記事ディレクトリ
データベース設計。
- データベース設計とは、ユーザーのニーズに応じてデータベースの構造と動作を開発するプロセスを指します。
- 特定のアプリケーション環境に対して、最適なデータベースモデルを構築し、データベースとそのアプリケーションシステムを確立します。ユーザーの情報要件と処理要件を満たすためにデータを効果的に格納します。
- データベース設計は、構造設計と動作設計に分けられ、前者には概念設計、論理設計、物理設計が含まれ、後者にはデータベースでのユーザー操作が含まれます。
- データベース設計の特徴:
①構造は動作に由来します—構造設計と動作設計の組み合わせを強調します;
② 動作は常に変化します— "繰り返される探索、段階的な改良"
1.データベース設計方法。
- 直感的なデザイン
- 規範的設計法
- コンピューター支援設計
- 最新のデータベース設計方法
1.1直感的な設計方法。
- 直感的な設計方法は手動試行錯誤法とも呼ばれ、最も早く使用されたデータベース設計方法です
- この方法は、設計者の経験とスキルに依存し、科学理論と工学原理のサポートに欠けており、設計の品質を保証することは困難です。データベースを一定期間稼働させた後でさまざまな問題が発見されることがよくあります。そのため、データベースを再度変更できるため、システムメンテナンスのコストが増加します。
1.2規範的な設計方法。
- [ERモデルに基づくデータベース設計方法] ER図を使用して、Eがエンティティを表し、Rが関係を表す、現実のエンティティ間の接続を反映する概念モデルを構築します。
- [3NFベースのデータベース設計方法]データベース内のすべての属性と属性間の依存関係を決定し、3NF制約の非準拠を分析し、それらを射影によって分解し、いくつかの3NF関係パターンのコレクションに正規化します。
- 【ビューベースのデータベース設計方法】まず、各アプリケーションのデータを分析し、アプリケーションごとに独自のビューを確立し、それらのビューを組み合わせてデータベース全体の概念モデルを構築します。
1.3コンピュータ支援設計法。
- コンピュータ支援設計法とは、データベース設計の特定のプロセスで標準化された設計をシミュレートする方法を指し、人間の知識または経験に主導され、人間とコンピュータの相互作用を通じて設計の特定の部分を実現します。
1.4最新のデータベース設計方法。
- ソフトウェアエンジニアリングの考え方を中心に、ER図の設計は通常、3NF設計とビュー設計実現モードの評価と最適化によって補足され、さまざまな設計方法の利点を吸収します。
- 設計の調整効率と標準化の程度を向上させるために、最新のデータベース設計プロセスでは、コンピューター支援設計ツールを通じて標準化されたデータベース設計結果も取得します。
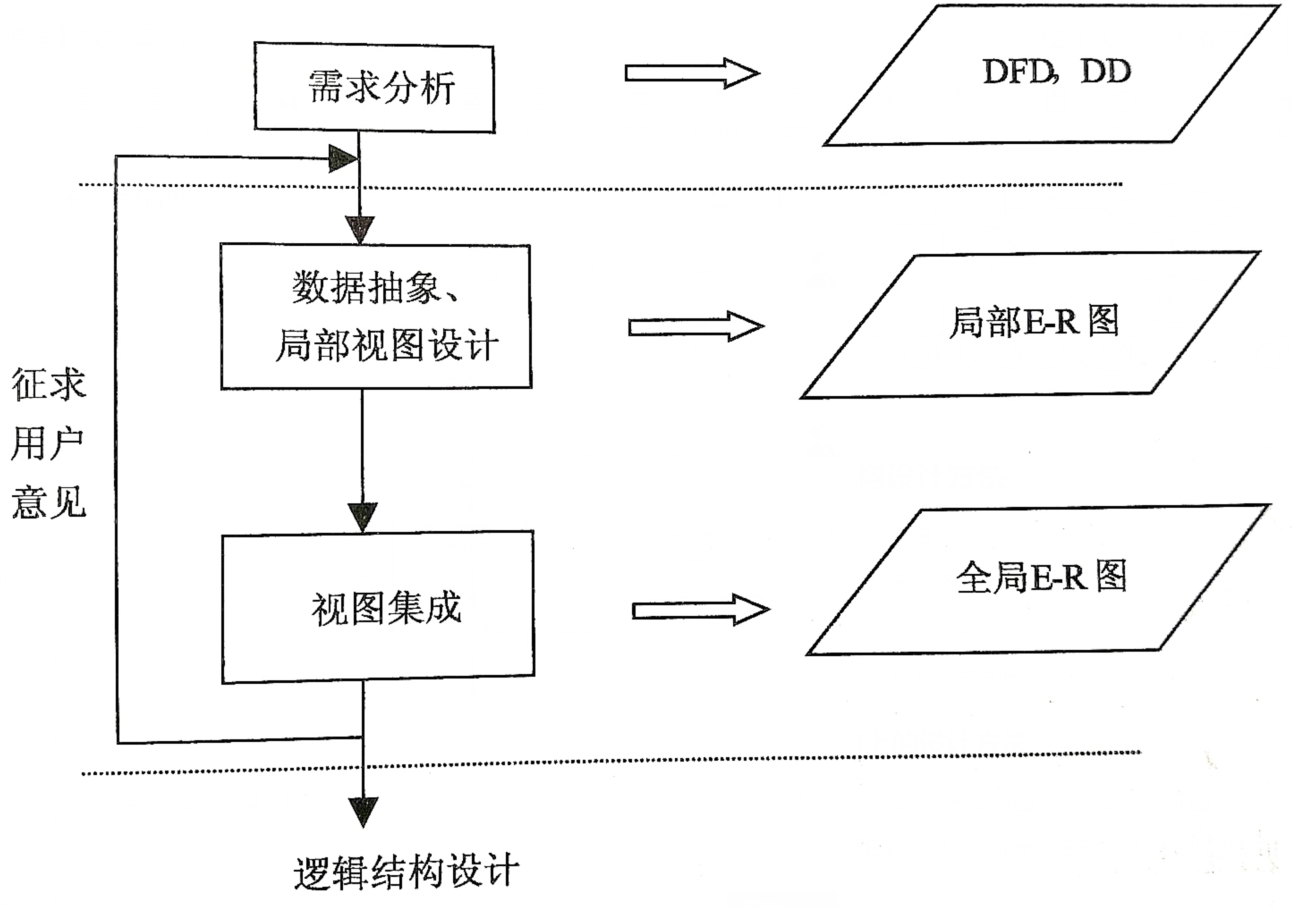
2.データベースの設計手順。
- 【システム要件分析】情報内容や処理要件を収集・分析します。
- 【概念構造設計】ユーザーニーズを表現する概念モデル。
- 【論理構造設計】概念モデルから派生したデータモデル。
- 【物理構造設計】ストレージ構造とアクセス方法。
- 【データベース実装】データ保存、データベースアクセス手順書作成。
- 【データベース運用・保守】システム運用実績を収集・記録します。
- 約概念構造、論理構造と物理構造において、データベースシステムの概要(III)に記載されました。
- 概念モデルは、特定のコンピューターシステムに依存せず、コンピューターでの情報の表現方法、処理方法などの問題も含まず、特定のアプリケーションシナリオで関心のある情報を説明するためにのみ使用されます。
- 論理モデルとは、データや情報をコンピュータの視点に沿ってモデル化するものであり、厳密な形式で定義されたコンピュータの世界でのモデルであり、コンピュータへの実装が容易です。DBMSは特定の論理モデルに従って設計されます。つまり、データベースは、DBMSによって指定されたデータモデルに従って結合および確立されるため、論理モデルは主にDBMSの実現に使用されます。
- 物理モデルは、最下位レベルのデータを抽象化したものであり、ディスク上のデータの保存方法と保存方法を記述し、コンピュータシステムを対象としています。物理モデルの具体的な実現はDBMSのタスクであり、論理モデルから物理モデルへの変換もDBMSによって完了します。
2.1システム要件分析。
- システム要件分析はデータベース設計の出発点であり、将来の特定の設計に備えます。需要分析の結果がユーザーの実際の要件を正確に反映しているかどうかは、後続の各段階の設計に直接影響し、設計結果が合理的かつ実用的であるかどうかに影響します。
- システム要件分析が正しくないか誤解されている場合、多くのエラーはシステムのテスト段階まで発見されず、修正には多くのコストがかかります。
- システム要件分析のタスク:①ユーザーアクティビティの調査と分析、ユーザー要件と目標の明確化、②需要データの収集と分析、システム境界の決定、③需要分析レポートのコンパイルと専門家によるレビューの整理。
- システム需要分析の方法:①トップダウン需要分析;②ボトムアップ需要分析。
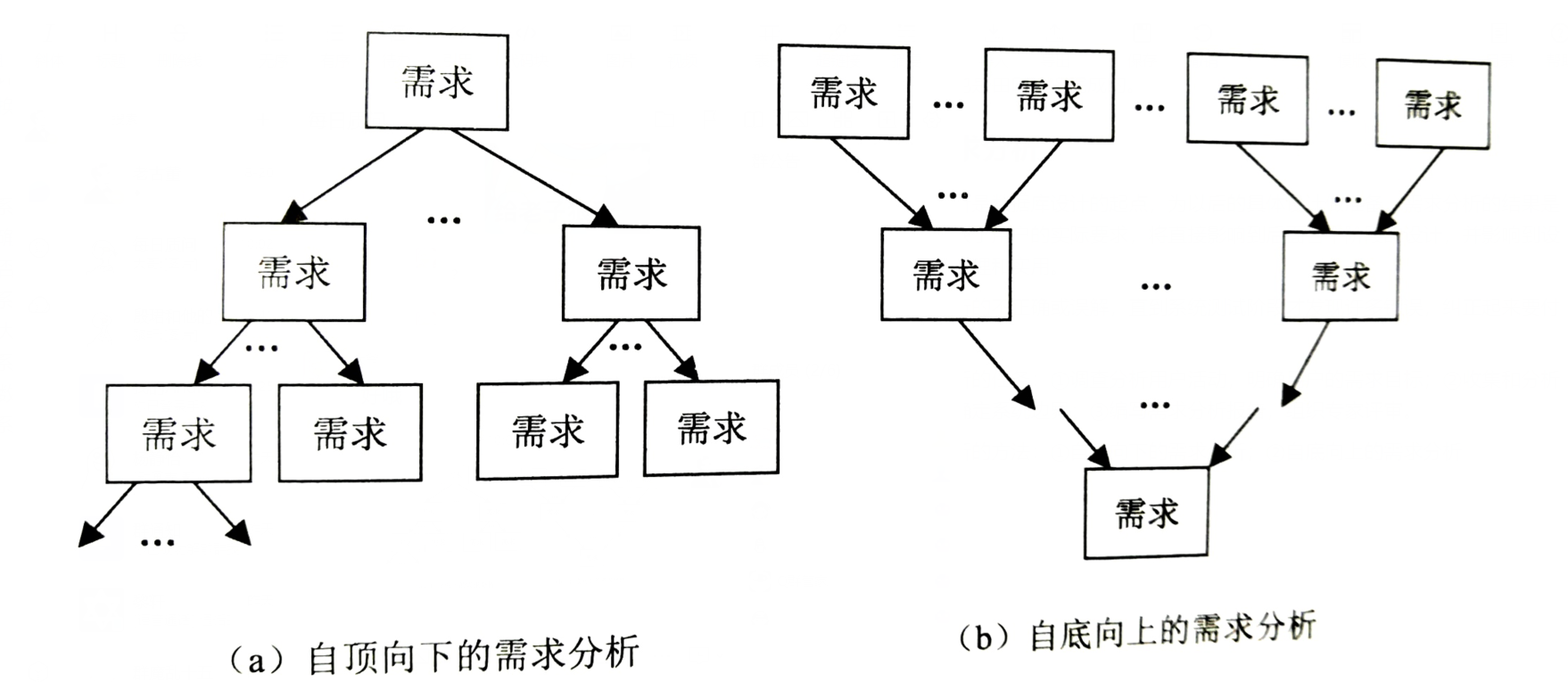
- トップダウン分析方法(構造化分析、ASとも呼ばれます)は、最も単純で最も実用的な分析方法です。これは、トップレイヤーから始まり、レイヤーごとの分解でシステムを分析し、データフロー図(DFD)とデータディクショナリー(データディクショナリー、DD)でシステムを記述します。
- [データフロー図DFD]名前付き矢印を使用してデータフローを表し、円を使用して処理を表し、閉じていない四角形またはその他の形状を使用してストレージを表し、閉じた四角形を使用してソースと出力を表します。
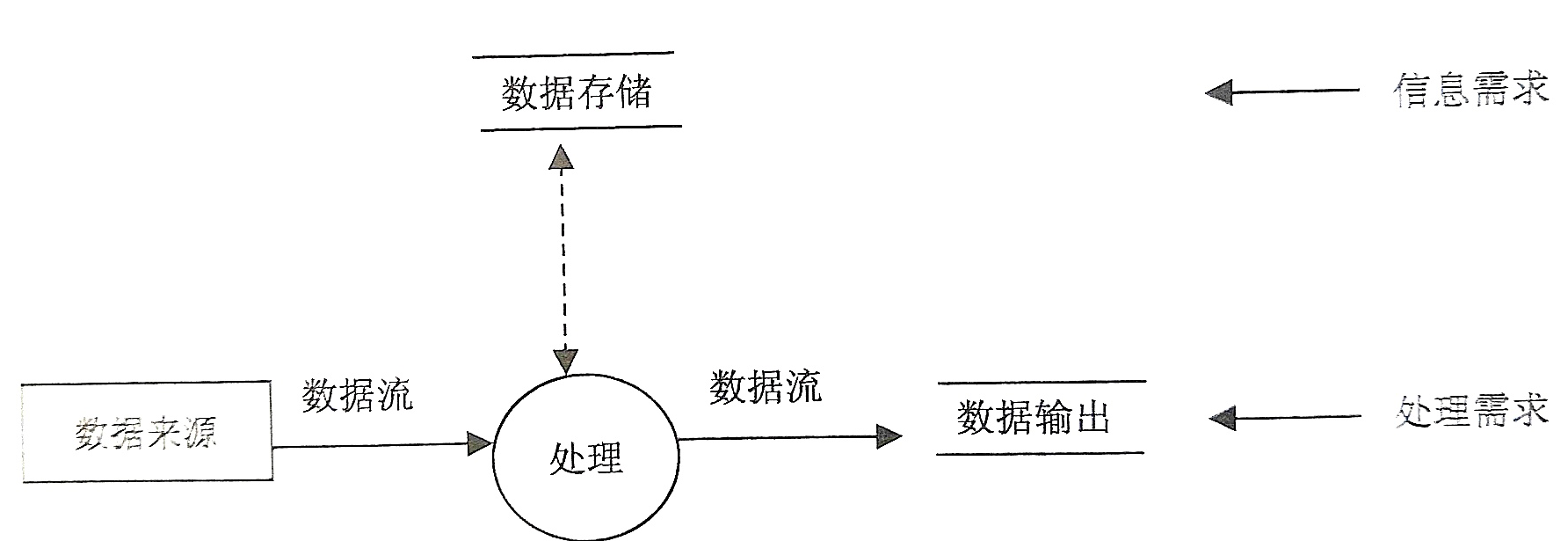
- [データディクショナリDD]データディクショナリは、システム内のデータの詳細な説明であり、さまざまなデータ構造と属性のリストです。需要分析段階では、通常、データアイテム、データ構造、データフロー、データストレージおよび処理プロセスの 5つの部分で構成されます。最終的なデータフローダイアグラムとデータディクショナリは、システム分析レポートのメインコンテンツです。これが次のステップです。概念的な構造設計の基礎。
[例]学部教育リンククラスとコース選択のコアビジネス:コースサービスは、コースの教師の指導のみを考慮します。コース選択ビジネスは、主にどの学生がどのコースを選択したかと、このコースのスコアを記録します。
- 【データフロー図・
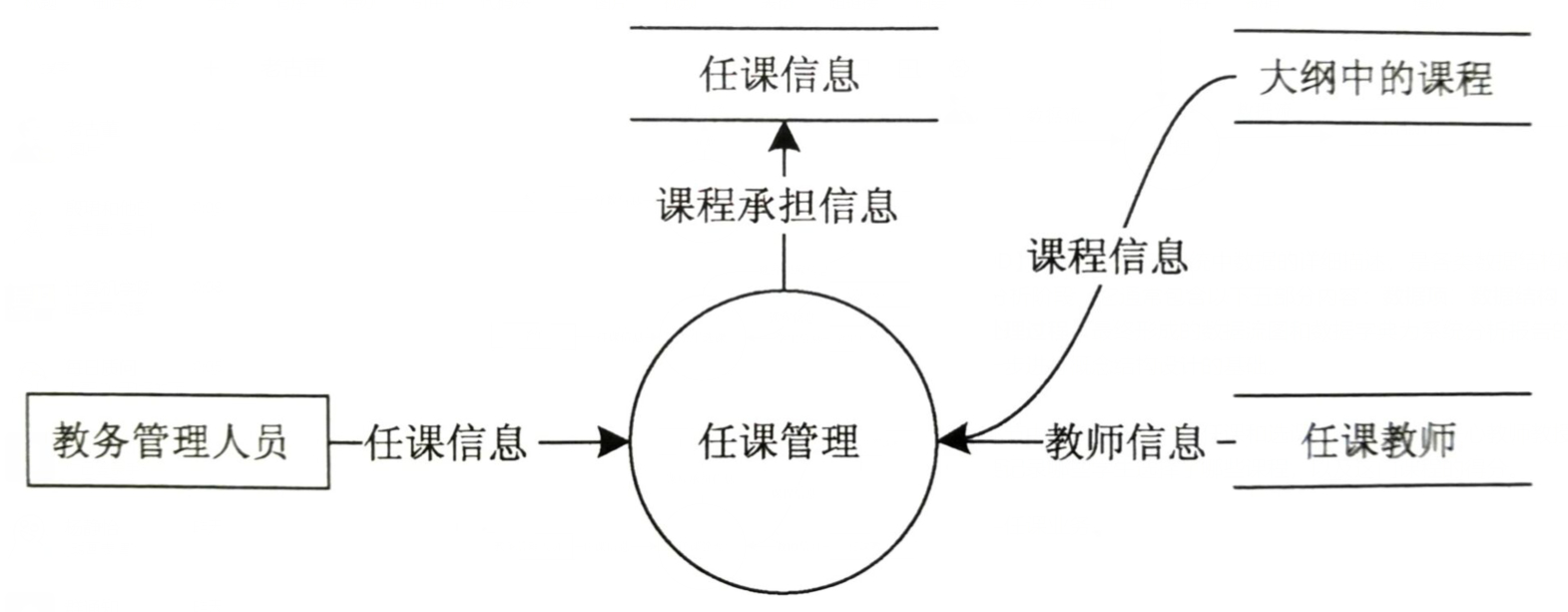
授業業務】授業整理の過程で、指導担当者はシラバス内の講座を、概要の講座情報と講師の講師情報をもとに、関連する教員に配置し、整理して保存する必要があります。クラス情報。 - 【データフロー図・コース
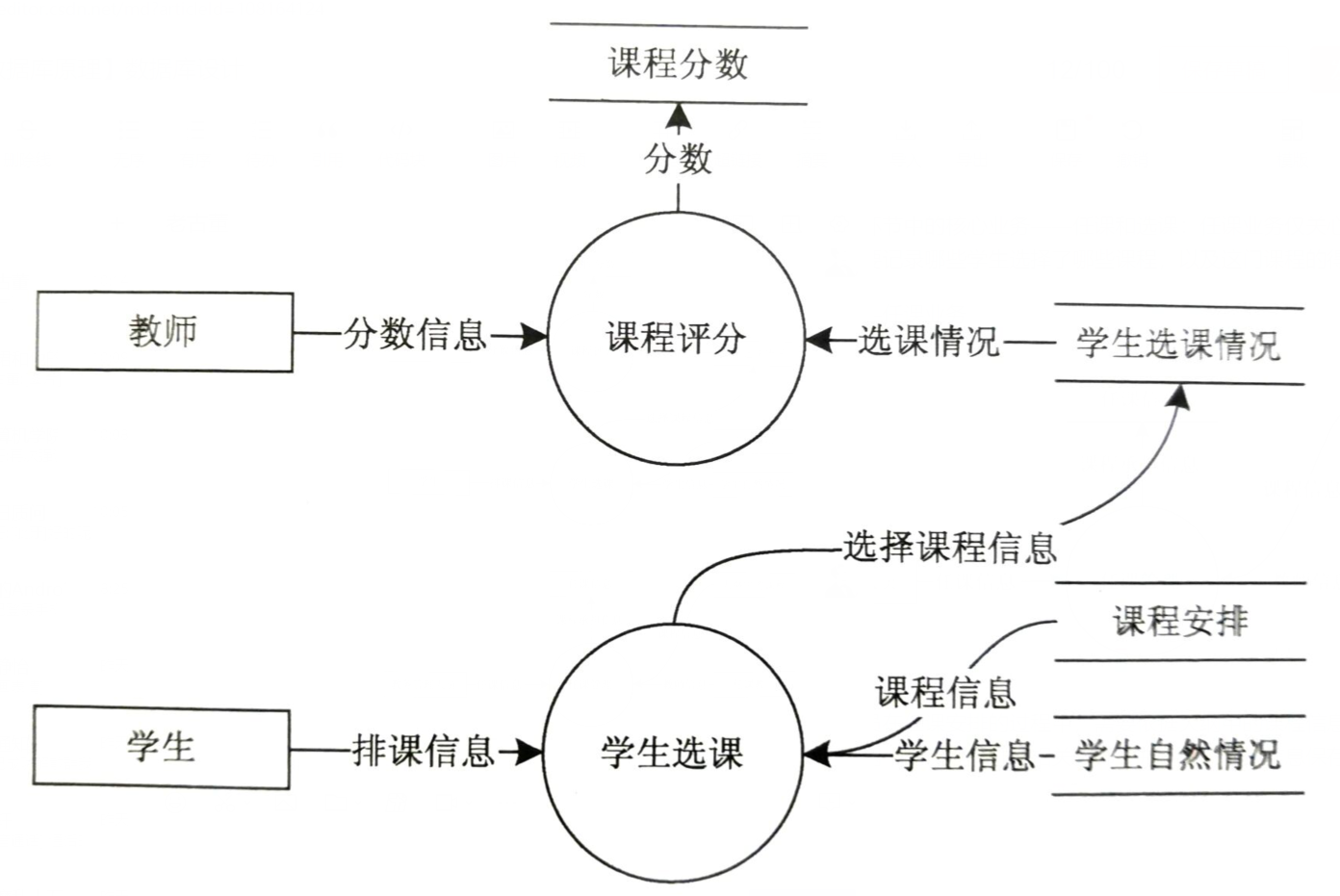
選択サービス】学生がコースを選択する場合、現在の学期のコース配置と学生の自然条件(学年、時間配置など)に基づいてコースを選択する必要があります。選択したコース情報は、学生のコース選択状況に保存されます。学期コースが終了すると、講師はコースの選択に基づいて学生を採点し、最終スコアはコーススコアに保存されます。 - 【データ辞書】
① 学生の自然状況に関する情報:学生ID、氏名、年齢、学部等
② コース情報:コース番号、氏名、講師等
③ 教員情報:教員番号、氏名、教員の性別、職名、講座等
④ クラス情報:コース名と教師名。
⑤ 学生のコース選択情報:学生名、コース名、教師名など
⑥ コーススコア情報:学生名、コース名、スコアなど - 【隠しデータ構造】上記の情報に加えて、システム内に隠しデータ構造があるかどうかをさらに分析する必要があります。実際の研究結果によれば、カレッジや大学の管理は、通常、学部が中心となっており、学部が分かれていないと、学部の学生と教員の情報が混ざり合い、さまざまなビジネスに不便です。したがって、部門のデータ項目も定義する必要があります。
学部:学部番号、名前、学部教師、学部学生。
2.2概念構造の設計。
- 概念構造設計とは、ニーズ分析から得られたユーザーのニーズを情報構造、つまり概念モデルに抽象化することです。
- 概念設計を論理設計から分離すると、各段階のタスクは比較的単純になり、設計の複雑さが大幅に軽減されるため、編成と管理に便利です。
- 概念モデルは特定のDBMSによって制限されず、ストレージの配置や効率の考慮事項からも独立しているため、論理モデルよりも安定しています。
- 概念モデルには、特定のDBMSに関連付けられた技術的な詳細が含まれていません。これは、ユーザーが理解しやすく、ユーザーの情報ニーズを正確に反映する可能性が高くなります。
- 概念モデルの特性:豊富なセマンティック表現機能、通信と理解が容易、変更と拡張が容易、データモデルに変換が容易。
- ERモデルは最も有名で実用的なモデルで、1976年にPPChenによって提案された概念モデルです。
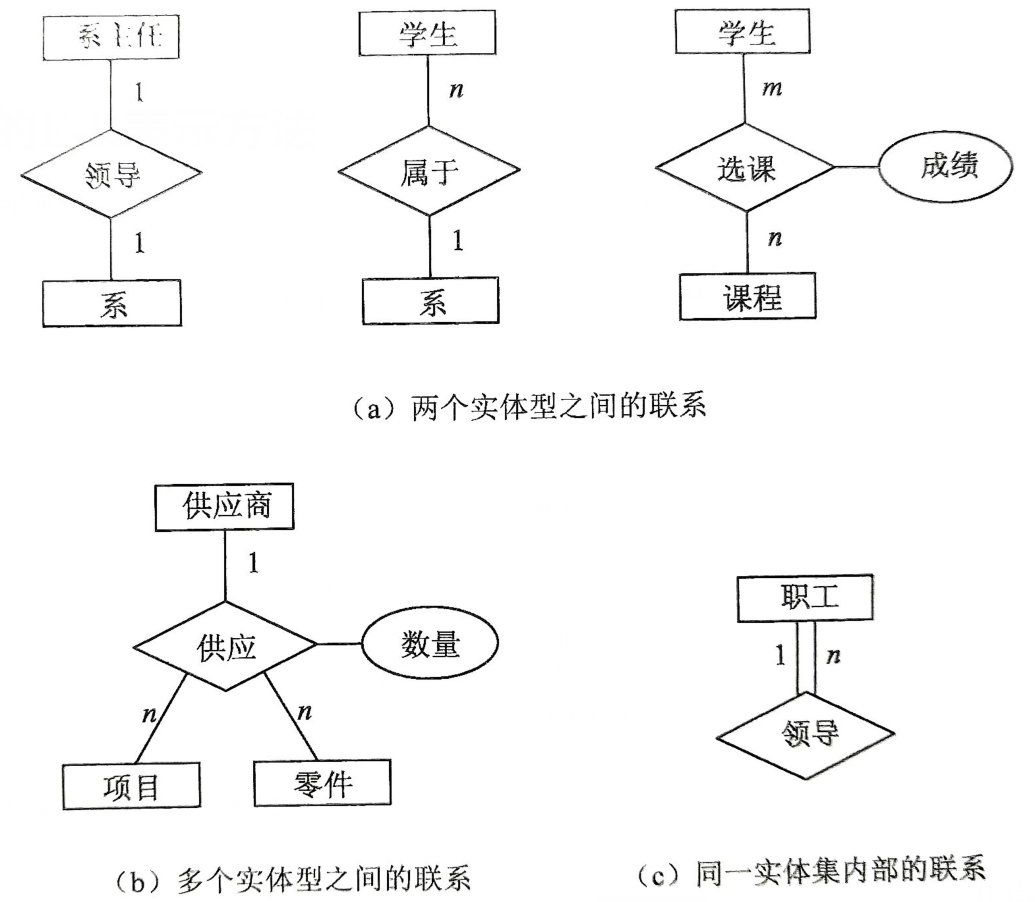
- 【エンティティタイプ】長方形の枠で表現され、枠内にエンティティ名が表示されます。
- [プロパティ]楕円形のフレームで表され、フレーム内に属性の名前がマークされ、無向エッジを使用して対応するエンティティに接続されます。
- [連絡先]は菱形のボックスで表され、連絡先の名前はボックス内でマークされ、無向エッジは関連エンティティに接続され、連絡先のタイプは無向エッジの横にマークされます。つまり、1:1、1:nまたはm:nです。

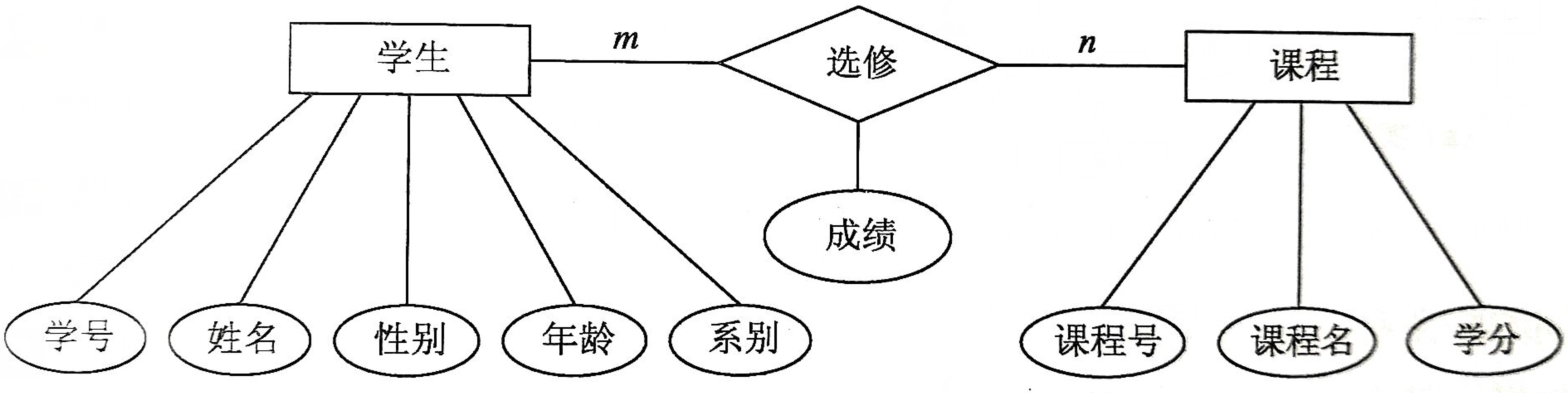
[例】学生とコースの接続の完全なER図:
2.2.1概念構造の設計方法。
- 上から下へと徐々に
- 下から上へ、罰金から全体へ
- 徐々に拡大し、徐々にコアから外側に拡大
- 混合戦略、トップダウンとボトムアップの組み合わせ
2.2.1.1ボトムアップ設計法。
- データの抽象化を実行し、部分的なER図を設計します。つまり、ユーザービューを設計します。
- 各ローカルERモデルを統合して、グローバルERモデル、つまりビューの統合を形成します。
- [部分的なERモデルの設計]①属性は分離できないデータアイテムでなければならず、他の属性で構成することはできません。
- 属性またはエンティティとしての部門:
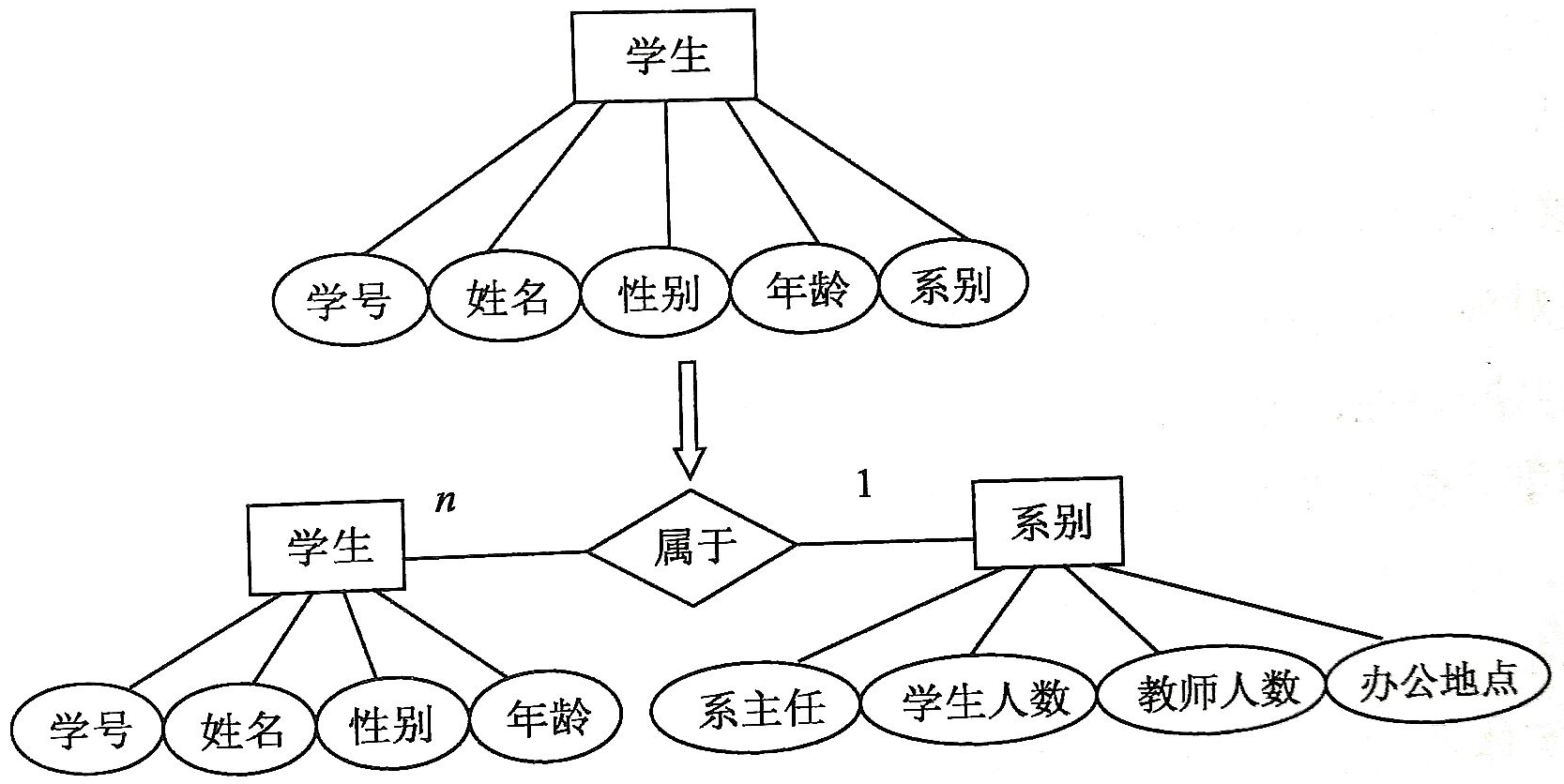
- 部分的なER図のマージ、部分的なER図間の競合の解消、および予備的なER図の生成。
- 不要な冗長性を排除し、基本的なER図を生成します。冗長性とは、冗長データとエンティティ間の冗長接続を指します。冗長データとは、基本データから導出できるデータを指します。冗長リンクは、他のリンクから派生したリンクです。
【例】
①1人の学生が複数のコースを選択でき、1つのコースを複数の学生用に選択できるため、学生とコースは多対多の関係にあります。
②1人の講師が複数のコースを教えることができ、1つのコースを複数の教師が教えることができるため、教師とコースは多対多の関係にあります。
③学部には複数の教師がいて、教師は1つの学部にしか所属できないため、学部と教師の関係は1対多であり、学部と生徒の関係も1対多です。

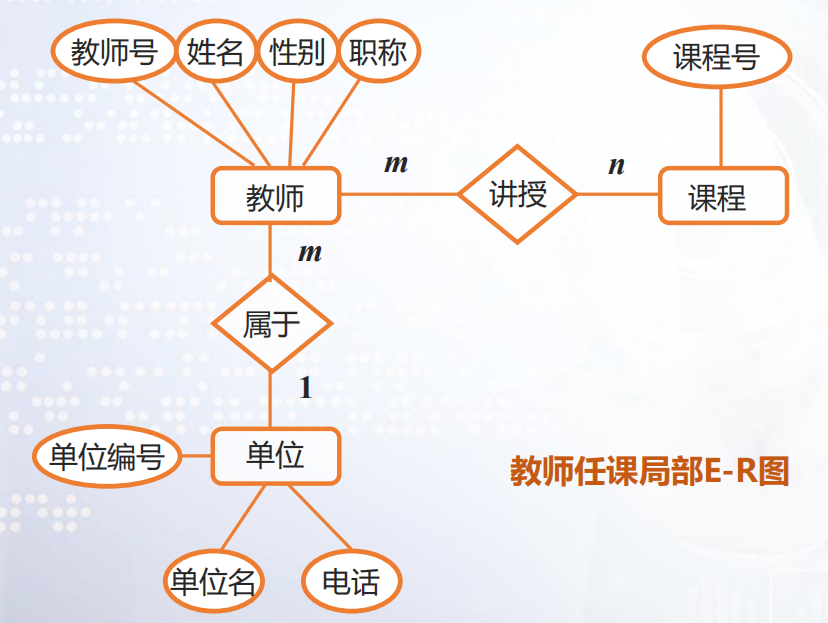
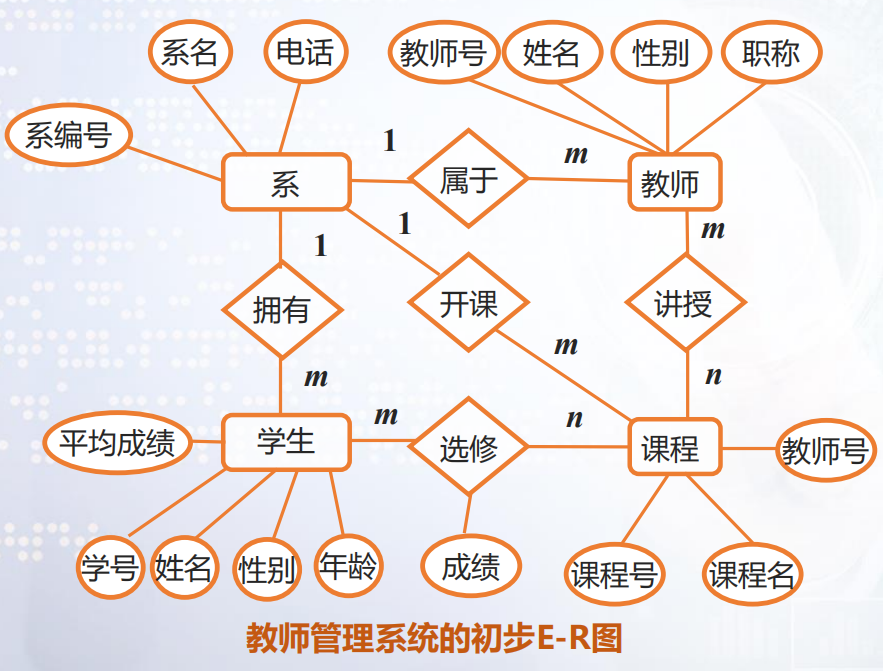

2.3論理構造の設計。
- ユーザーが必要とするデータベースを構築するには、前の手順で取得した概念モデルを、特定のDBMSでサポートされているデータモデルに変換する必要があります。ERダイアグラムで表される概念モデルは、メッシュモデル、階層モデル、リレーショナルモデルなど、DBMSがサポートする特定のデータモデルに変換できます。以下では、リレーショナルモデルについて説明します。
- [変換原理]①エンティティ:エンティティは関係モードに変換され、エンティティの属性は関係の属性であり、エンティティのコードは関係のメインコードです。②関係:関係は関係モードに変換され、関係に関連するエンティティのメインコードと関係の属性は関係の属性であり、関係のタイプに応じて関係のメインコードを決定する必要がある。
- 関係が1:1の場合、各エンティティのメインコードは関係の候補コードです。
- 関係が1:nの場合、n-endエンティティのメインコードは関係のメインコードです。
- 関係がn:mの場合、各エンティティのメインコードの組み合わせが関係のメインコードになります。
- 【特殊なケース】3つ以上のエンティティ間の複数接続の場合、複数接続に接続された各エンティティのメインコードと接続自体の属性が関係の属性に変換され、メインコードは変換後のエンティティコードの組み合わせ。

リレーショナルモデルへの変換[供給](ベンダー番号、アイテム番号、パーツ番号、数量)
【例】前ステップで得られたERに従って変換を行います。
エンティティ:
- 学生(学生番号、名前、性別、年齢)
- 部門(部門番号、部門名、電話)
- コース(コース番号、コース名)
- 教師(教師番号、名前、性別、役職)
連絡先:
- (教師番号、部門番号)に属する
- 講義(教師ID、コースID)
- 選択科目(学生番号、コース番号、学年)
- 持っている(学生番号、学部番号)
2.3.1モデルの評価と改善。
- 【機能評価】問題、遡及分析、需要分析の結果が出たら、標準化されたリレーショナルパターンのセットがユーザーのアプリケーション要件をすべてサポートしているかどうかを確認します。
- 【性能評価】実行効果、論理レコードへのアクセス数、送信量、物理構造設計アルゴリズムのモデルなど、実際の性能を推定します。
- システム要件分析と概念的な構造設計の省略により一部のアプリケーションがサポートできない場合は、新しい関係モードまたは属性を追加する必要があります。
- パフォーマンスを考慮して改善が必要な場合は、統合または分解の方法を使用できます。
- ★関係パターンをマージし、同じメインコードで関係パターンをマージします。
【例】上記で取得したリレーションモデルをマージして改善する。

最後に:
- 学生(学生番号、名前、性別、年齢、部門番号)
- コース(コース番号、コース名)
- 教師**(教師ID **、名前、性別、役職、部門番号)
- 講義(教師ID、コースID)
- 選択科目(学生番号、コース番号、学年)
- 部門(部門番号、部門名、電話)
2.4物理的構造の設計。
- 特定の論理モデルについて、アプリケーション環境に最も適した物理構造を選択するプロセス。論理モードを効果的に実装し、採用するアクセス戦略を決定します。
- 【物理構造の決定】主にリレーショナルデータベースのアクセス方法やストレージ構造を指します。
- 【物理構造の評価】評価の焦点は時間と空間の効率です。
- データベースシステムは複数のユーザーによって共有されるシステムであり、同じ関係が複数のユーザーの複数のアプリケーション要件を満たすためには、複数のアクセスパスを確立する必要があります。物理構造設計のタスクの1つは、データベース管理システムでサポートされているアクセス方法に従って選択するアクセス方法を決定することです。
- [集計]繰り返し保存して頻繁にクエリを行う場合。クエリ速度を向上させるために、属性のグループ(単一の属性を含む)で同じ値を持つタプルは物理ブロックに格納されます。この属性のグループは集約コードと呼ばれます。
- 集約は、頻繁に接続される関係に対して確立できます。
- 関係の一連の属性が同等比較条件に現れることが多い場合、単一の関係で集約を確立できます。
- 関係の一連の属性の値の反復率が非常に高い場合、この単一の関係で集約を確立できます。つまり、各集約コード値に対応するタプルの平均数は少なすぎることはできず、小さすぎると集約効果は明白ではありません。
- [インデックス]データの整合性を確保し、クエリの効率を向上させますが、メンテナンスコストに注意してください。
- 属性のグループがクエリ条件に頻繁に現れる場合は、この属性のグループにインデックス(または複合インデックス)を構築することを検討してください。
- 属性が最大値や最小値などの集計関数のパラメーターとしてよく使用される場合は、この属性にインデックスを作成することを検討してください。
- 属性のグループが接続操作の接続条件に頻繁に現れる場合は、この属性のグループにインデックスを作成することを検討してください。
- 【データ格納場所】システムのパフォーマンスを向上させるために、アプリケーションの状況に応じて、データの可変部分、安定部分、アクセス頻度の高い部分、アクセス頻度の少ない部分を分けて格納する必要があります。複数のディスクの下で、テーブルとインデックス、ログ、データベースオブジェクトの個別のストレージ。