコネクタ構成の例は、おおよそ次のとおりです。
curl -X POST http:// localhost:8083 / connectors -H "Content-Type:application / json" -d '{
"name": "file_sink_02"、 "config":{"connector.class": "org。 apache.kafka.connect.file.FileStreamSinkConnector "、" topics ":" test_topic_json "、" value.converter ":" org.apache.kafka.connect.json.JsonConverter "、" value.converter.schemas.enable ":false 、 "key.converter": "org.apache.kafka.connect.json.JsonConverter"、 "key.converter.schemas.enable":false、 "file": "/data/file_sink_02.txt"、"errors.tolerance ":" all "、" errors.deadletterqueue.topic.name ":" dlq_file_sink_02 "、" errors.deadletterqueue.topic.replication.factor ":1}} '
以前と同じソーステーマを使用し、有効なJSONと無効なJSONの混合データを処理すると、新しいコネクタが安定して実行できることがわかります。
$ curl -s "http:// localhost:8083 / connectors / file_sink_02 / status" | \ jq -c -M '[.name、.tasks []。state]' ["file_sink_02"、 "RUNNING"]
ソースサブジェクトの有効なレコードがターゲットファイルに書き込まれます。
$ head data / file_sink_02.txt
{foo = bar 1} {foo = bar 2} {foo = bar 3} […]
このようにして、パイプラインは引き続き正常に実行でき、インジケーターデータから確認できるデッドレターキュートピックにまだデータがあります。
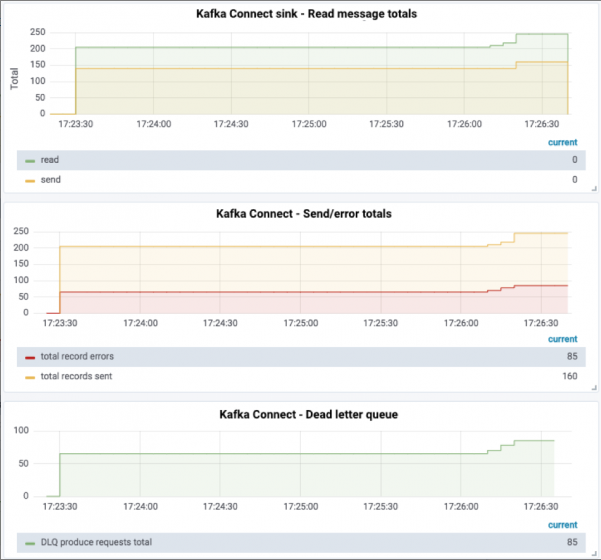
主題自体を調べることも見ることができます:
ksql>リストトピック;
Kafkaトピック| 登録済み| パーティション| パーティションのレプリカ| 消費者| 消費者グループ---------------------------------------------------------------- -------------------------------------------------- dlq_file_sink_02 | 誤り| 1 | 1 | 0 | 0 test_topic_json | 誤り| 1 | 1 | 1 | 1 ------------------------------------------------- -------------------------------------------------- ksql> PRINT 'dlq_file_sink_02' FROM BEGINNING; Format:STRING1 / 24/19 5:16:03 PM UTC、NULL、{foo: "bar 1"} 1/24/19 5:16:03 PM UTC、NULL、{ foo: "bar 2"} 1/24/19 5:16:03 PM UTC、NULL、{foo: "bar 3"}…
出力から、メッセージのタイムスタンプは(1/24/19 5:16:03 PM UTC)、キーは(NULL)、そして値であることがわかります。この時点では、値が無効なJSON形式{foo: "bar 1"}(fooも引用符で囲む必要があります)であることがわかります。そのため、JsonConverterは処理時に例外をスローし、最終的にデッドレタートピックに出力されます。
しかし、メッセージを見るだけで、それが無効なJSONであることがわかります。それでも、メッセージが拒否された理由のみを推測できます。Kafkaコネクタがメッセージを無効として処理する実際の理由を判断するには、2つの方法があります。
- 配信不能キューのメッセージヘッダー。
- Kafkaコネクタのワーカーノードのログ。
以下で個別に紹介します。
メッセージの記録に失敗した理由:メッセージヘッダー
メッセージヘッダーは、Kafkaのバージョン0.11で導入されたKafkaメッセージのキー、値、およびタイムスタンプを使用して保存される追加のメタデータです。Kafkaコネクタは、メッセージ拒否の理由に関する情報をメッセージ自体のメッセージヘッダーに書き込むことができます。このアプローチは原因をメッセージに直接リンクするため、ログファイルに書き込むよりも優れています。
以下のパラメーターを構成して、送達不能キューのメッセージ・ヘッダーに拒否の理由を含めます。
errors.deadletterqueue.context.headers.enable = true
設定例は、おおよそ次のとおりです。
curl -X POST http:// localhost:8083 / connectors -H "Content-Type:application / json" -d '{
"name": "file_sink_03"、 "config":{"connector.class": "org。 apache.kafka.connect.file.FileStreamSinkConnector "、" topics ":" test_topic_json "、" value.converter ":" org.apache.kafka.connect.json.JsonConverter "、" value.converter.schemas.enable ":false 、 "key.converter": "org.apache.kafka.connect.json.JsonConverter"、 "key.converter.schemas.enable":false、 "file": "/data/file_sink_03.txt"、"errors.tolerance ":" all "、" errors.deadletterqueue.topic.name ":" dlq_file_sink_03 "、" errors.deadletterqueue.topic.replication.factor ":1、"エラー。deadletterqueue.context.headers.enable ":true}} '
以前と同様に、コネクターは正常に動作します(errors.tolerance = allが構成されているため)。
$ curl -s "http:// localhost:8083 / connectors / file_sink_03 / status" | \ jq -c -M '[.name、.tasks []。state]' ["file_sink_03"、 "RUNNING"]
ソースの件名の有効なメッセージは、通常ターゲットファイルに書き込まれます。
$ head data / file_sink_03.txt
{foo = bar 1} {foo = bar 2} {foo = bar 3} […]
任意のコンシューマツールを使用してデッドレターキューのメッセージをチェックできます(以前はKSQLが使用されていました)が、ここではkafkacatが使用され、その理由がすぐにわかります。最も簡単な操作は、おおよそ次のとおりです。
kafkacat -b localhost:9092 -t dlq_file_sink_03
%自動選択コンシューマモード(オーバーライドするには-Pまたは-Cを使用){foo: "bar 1"} {foo: "bar 2"}…
しかし、kafkacatにはより強力な機能があり、メッセージ自体よりも多くの情報を表示できます。
kafkacat -b localhost:9092 -t dlq_file_sink_03 -C -o-1 -c1 \ -f '\ nキー(%Kバイト):%k値(%Sバイト):%sタイムスタンプ:%Tパーティション:%pオフセット: %oヘッダー:%h \ n '
このコマンドは、最後のメッセージ(-o-1、オフセットに最後のメッセージを使用)を取得し、1つのメッセージ(-c1)のみを読み取り、-fパラメーターでフォーマットして、理解を容易にします。
キー(-1バイト):
値(13バイト):{foo: "bar 5"}タイムスタンプ:1548350164096パーティション:0オフセット:34ヘッダー:__connect.errors.topic = test_topic_json、__ connect.errors.partition = 0、__ connect。 errors.offset = 94、__ connect.errors.connector.name = file_sink_03、__ connect.errors.task.id = 0、__ connect.errors.stage = VALUE_CONVERTER、__ connect.errors.class.name = org.apache.kafka.connect。 json.JsonConverter、__ connect.errors.exception.class.name = org.apache.kafka.connect.errors.DataException、__ connect.errors.exception.message =シリアル化エラーのためにバイト[]をKafka接続データに変換できませんでした:、__ connect .errors.exception.stacktrace = org.apache.kafka.connect.errors.DataException:シリアル化エラーのため、byte []からKafka Connectデータへの変換に失敗しました:[…]
また、メッセージヘッダーのみを表示し、いくつかの簡単な手法を使用して分割することで、問題に関する詳細情報をより明確に確認することもできます。
$ kafkacat -b localhost:9092 -t dlq_file_sink_03 -C -o-1 -c1 -f '%h' | tr '、' '\ n' __connect.errors.topic = test_topic_json__connect.errors.partition = 0__connect.errors.offset = 94__connect.errors.connector.name = file_sink_03__connect.errors.task.id = 0__connect.errors.stage = VALUE_CONVERTER__connect.errors.class.name = org.apache.kafka.connect.json.JsonConverter__connect.errors.exception.class.name = org.apache.kafka.connect.errors.DataException__connect.errors.exception.message =シリアル化エラーのため、バイト[]からKafka Connectデータへの変換に失敗しました:
Kafkaコネクタによって処理される各メッセージは、ソーストピックとトピック内の特定のポイント(オフセット)から送信され、メッセージヘッダーはこれを正確に述べています。したがって、これを使用して元のトピックに戻り、必要に応じて元のメッセージを確認できます。デッドレターキューにはすでにメッセージのコピーがあるため、この確認は保険業務に似ています。
上記のメッセージヘッダーから取得した詳細情報に基づいて、ソースメッセージを再度確認できます。
__connect.errors.topic = test_topic_json __connect.errors.offset = 94
これらの値をそれぞれ-tおよび-oパラメーターに挿入して、kafkacatのトピックとオフセットをそれぞれ表すと、次のようになります。
$ kafkacat -b localhost:9092 -C \
-t test_topic_json -o94 \ -f '\ nキー(%Kバイト):%k値(%Sバイト):%sタイムスタンプ:%Tパーティション:%pオフセット:%oトピック:%t \ n'Key(-1バイト):値(13バイト):{foo: "bar 5"}タイムスタンプ:1548350164096パーティション:0オフセット:94トピック:test_topic_json
デッドレターキュー内の上記のメッセージと比較すると、タイムスタンプを含めても、メッセージはまったく同じであることがわかります。唯一の違いは、件名、オフセット、およびメッセージヘッダーです。
メッセージのログ記録に失敗した理由:ログ
メッセージの拒否理由をログに記録するための2番目のオプションは、メッセージをログに書き込むことです。インストール方法に応じて、Kafkaコネクタは標準出力またはログファイルに書き込みます。どちらの方法でも、失敗したメッセージごとに一連の詳細な出力が生成されます。この機能を有効にするには、次の構成を実行します。
errors.log.enable = true
errors.log.include.messages = trueを構成することにより、メッセージ自体に関するメタデータを出力に含めることもできます。このメタデータには、ソースメッセージの件名やオフセットなど、上記のメッセージヘッダーと同じ項目がいくつか含まれています。メッセージのキーや値自体は含まれていないことに注意してください。
この時点でのコネクター構成は次のとおりです。
curl -X POST http:// localhost:8083 / connectors -H "Content-Type:application / json" -d '{
"name": "file_sink_04"、 "config":{"connector.class": "org。 apache.kafka.connect.file.FileStreamSinkConnector "、" topics ":" test_topic_json "、" value.converter ":" org.apache.kafka.connect.json.JsonConverter "、" value.converter.schemas.enable ":false 、 "key.converter": "org.apache.kafka.connect.json.JsonConverter"、 "key.converter.schemas.enable":false、 "file": "/data/file_sink_04.txt"、"errors.tolerance ":" all "、" errors.log.enable ":true、" errors.log.include.messages ":true}} '
コネクタは正常に実行できます。
$ curl -s "http:// localhost:8083 / connectors / file_sink_04 / status" | \
jq -c -M '[.name、.tasks []。state]' ["file_sink_04"、 "RUNNING"]ソーストピックの有効なレコードがターゲットファイルに書き込まれます:$ head data / file_sink_04.txt {foo = bar 1} {foo = bar 2} {foo = bar 3} […]
この時点で、Kafkaコネクタのワーカーノードログを確認すると、失敗した各メッセージにエラーレコードがあることがわかります。
エラータスクfile_sink_04-0でエラーが発生しました。クラス 'org.apache.kafka.connect.json.JsonConverter'でステージ 'VALUE_CONVERTER'を実行します。ここで、消費されたレコードは{topic = 'test_topic_json'、partition = 0、offset = 94、timestamp = 1548350164096、timestampType = CreateTime}です。(org.apache.kafka.connect.runtime.errors.LogReporter)
org.apache.kafka.connect.errors.DataException:シリアライゼーションエラーのため、byte []をKafka Connectデータに変換できませんでした:org.apache.kafka.connectで。 json.JsonConverter.toConnectData(JsonConverter.java:334)[…]原因:org.apache.kafka.common.errors.SerializationException:com.fasterxml.jackson.core.JsonParseException:予期しない文字( 'f'(コード102) ):フィールド名が[ソース:(byte []) "{foo:" bar 5 "}"で始まる二重引用符が必要でした; 行:1、列:3]
エラー自体とエラーに関連する情報を確認できます。
{topic = 'test_topic_json'、partition = 0、offset = 94、timestamp = 1548350164096、timestampType = CreateTime}
上記のように、トピックとオフセットをkafkacatなどのツールで使用して、ソーストピックのメッセージを確認できます。スローされた例外によっては、記録されたソースメッセージも表示される場合があります。
原因:org.apache.kafka.common.errors.SerializationException:
…at [ソース:(byte []) "{foo:" bar 5 "}"; 行:1、列:3]
配信不能キューメッセージの処理
デッドレターキューが設定されていますが、それらの「デッドレター」をどのように処理しますか?これは単なるKafkaトピックなので、他のトピックと同様に標準のKafkaツールを使用できます。上記で見たように、たとえば、kafkacatを使用してメッセージヘッダーを確認できます。また、kafkacatは、メッセージの内容とそのメタデータの一般的な確認も実行できます。もちろん、拒否の理由に応じて、メッセージの再生を選択することもできます。
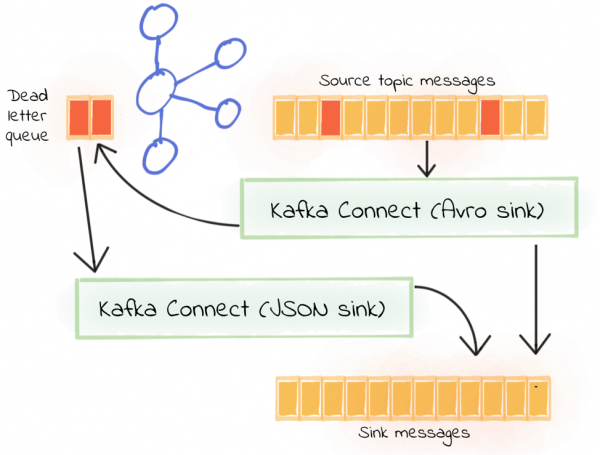
1つのシナリオは、コネクターがAvroコンバーターを使用しているが、件名はJSON形式のメッセージである(したがって、送達不能キューに書き込まれる)ことです。おそらくレガシーな理由が原因で、JSONおよびAvroフォーマットプロデューサーがソーストピックを書き込んでいます。この問題は解決する必要がありますが、現在はパイプラインストリームのデータのみをレシーバーに書き込む必要があります。
まず、ソーストピックを読み取る最初のシンクから始め、Avroを使用して逆シリアル化し、配信不能キューにルーティングします。
curl -X POST http:// localhost:8083 / connectors -H "Content-Type:application / json" -d '{
"name": "file_sink_06__01-avro"、 "config":{"connector.class": " org.apache.kafka.connect.file.FileStreamSinkConnector "、" topics ":" test_topic_avro "、" file ":" / data / file_sink_06.txt "、" key.converter ":" io.confluent.connect.avro.AvroConverter "、" key.converter.schema.registry.url ":" http:// schema-registry:8081 "、" value.converter ":" io.confluent.connect.avro.AvroConverter "、" value.converter.schema .registry.url ":" http:// schema-registry:8081 "、" errors.tolerance ":" all "、" errors.deadletterqueue.topic.name ":" dlq_file_sink_06__01 "、"errors.deadletterqueue.topic.replication.factor":1、 "errors.deadletterqueue.context.headers.enable":true、 "errors.retry.delay.max.ms":60000、 "errors.retry.timeout": 300000}} '
さらに、2番目のレシーバーを作成し、最初のレシーバーのデッドレターキューをソーストピックとして使用して、レコードをJSONに逆シリアル化してみます。ここでは、value.converter、key.converter、ソーストピック名、および配信不能キューの名前(このコネクタが配信不能キューにメッセージをルーティングする必要がある場合は、再帰を避けてください)。
curl -X POST http:// localhost:8083 / connectors -H "Content-Type:application / json" -d '{
"name": "file_sink_06__02-json"、 "config":{"connector.class": " org.apache.kafka.connect.file.FileStreamSinkConnector "、" topics ":" dlq_file_sink_06__01 "、" file ":" / data / file_sink_06.txt "、" value.converter ":" org.apache.kafka.connect.json .JsonConverter "、" value.converter.schemas.enable ":false、" key.converter ":" org.apache.kafka.connect.json.JsonConverter "、" key.converter.schemas.enable ":false、"エラー.tolerance ":" all "、" errors.deadletterqueue.topic.name ":" dlq_file_sink_06__02 "、" errors.deadletterqueue.topic.replication.factor ":1、"errors.deadletterqueue.context.headers.enable":true、 "errors.retry.delay.max.ms":60000、 "errors.retry.timeout":300000}} '
これで確認できます。
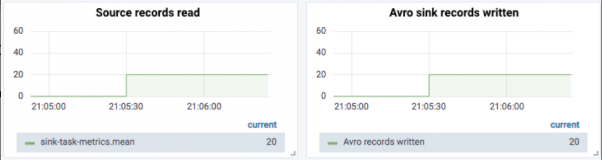
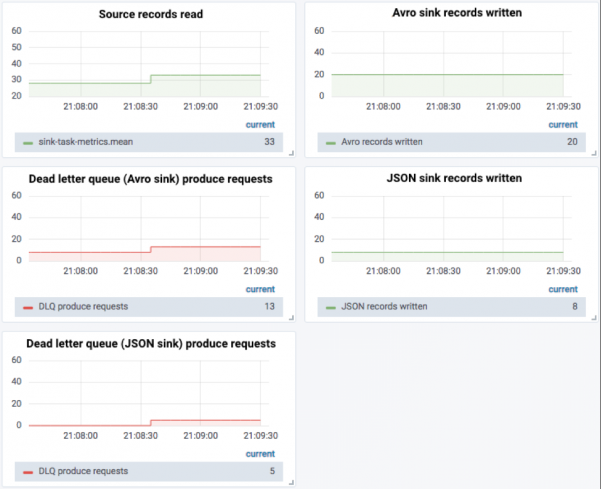
最初に、ソーストピックが20のAvroメッセージを受信すると、20のメッセージが元のAvroレシーバーによって読み取られ、受信されたことがわかります。
次に、8つのJSONメッセージを送信します。現時点では、8つのメッセージが配信不能キューに送信され、JSONレシーバーによって受信されます。
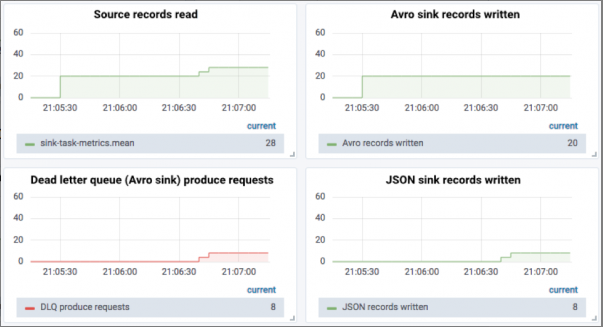
正しくフォーマットされていないJSONメッセージをさらに5つ送信すると、両方に失敗したメッセージがあることがわかります。確認する点が2つあります。
- Avroレシーバーから配信不能キューに送信されるメッセージの数と正常に送信されたJSONメッセージの数には違いがあります。
- メッセージはJSONレシーバーの配信不能キューに送信されます。
KSQLによるデッドレターキューの監視
JMXを使用して配信不能キューを監視するだけでなく、KSQLの集約機能を使用して、メッセージがキューに書き込まれるレートを監視する単純なストリーミングアプリケーションを作成することもできます。
-各デッドレターキュートピックのフローを登録します。 CREATE STREAM dlq_file_sink_06__01(MSG VARCHAR)WITH(KAFKA_TOPIC = 'dlq_file_sink_06__01'、VALUE_FORMAT = 'DELIMITED'); CREATE STREAM dlq_file_sink_06__02(MSG VARCHAR_TOPIC with VALUE'DELIMITEDの先頭から)消費者データSET'auto.offset.reset '=' earliest ';-他の列を使用して監視ストリームを作成し、後続の集計クエリに使用できますCREATE STREAM DLQ_MONITOR WITH(VALUE_FORMAT =' AVRO ')AS \ SELECT'dlq_file_sink_06__01' AS SINK_NAME、\ 'レコード:' AS GROUP_COL、\ MSG \ FROM dlq_file_sink_06__01;-2番目のデッドレターキューからのメッセージを使用して、同じ監視フローを挿入しますINSERT INTO DLQ_MONITOR \ SELECT'dlq_file_sink_06__02 'AS SINK_NAME、\' Records: 'AS GROUP_COL、\ MSG \ FROM dlq_file_sink_06__02;-各デッドレターキューのタイムウィンドウ内に毎分メッセージの集約ビューを作成しますCREATE TABLE DLQ_MESSAGE_COUNT_PER_MIN AS \ SELECT TIMESTAMPTOSTRING(WINDOWSTART()、 'yyyy-MM-dd HH:mm:ss')AS START_TS、\ SINK_NAME、\ GROUP_COL、\ COUNT(*)AS DLQ_MESSAGE_COUNT \ FROM DLQ_MONITOR \ WINDOW TUMBLING(SIZE 1 MINUTE)\ GROUP BY SINK_NAME、\ GROUP_COL;
この集約テーブルはインタラクティブにクエリできます。以下は、1分間の各配信不能キュー内のメッセージ数を示しています。
ksql> SELECT START_TS、SINK_NAME、DLQ_MESSAGE_COUNT FROM DLQ_MESSAGE_COUNT_PER_MIN; 2019-02-01 02:56:00 | dlq_file_sink_06__01 | 92019-02-01 03:10:00 | dlq_file_sink_06__01 | 82019-02-01 03:12:00 | dlq_file_sink_06__01 | 52019-02-01 02:56:00 | dlq_file_sink_06__02 | 52019-02-01 03:12:00 | dlq_file_sink_06__02 | 5
Kafkaトピックはこの表の下にあるため、任意の目的の監視ダッシュボードにルーティングでき、アラームの駆動にも使用できます。いくつかのエラーメッセージが許容可能であると仮定しますが、1分間に5を超えるメッセージは大きな問題であり、注意が必要です。
CREATE TABLE DLQ_BREACH AS \ SELECT START_TS、SINK_NAME、DLQ_MESSAGE_COUNT \ FROM DLQ_MESSAGE_COUNT_PER_MIN \ WHERE DLQ_MESSAGE_COUNT> 5;
これで、アラームサービスがサブスクライブできるDLQ_BREACHトピックがあり、メッセージが受信されると、適切なアクション(通知など)をトリガーできます。
ksql> SELECT START_TS、SINK_NAME、DLQ_MESSAGE_COUNT FROM DLQ_BREACH; 2019-02-01 02:56:00 | dlq_file_sink_06__01 | 92019-02-01 03:10:00 | dlq_file_sink_06__01 | 8
Kafkaコネクタはどこでエラー処理を提供しますか?
Kafkaコネクタのエラー処理方法を次の表に示します。
コネクタのライフサイクルステージの説明はエラーを処理しますか?コネクタを初めて起動すると、データストアへの接続、プルなし(ソースコネクタの場合)、ソースデータストアからのメッセージの読み取り、フォーマットされていない変換、KafkaトピックとJSON / Avro形式からのデータの読み取りと書き込みなど、必要な初期化が実行されますシリアライゼーション/デシリアライゼーションの場合、単一メッセージ変換は構成済みの単一メッセージ変換を適用し、受信(受信コネクタの場合)はメッセージをターゲットデータストアに書き込みますなし
ソースコネクタには配信不能キューがないことに注意してください。
エラー処理構成プロセス
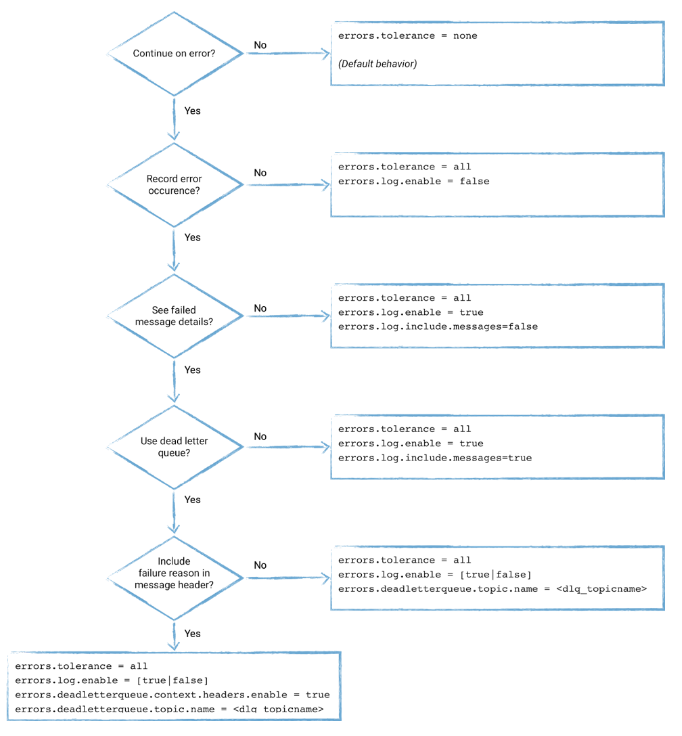
コネクタのエラー処理の構成については、次の手順に従ってください。
総括する
エラーの処理は、安定した信頼性の高いデータパイプラインの重要な部分です。データの使用方法に応じて、2つのオプションがあります。パイプラインのエラーメッセージが受け入れられず、上流に深刻な問題があることを示している場合、処理はすぐに停止する必要があります(これはKafkaコネクタのデフォルトの動作です)。
一方、分析または重要でない処理のためにデータをストレージにストリーミングするだけの場合は、エラーが伝播しない限り、パイプラインを安定して実行し続けることがさらに重要です。この時点で、エラー処理方法を定義できます。推奨される方法は、配信不能キューを使用して、Kafkaコネクタから利用可能なJMXメトリックを綿密に監視することです。
やっと
これを読んだ読者は転送したりフォローしたりすることができ、さらに注目の記事は将来更新されます!