記事ディレクトリ
インタビュー指向のブログは、Q / Aスタイルで提示されます。
質問1:サービスの登録とサービスの発見について話しますか?
回答1:
サービス登録は、システム内のすべてのサービスアドレスを管理するレジスタを維持することです。新しいサービスが開始されると、そのアドレス情報をレジスターに告白します。サービスの依存パーティは、サービスプロバイダーのアドレスをレジスターに直接要求します。サービス登録には、ZooKeeper、Consul、Etcd、Netflixのeurekaなど、多くのツールがあります。サービス登録には、クライアント登録とサードパーティ登録の2つの形式があります。
クライアント登録(zookeeper)
クライアント登録は、登録とキャンセルを担当するサービス自体です。サービスが開始したら、登録センターに登録し、サービスがオフラインになったときに登録を解除します。この期間中も、登録センターとハートビートを維持する必要があります。ハートビートはクライアントで実行する必要はありませんが、登録センターでも処理できます(このプロセスはTanhuoと呼ばれます)。この方法の欠点は、登録作業がサービスと連動しており、さまざまな言語が一連の登録ロジックを実装する必要があることです。
クライアントの登録を以下に示します。
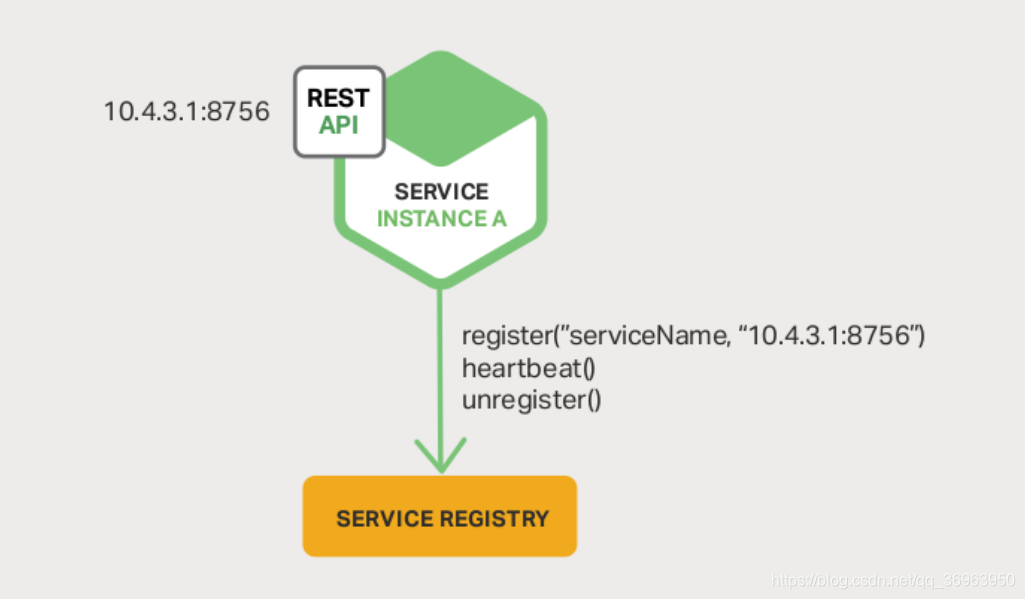
上記の説明の場合:
登録が必要なサービス、サービスは、サービスレジスタサービスレジスタを直接処理します。この2つの間には、レジスタレジスタ()、ハートビート()、登録解除/登録解除()を含む3つの方法があります。登録サービスは、低結合の設計概念を満たさない登録センターと結合する必要があり、サードパーティの登録(独立したサービスレジスタ)に依存します。
サードパーティの登録(独立したサービスレジストラ)
独立したサービスレジストラは、登録とキャンセルを担当します。サービスが開始されると、Registrarは何らかの方法で通知を受け、Registrarはレジストリとの登録作業を開始する責任があります。同時に、登録センターはサービスとのハートビートを維持する必要があり、サービスが利用できない場合、サービスは登録センターにキャンセルされます。この方法の欠点は、Registrarが高可用性システムでなければならないことです。そうしないと、登録作業を進めることができません。
サードパーティの登録を以下に示します。
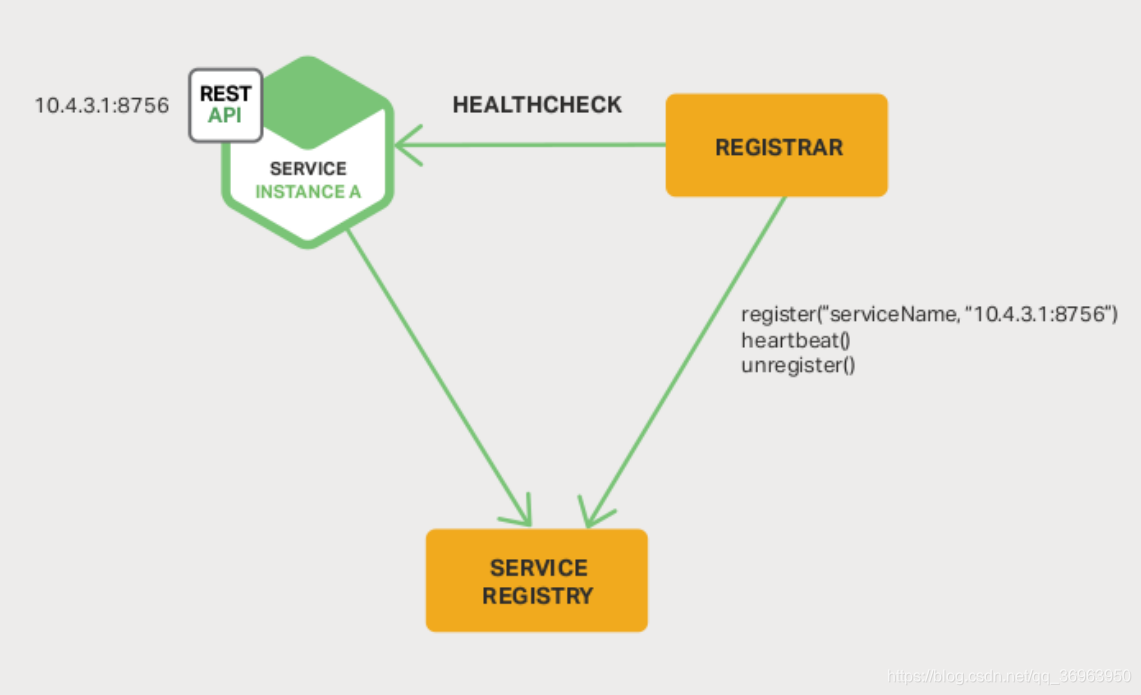
上の図の説明:
登録する必要のあるサービスSeviceは、独立したサードパーティのサービスレジストラーとやり取りします。サービスが開始されると、レジストラーは特定の方法で通知されます。この期間中、レジストラーは一定の時間にサービスServiceにハートビートチェックを送信します。
このように、サービスサービスは、追加の登録、追加のキャンセル、リアルタイムのハートビート通知サービス登録センターなしで、独自のビジネスロジックにアクセスできます。
独立したサービスレジストラーは、サービスレジスタサービスレジスタを直接処理します。2つの方法の間には、レジスタレジスタ()、ハートビート()、および登録解除/登録解除()の3つの方法があります。サービスが開始されると、Registrarは通知を受け、Registrarはサービスをサービス登録センターに登録します。サービスが開始された後、Registrarは定期的にサービスのハートビートチェックを実行します。サービスが残っている場合は、ハートビート()を呼び出してサービス登録センターに報告します。 unregsister()を呼び出して、サービス登録センターへのサービスをキャンセルします。
概要:サードパーティの登録では、独立したサービスであるRegistrarを使用して、登録サービスを登録センターから分離します。これは、低カップリングの設計概念に沿ったものです。もちろん、この方法では、クライアント登録と比較して、可用性の高い追加のRegistrarシステムが必要です。
クライアントディスカバリ
クライアントディスカバリは、クライアントが利用可能なサービスアドレスのクエリとロードバランシングを担当することを意味します。この方法は最も便利で直接的であり、ロードバランシングにも便利です。さらに、サービスが利用できないことが判明すると、すぐに別のサービスに変更されます。これは非常に簡単です。欠点は、複数の言語で作業が繰り返されることでもあり、各言語は同じロジックを実装します。
クライアントの検出を以下に示します。
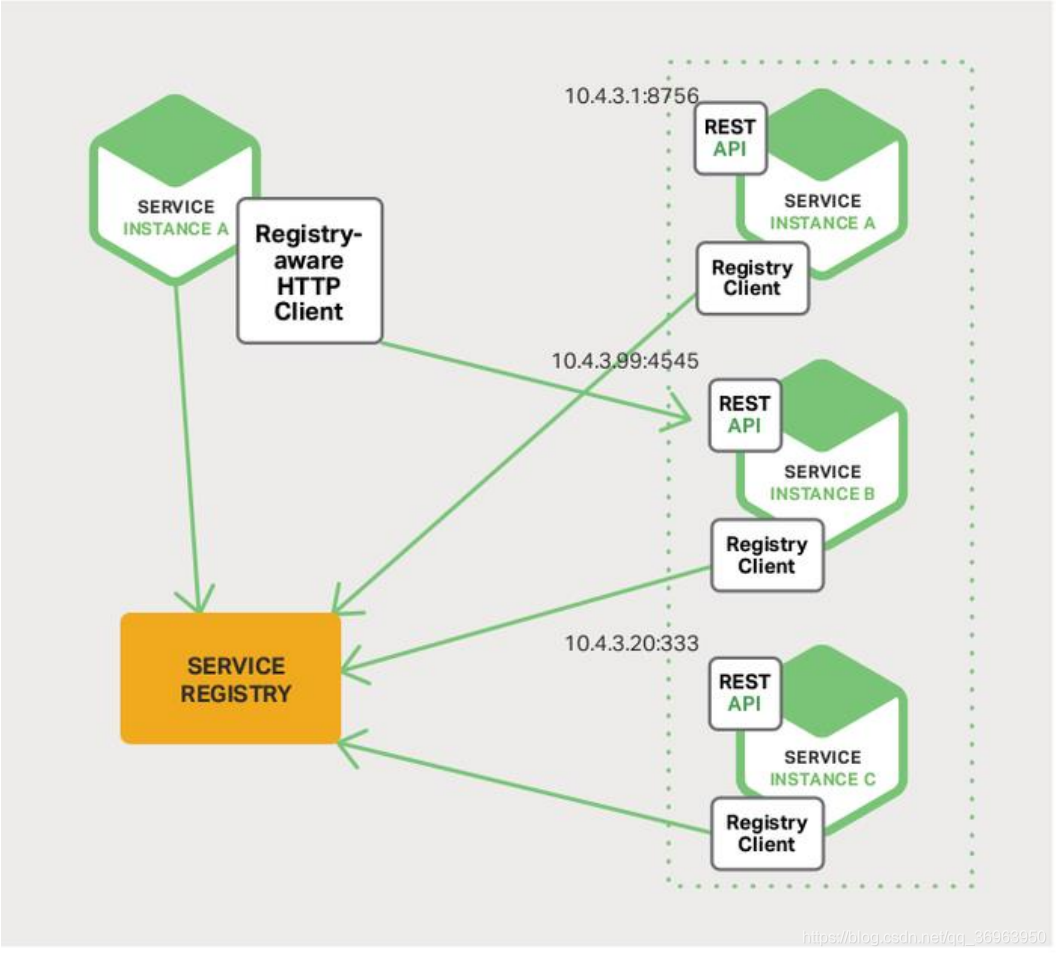
上の図の説明:
実行中のサービスSeviceはクライアントクライアントとして機能し、http要求を直接使用してサーバーを処理し、利用可能なサービスアドレスを直接クエリします。これは、負荷分散作業を行うために使用されます。このように設計は単純ですが、クライアントサービスとサーバーは結合されています。これは、低結合の設計概念を満たしていないため、サーバーの登録に依存しています。
サーバーの検出
サーバーの検出には追加のルーターサービスが必要です。要求は最初にルーターに送信され、次にルーターがサービスのクエリと負荷分散を担当します。この方法にはクライアントが発見した欠点はありませんが、ルーターの高可用性を保証するのが欠点です。
サーバーの検出を以下に示します。
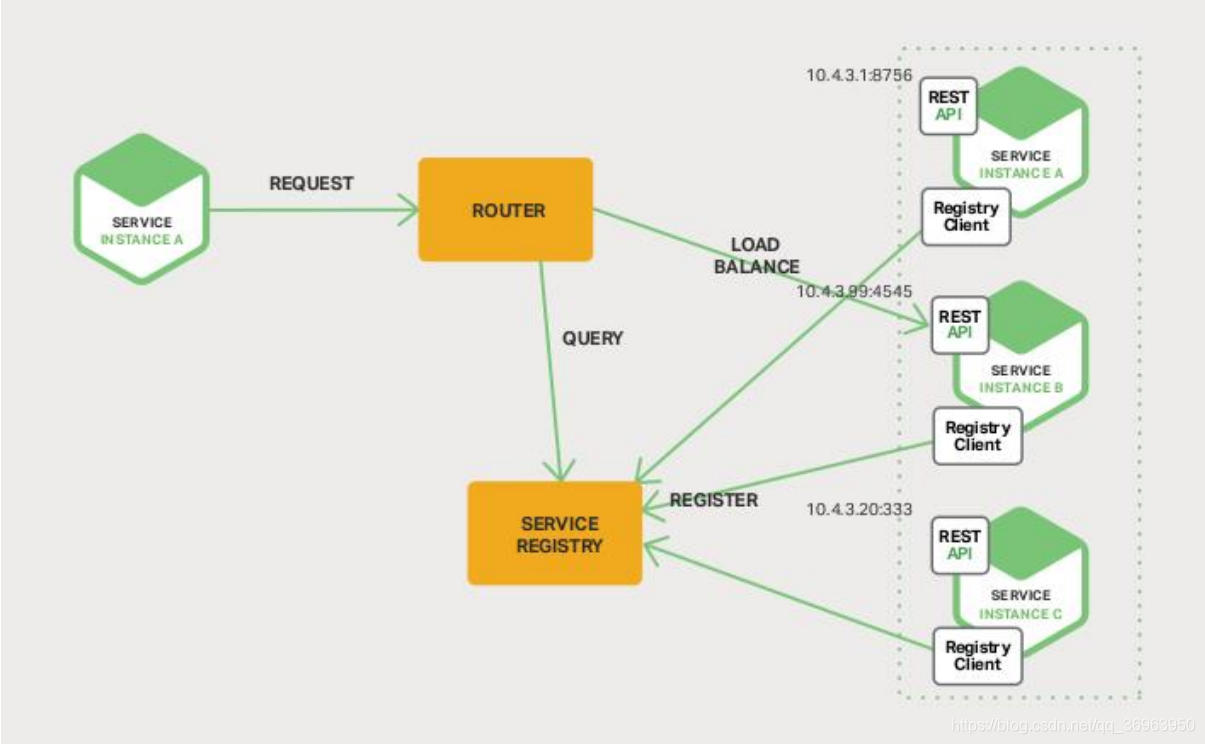
上の図の説明:
実行中のサービスSeviceはクライアントクライアントとして機能し、リクエストリクエストを使用してルーターと通信します。ルーターはサービスのクエリと負荷分散を担当し、サービスサービスはクエリサービスと負荷分散について質問しなくなりました。
概要:サーバー登録、クライアントクエリサーバーではなくルータークエリは、クライアントサービスの負担を軽減します。もちろん、この方法は、クライアント検出と比較して、追加の高可用性ルーターシステムを提供します。
質問2:「API Gateway / API Gateway」についてはどうですか?
回答2:
API Gatewayはサーバーであり、システムに入る唯一のノードとも言えます。これは、オブジェクト指向のデザインパターンのFacadeパターンに似ています。API Gatewayは内部システムアーキテクチャをカプセル化し、さまざまなクライアントにAPIを提供します。また、承認、監視、負荷分散、キャッシング、リクエストのシャーディングと管理、静的な応答処理など、他の機能も備えている場合があります。次の図は、現在のアーキテクチャに適応するAPIゲートウェイを示しています。
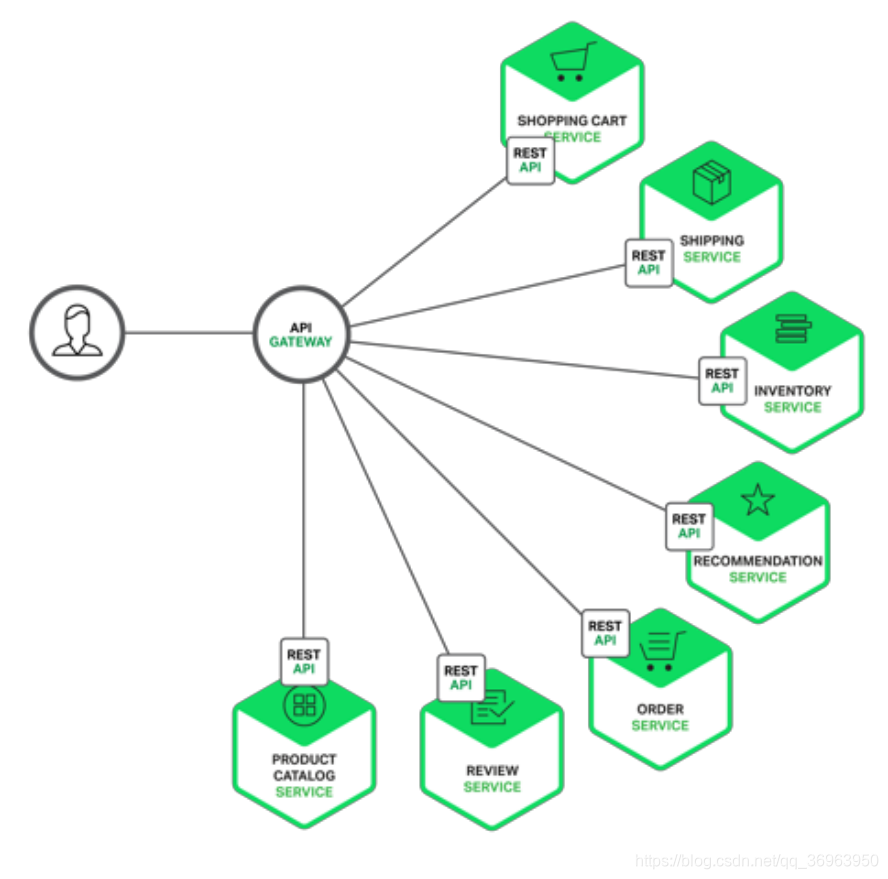
上の図は、APIゲートウェイが他のほぼすべてのビジネスモジュール、ショッピングカートサービス、ショッピングカートサービス、ショッピングサービスショッピングサービス、在庫サービス在庫リストサービス、推奨サービス推奨サービス、注文サービス注文サービス、レビューサービスレビューサービス、製品カタログを監視する必要があることを示していますサービス製品タイプサービス。
API Gatewayは、要求の転送、合成、およびプロトコル変換を担当します。クライアントからのすべてのリクエストは、最初にAPI Gatewayを経由してから、これらのリクエストを対応するマイクロサービスにルーティングする必要があります。API Gatewayは多くの場合、複数のマイクロサービスを呼び出してリクエストを処理し、複数のサービスの結果を集約します。Webプロトコルと、HTTPプロトコルやWebSocketプロトコルなど、内部で使用される非Webフレンドリープロトコルとの間で変換できます。
リクエストの転送
サービスの転送は、主に、マイクロサービスをインストールするクライアントのリクエストの負荷をさまざまなサービスに転送することです。
Response Merge
ビジネス内の複数のサービスインターフェイスを呼び出す必要がある作業を1つの呼び出しにマージして、外部サービスに統合サービスを提供します。
プロトコル変換
SOAP、JMS、およびREST間のプロトコル変換をサポートすることに重点が置かれています。
データ変換
は、XMLとJson(オプション)間のメッセージフォーマット変換機能のサポートに重点を置いています。
安全認証
- トークンベースのクライアントアクセス制御とセキュリティ戦略
- 送信データとメッセージの暗号化、サーバーへの復号化、クライアントに個別のSDKエージェントパッケージが必要
- HTTPSベースの送信暗号化、クライアントおよびサーバーのデジタル証明書のサポート
- OAuth2.0に基づくサービスセキュリティ認証(認証コード、クライアント、パスワードモードなど)
質問3:マイクロサービスアーキテクチャ構成センターを簡単に紹介しますか?
Answer3:
構成センターは、通常、システムのパラメーター構成として使用され、効率的な取得、リアルタイムの認識、分散アクセスなどの要件を満たす必要があります。
例:飼育係コンフィギュレーションセンター
によって実装されたアーキテクチャ図を以下に示します。データをメモリにロードする方法は、効率的な取得の問題を解決するために使用され、リアルタイムの知覚は、飼育係のノードモニタリングメカニズムを使用して実現されます。
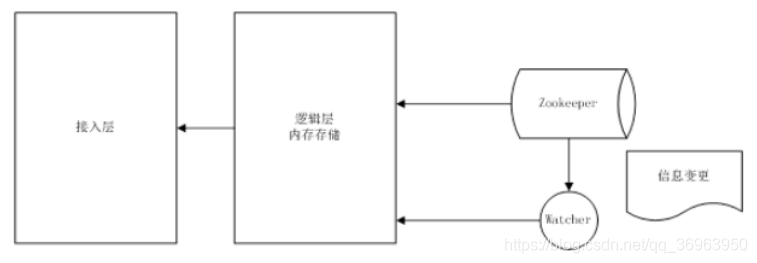
上の図は、Configuration CenterのZooKeeperがオブザーバーウォッチャーによる情報の変更を監視し、ビジネスロジックレイヤー、次にアクセスレイヤーに通知することを示しています。
構成センターのデータ分類
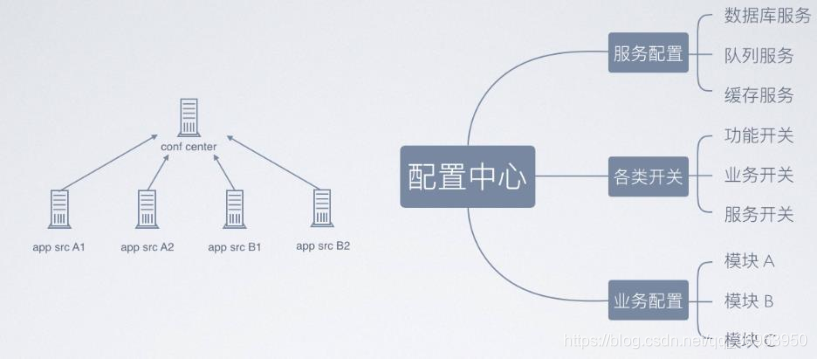
上の図は、構成センター(confセンター、フルネーム構成センター)に、サービス構成、さまざまなスイッチ、およびビジネス構成が含まれていることを示しています。
サービス構成には、データベースサービス構成、キューサービス構成、キャッシュサービス構成などが含まれます。
さまざまな種類のスイッチには、さまざまな機能スイッチ、さまざまな種類のビジネススイッチ、さまざまな種類のサービススイッチが含まれます。
上記のビジネス構成には、モジュールAアプリケーションsrc A(app src A1 + app src A2)、モジュールBアプリケーションsrc B(app src B1 + app src B2)など
質問4:イベントのスケジュール(カフカ)について簡単に説明してください。
Answer4:
メッセージサービスとイベントの統合スケジューリング。一般的に使用されるkafka、activemqなど。
質問5:サービス追跡の簡単な紹介(スタータースルース)?
回答5:
マイクロサービスの数が増え続けるにつれて、1つのマイクロサービスから次のマイクロサービスへのリクエストの伝播を追跡する必要があります。SpringCloudSleuthは、ログに一意のIDを導入してマイクロサービス呼び出し間の一貫性を確保することにより、この問題を解決しますセックス。これにより、マイクロサービス間でリクエストがどのように渡されるかを追跡できます。
- 要求追跡を実現するために、要求が分散システムの入口エンドポイントに送信されるとき、サービス追跡フレームワークのみが要求の一意の追跡識別子を作成する必要があり、フレームワークは分散システム内で循環するときに常に一意の識別子を渡し続けるリクエスタに返されるまで、この一意の識別子は前述のトレースIDです。トレースIDの記録により、すべてのリクエストプロセスログを関連付けることができます。
- 各処理ユニットの時間遅延をカウントするために、リクエストが各サービスコンポーネントに到達したとき、または処理ロジックが特定の状態に到達したときに、その開始、特定のプロセス、および終了も一意の識別子でマークされます。この識別子については、前回の記事で説明しています。各スパンについて、スパンIDには開始ノードと終了ノードの2つのノードが必要です。開始スパンと終了スパンのタイムスタンプを記録することにより、スパンの時間遅延をカウントできます。タイムスタンプレコードに加えて、イベント名、リクエスト情報など、他のメタデータを含めることもできます。
- クイックスタートの例では、spring-cloud-starter-sleuthコンポーネントの実装により、ログレベルの追跡情報アクセスを簡単に実装しました。Spring Bootアプリケーションでは、プロジェクトにspring-cloud-starter-sleuth依存関係を導入した後、次のような現在のアプリケーションの各通信チャネルの追跡メカニズムを自動的に構築します。
(1)RabbitMQ、KafkaなどのSpring Cloud Streamバインダーによって実装されたメッセージミドルウェア)。
(2)Zuulエージェントを通過したリクエスト。
(3)RestTemplateを介して開始されたリクエスト。
質問6:サービスヒューズ(Hystrix)とは何ですか?
回答6:
通常、マイクロサービスアーキテクチャには複数のサービスレイヤーコールがあります。基本サービスの障害により、カスケード障害が発生し、システム全体が使用できなくなる可能性があります。この現象は、サービス雪崩効果と呼ばれます。サービスなだれ効果は、「サービスプロバイダー」が利用できないために「サービスコンシューマー」が利用できなくなり、徐々に利用できなくなるプロセスです。
ヒューズの原理は、電力過負荷保護装置のように非常に簡単です。一定の時間内に同様のエラーを多数検出すると、その後の複数の呼び出しがすぐに失敗し、リモートサーバーにアクセスできなくなります。これにより、アプリケーションが失敗する可能性のある操作を継続的に実行しようとするのを防ぎます。 、アプリケーションがエラーの修正を待たずに実行を継続できるようにするか、長いタイムアウトを待つためにCPU時間を無駄にします。ヒューズを使用すると、アプリケーションはエラーが修正されたかどうかを診断することもできます。修正されている場合、アプリケーションは操作の呼び出しを再試行します。
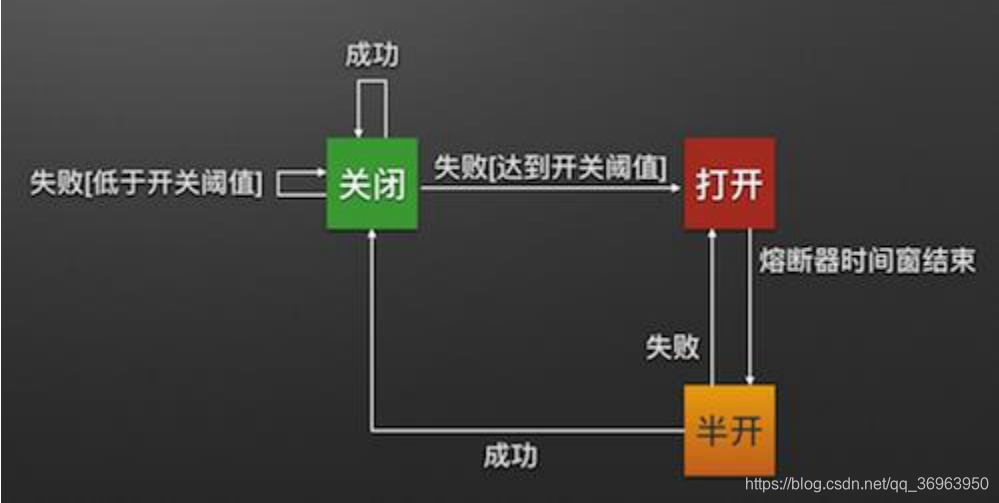
Hystrix回路ブレーカーのメカニズム
回路ブレーカーはよく理解されています。Hystrixコマンド要求のバックエンドサービス障害の数が特定のパーセンテージ(デフォルトは50%)を超えると、回路ブレーカーはオープン状態(Open)に切り替わります。このとき、すべての要求は直接失敗し、送信されません。バックエンドサービスへ。サーキットブレーカーが一定時間(デフォルトでは5秒)開いた状態に留まると、自動的にハーフオープン状態(HALF-OPEN)に切り替わります。このとき、次の要求の戻りステータスが判断されます。要求が成功すると、回路ブレーカーがオフになります。クローズ状態(CLOSED)に戻るか、そうでなければオープン状態(OPEN)に切り替えます。Hystrixのサーキットブレーカーは、ホームサーキットのヒューズのようなものです。バックエンドサービスが利用できなくなると、サーキットブレーカーはリクエストチェーンを直接切断して、無効なリクエストの大量送信を回避します。システムのスループットに影響し、回路ブレーカーは自己検出して回復する機能を備えています。
