1. HDFSの全体的なアーキテクチャ
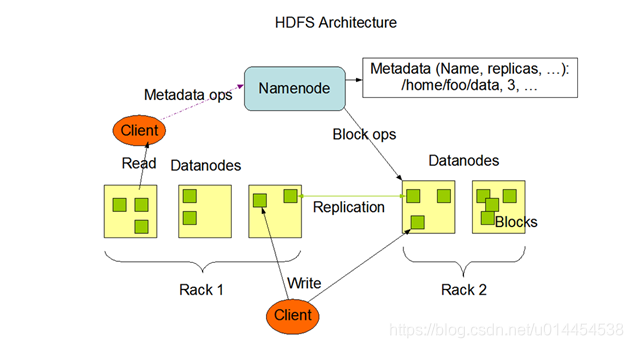
- あいまいな語彙の説明:
Client:APIまたはHDFSコマンドを介してHDFSにアクセスするエンドは、クライアントと見なすことができます。Rack:ラック、コピーの配置戦略はラックに関連しています。Block Size:Hadoop2.7.3のデフォルトは128 Mを開始し、次のデフォルトのHadoop2.7.3 64 Mを開始します。
2.ブロック、パケット、チャンクの関係
- ブロック、パケット、チャンクはすべて、HDFSに関与するデータストレージユニットです。
- 私たち自身のHadoopでXMLファイルを設定することができます
core-site.xml、hdfs-site.xmlので、私は変更を加える方法がわからないとき、あなたが見ることができcore-default.xml、hdfs-site.xmlおよび他の文書。
①ブロック
- ブロックは、HDFSでのファイルのパーティション分割の単位です。64Mを持たないファイルはブロックを占有します。サイズはファイルの実際のサイズ、ブロックサイズはブロックのサイズです。
hdfs-site.xmlファイル内のdfs.block.size構成アイテムを使用して、デフォルトのブロックサイズを変更できます。- ブロックとディスクのアドレス指定時間と送信時間の関係:
- ブロックが大きいほど、ディスクのアドレス指定時間が短くなり、データ転送時間が長くなります。
- ブロックが小さいほど、ディスクのアドレス指定時間が長くなり、データ転送時間が短くなります。
- ブロック設定が小さすぎます:
- NameNodeのメモリオーバーロード:ブロック設定が小さすぎる場合、
NameNode多数の小さなファイルメタデータ情報がNameNodeメモリに格納され、メモリのオーバーロードが発生します。 - アドレッシング時間が長すぎる:ブロックの設定が小さすぎると、ディスクのアドレッシング時間が長くなり、プログラムは常にブロックの先頭を探すようになります。
- ブロックの設定が大きすぎます:
- マップタスクの時間が長すぎる:
MapReduce中マップは通常、一度に1つのデータブロック内のタスクのみを処理します。ブロックの設定が大きすぎると、マップタスクの処理時間が長くなります。 - データ転送時間が長すぎる:ブロックの設定が大きすぎると、データ転送時間がデータアドレス指定時間をはるかに超えて、データ処理速度に影響します。
②パケット
- パケットは2番目に大きい単位で、DFSClientとDataNodeまたはDataNodeのパイプライン間のデータ転送の基本単位です。デフォルトのサイズは64 kbです。
hdfs-site.xmlファイル内のdfs.write.packet.size構成アイテムを使用して、デフォルトのパケットサイズを変更できます。
③チャンク
- チャンクはそれは、最小単位である
DFSClientとDataNode、またはDataNodeさPipelineとの間で行われるデータチェックの基本単位、デフォルトは512バイト。 core-site.xmlファイル内のio.bytes.per.checksum構成アイテムを使用して、デフォルトのチャンクサイズを変更できます。- データ検証の基本単位として、各チャンクは4バイトの検証情報を運ぶ必要があります。したがって、実際にパケットに書き込まれると、516バイトになり、実際のデータとチェックデータの比率はになり
128 : 1ます。 - 例: 128Mファイルは256チャンクに分割でき
256 * 4 byte = 1 M、検証情報は合計で伝達する必要があります。 - 3つの要約:
- チャンクがある
DFSClientとDataNode又はDataNodeさPipelineとの間で行われるチェックデータ、基本単位のパリティ情報を運ぶために、各4バイトのチャンク必要。 - パケットである
DFSClientとDataNode又はDataNodeさPipelineとの間で行われるデータ伝送チャンクの実際のサイズを516バイトとしてパケットに書き込まれるベースユニット。 - ブロックはファイルブロックの単位であり、無数のパケットがブロックを形成します。小さなファイルはブロックサイズ未満ですが、メタデータスロットを占有し、
NameNodeメモリの過負荷を引き起こします。
④書き込み処理における3層バッファ
- 書き込みプロセスには
DataQueue、チャンク、パケット、および3つの粒度の3層キャッシュが含まれます。
- データが流入
DFSOutputStreamすると、チャンクサイズのバッファができます。データがこのバッファーをいっぱいにするか、強制flush()操作が発生すると、チェックサムが計算されます。 - チャンクとチェックサムは一緒にパケットに書き込まれ、複数のチャンクがパケットを埋めると、パケットは
DataQueueキューに入ります。 DataQueueパケットはスレッドによって取り出され、に送信されます。書き込みが成功したことが確認されなかったパケットDataNodeは、確認のためにAckQueueに移動されます。DataNodeack(書き込み成功)を受け取った場合、ResponseProcessor責任のあるパケットはAckQueue削除されず、それ以外の場合はDataQueue、再書き込みに移ります。
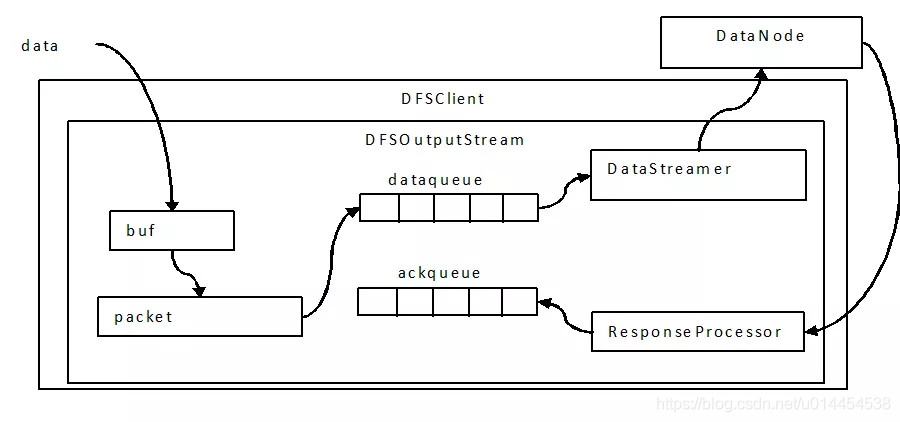
3層バッファー
3.基本的な知識
NameNode
- メタデータ情報(メタデータ)を管理します。メタデータ情報のみが保存されることに注意してください。
- namenodeはメタデータ情報を管理し、アクセスとクエリのためにメモリにコピーを置きます。メタデータ情報は、fsimageとeditsファイルを介してディスクに永続化されます。
- Hadoopのバージョン1.0は、SecondaryNamenodeを使用してfsimageをマージし、ファイルを編集しますが、このメカニズムではホットバックアップの効果を実現できません。Hadoop 1.0のネームノードには単一障害点があります。
- メタデータは大きく2つのレベルに分かれています。名前空間管理レイヤー。ファイルシステム内のツリーのようなディレクトリ構造と、ファイルとデータブロック間のマッピング関係を管理します。ブロック管理層は、ファイルシステム内のファイルの物理ブロックと実際のストレージの場所の間のマッピング関係BlocksMapを管理する役割を果たします。
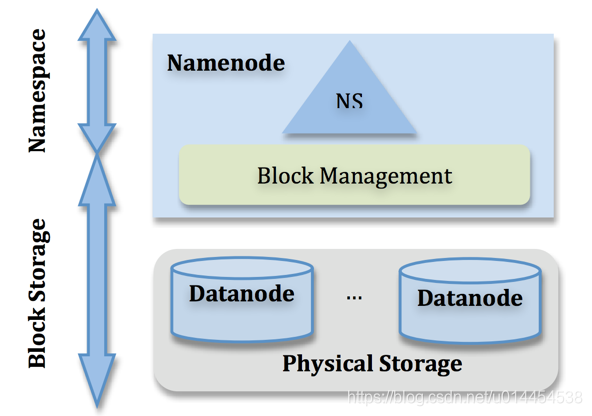
データノード
- ファイルブロックを格納するために使用されるデータノード。
- データノードの停止によるデータの損失を防ぐために、ファイルブロックをバックアップする必要があり、ファイルブロックのデフォルトは3つのコピーです。
ラック
- ラック、HDFSはラック認識戦略を使用してレプリカを配置します。
- 最初のコピー:ライターがdataNodeの場合は、直接ローカルに配置します。それ以外の場合は、格納するdataNodeをランダムに選択します。
- 2番目のコピー:リモートラックのdataNode
- 3番目のコピー:2番目のコピーと同じリモートラック上の別のdataNode。
- この配置方法により、ラック間の書き込みトラフィックが減少し、書き込みパフォーマンスが向上します。
- 3つ以上のコピー:残りのコピーの配置要件は、次の条件を満たしています。
- dataNodeはブロックのコピーを1つだけ持つことができます
- Hadoopクラスターのコピーの最大数は、dataNodeの総数です。
参照リンク:HDFSレプリカ配置ポリシー
クライアント
- クライアント、APIまたはコマンドを介して操作されるすべての端をクライアントと見なすことができます
blockSize
- 通常、データブロックにはデフォルトサイズがあり、hdfs-site.xmlファイルで設定できます
dfs.blocksize。 - Hadoop1.0:64MB。Hadoop2.0:128MB。
- ブロックサイズの問題:ビッグデータ処理の観点からは、ブロックが大きいほど良いです。したがって、技術の発展により、ブロックサイズがディスクのアドレス指定の数を減らし、それによってアドレス指定時間を短縮するため、将来のブロックはますます大きくなります。
4. HDFS読み取りおよび書き込みプロセス
①HDFSの読み込みプロセス
- クライアントは、DistributedFileSystem.open()メソッドを呼び出して、読み取るデータブロックの入力ストリームオブジェクト(FSDataInputStream)を取得します。
- open()メソッドの実行中、DistributedFileSystemはRPCを使用してNameNodeを呼び出し、ブロックのすべてのコピーのdataNodeアドレスを取得します。open()メソッドが実行されると、入力ストリームDFSInputStreamをカプセル化するFSDataInputStreamオブジェクトが返されます。
- 入力ストリームFSDataInputStream.read()メソッドを呼び出します。これにより、DFSInputStreamは、近接性の原則に従って、データの読み取り(ネットワークトポロジの距離)に適したdataNodeに自動的に接続します。
- read()メソッドはループで呼び出され、dataNodeからクライアントにデータを転送します。
- 現在のブロックを読み取った後、現在のdataNodeとの接続を閉じます。次のブロックのdataNodeとの接続を確立して、次のブロックの読み取りを続行します。
このプロセスはクライアントには透過的であり、クライアントの観点からは、1つの連続ストリームのみが読み取られるようです。
- クライアントがすべてのブロックの読み取りを完了したら、FSDataInputStream.close()を呼び出して入力ストリームを閉じ、ファイルの読み取りプロセスを終了します。
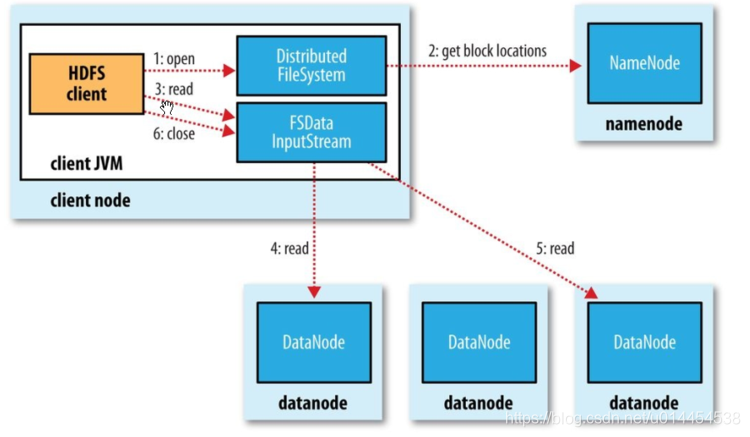
- 読み取りエラー:
- 読み取り処理中にエラーが発生した場合、DFSInputStreamは隣接するDataNodeのブロックを読み取ろうとします。同時に、問題のあるdataNodeが記録され、後続のデータ要求プロセスでそれと通信しません。
- ブロックが読み取られるたびに、DFSInputStreamはデータの整合性をチェックします。損傷がある場合、クライアントはNameNodeに通知し、他のDataNodeからコピーを読み取り続けます。
②HDFS書き込みプロセス
- 分散ファイルシステムクライアントが
DistributedFileSystem.create( )メソッドを呼び出し、ファイルNameNodeを作成するリクエストを送信します。 - create()メソッドが実行されると
DistributedFileSystem、RPCリクエストがNameNodeに送信され、NameNodeはファイル作成前にチェックを完了します。チェックに合格した場合、最初に書き込み操作をEditLogに記録し、次に出力ストリームオブジェクトFSDataOutputStream(内部的にカプセル化されたDFSOutputDtream)を返します。 - クライアントは
FSOutputStream.write()関数を呼び出し、対応するファイルにデータを書き込みます。 - ファイルを書き込むとき、
DFSOutputDtreamファイルはパケットに分割され、パケットはDataQueueに書き込まれます。DataStreamerDataQueueの管理を担当し、コピーを格納するための適切な新しいブロックを割り当てるようにNameNodeに要求します。DataNode間にパイプラインが形成され、パイプラインを通じてパケットが送信されます。
-
DataStreamerパイプラインを介してパケットをDataNode1にストリーミングします。 - DataNode1は受信したパケットをDataNode2に送信します
- DataNode2は受信したパケットをDataNode3に送信して、パケットのトリプルコピーストレージを形成します。
- コピーの整合性を確保するために、パケットを受信したDataNodeは送信側にackパケットを返す必要があります。十分な応答を受信すると、パケットは内部キューから削除されます。
- ファイルが書き込まれた後、クライアントは
FSOutputStream.close()メソッドを呼び出してファイル入力ストリームを閉じます。 DistributedFileSystem.complete()メソッドを呼び出して、ファイルが正常に書き込まれたことをNameNodeに通知します。