記事ディレクトリ
リファレンス:
ウーエンダビデオクラスの
ディープラーニングノート
1.機械学習戦略
モデルのパフォーマンスを改善する方法
- さらにデータを収集する
- トレーニングセットの多様性(例:猫の識別、さまざまなポーズでの猫の収集、反例)
- トレーニング時間が長い
- さまざまな最適化アルゴリズム(Adam最適化など)を試す
- 大きい/小さいニューラルネットワーク
- DropOutの正規化を試す
- L2正則化を追加してみてください
- 新しいネットワーク構造(変更されたアクティベーション機能、隠しユニットの数)
あなたはそれを試すことができますが、半年かかり、最終的にそれが間違っているとしたらどうでしょうか?その後、泣く!
どれが効果的で、どれが安全に廃棄できるかを判断する必要があります。
2.直交化
さまざまな調整済み変数の間に結合関係があってはなりません

モデルのパフォーマンスボトルネックの場所を特定し、対応する方法を使用して改善する
早期停止は直交性の低い方法です。
あまりに早く停止すると、トレーニングセットの精度に影響します。同時に、開発セットの精度が向上します。同時に
2つの点に影響します。他の直交制御方法を使用してみてください。
3.単一の数値評価指数
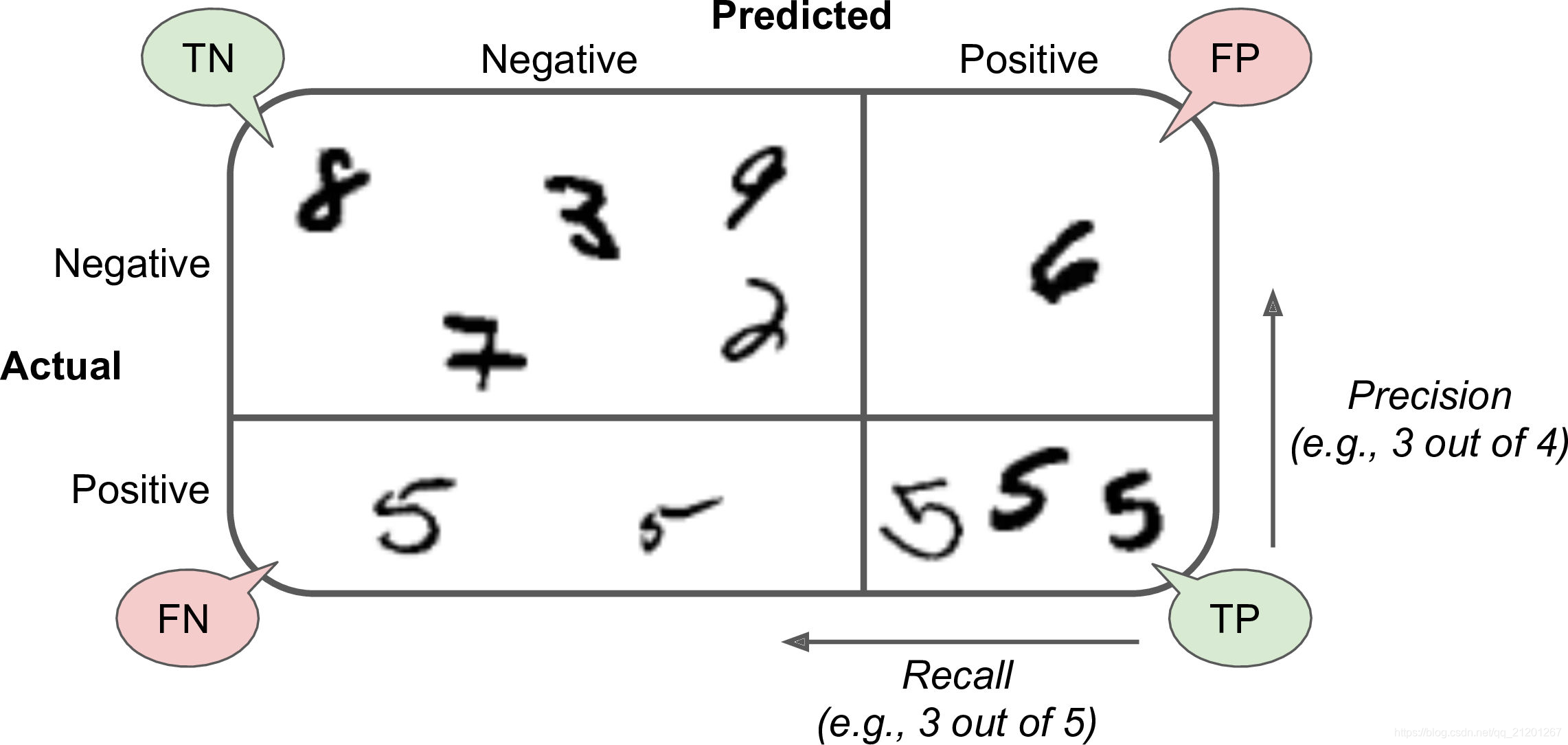
- 精度、再現率、F1値(最初の2つの平均)
F 1 = 2 1精度+ 1再現率= 2 ∗精度∗再現率精度+再現率= TPTP + FN + FP 2 F 1 = \ frac {2} {\ frac {1} {\ text {precision}} + \ frac { 1} {\ text {recall}}} = 2 * \ frac {\ text {precison} * \ text {recall}} {\ text {precison} + \ text {recall}} = \ frac {TP} {T P + \ frac {F N + FP} {2}} F 1=精度1+想起12=2∗精度 +想起精度 ∗リコール=T P+2F N + F PT P

ある単一の実数の評価指標あなたの効率や意思決定の効率を向上させることができますが
4.指標を満たし、最適化する

N個のインジケーターを考えると、最適化インジケーターとしてそれらの1つを選択するのが妥当な場合があります。
そのインジケーターを最適化しようとすると、残りのN-1インジケーターはすべて満足のいくものになります。つまり、特定のしきい値に達している限り、しきい値内のインジケーターのサイズは気になりません。
5.トレーニング/開発/テストセット部門

例:最初の4つの領域のデータは開発セットとして使用され、最後の4つの領域はテストセットとして使用されます
- 非常に悪い、彼らはおそらく異なる分布からのものです
- すべてのデータをランダムにシャッフルして再分割する必要があります
6.開発セットとテストセットのサイズ


7.開発/テストセットとメトリックをいつ変更すべきか

追加の変更点:
误差:1 ∑ w(i)∑ i = 1 mdevw(i)L {(y ^(i)≠y(i))}误差:\ frac {1} {\ sum w ^ {( i)}} \ sum_ {i = 1} ^ {m_ {dev}} w ^ {(i)} \ mathcal {L} \ left \ {\ left(\ hat {y} ^ {(i)} \ neq y ^ {(i)} \ right)\ bigg \} \ right。エラーの違い:Σw(私)1i = 1ΣメートルD E Vw(i ) L{
(そして^(私)=そして(私))}
w(i)= {x(i)が非ポルノ画像である場合は1 x(i)がポルノ画像である場合は10 w ^ {(i)} = \ left \ {\ begin {array} {cl} 1&\ text {if } x ^ {(i)} \ text {ポルノではない画像です} \\ 10&\ text {if} x ^ {(i)} \ text {ポルノ画像です} \ end {array} \ right。 w(私)={ 11 0 もし x(i )非エロ画像 もし x(私)はポルノです
上記の方法では、自分でデータを調べ、ポルノ画像にマークを付ける必要があります
たとえば、開発/テストセットはすべて非常に明確なプロの写真であり、アプリケーションはついにプロでない写真(ぼやけた、悪い角度など)のために起動されます。
次に、開発/テストセットを変更し、専門外の写真をトレーニングデータとして追加します。
8.人間のパフォーマンスレベル
機械学習のレベルと人間のレベルを比較するのは当然です。私たちは機械が人間よりもうまく機能することを望んでいます

機械学習アルゴリズムが人間よりも劣っている限り、人間が得意なタスクの場合は、データにタグを付けさせることができ、学習アルゴリズムにフィードしてアルゴリズムを改善するためのデータが増えます。
9.逸脱を避ける

10.人間のパフォーマンスを理解する


11.卓越したパフォーマンス

ケースB:0.5%のしきい値(最高の医師のエラーよりも低い)を超える場合、機械学習の問題をさらに最適化するための明確なオプションと指示がない
12.モデルのパフォーマンスを改善する
総括する:
上記の方法は、直交化の改良されたアイデアです。

- トレーニングセットエラーとベイズ推定エラーのギャップ:回避可能なバイアス
- トレーニングセットエラーと開発セットエラーのギャップ:分散
偏差を改善する:
- 大きいモデル
- より長く、より多くの反復トレーニング
- より優れた最適化アルゴリズム(Momentum、RMSprop、Adam)
- 新しいニューラルネットワーク構造の改善
- 優れたハイパーパラメータ
- アクティベーション機能、ネットワーク層の数、および隠しユニットの数を変更します
- その他のモデル(サイクリックNN、たたみ込みNN)
差異を改善する:
- トレーニングするデータをさらに収集する
- 正則化(L2正則化、ドロップアウト正則化、データ拡張)
- 新しいニューラルネットワーク構造の改善
- 優れたハイパーパラメータ
テストの割り当て
参考ブログ投稿リンク
私のCSDN ブログアドレスhttps://michael.blog.csdn.net/
QRコードを長押しまたはスキャンして、私の公式アカウント(Michael Amin)をフォローし、一緒に来て、学び、一緒に進歩してください!
