HiveSqlの原理分析
HiveSQLの最下層は、デフォルトでMRプログラムに基づいて実行されます。HiveSQLの動作原理を分析する前に、SQL操作を実装するためのMRプログラムの基本原理を見てみましょう。
基本的なSQL操作を実装するMapReduceの原則
MRへの参加の実現原理
注文からu.name、o.orderidを選択oユーザーuに参加o ouid = u.uid;
異なるテーブルのデータをマップの出力値でマークし、reduceステージのタグに従ってデータソースを判断します。MapReduceのプロセスは次のとおりです。

MRでのグループバイの実現原理
ランク、isonlineによって都市グループからランク、isonline、カウント(*)を選択し、
GroupByフィールドをマップの出力キー値に結合し、MapReduceソートを使用し、LastKeyをreduceステージに保存してさまざまなキーを区別します。MapReduceのプロセスは次のとおりです(もちろん、これは、Reduce側の非ハッシュ集約プロセスを説明するためだけのものです)。

MRでの明確な実現原理
Dealidを選択し、dealidによって注文グループから(個別のuid)数を数えます。
別個のフィールドが1つしかない場合、MapステージでHash GroupByを考慮しない場合は、mapreduce ソートを使用して、GroupByフィールドとDistinctフィールドをマップ出力キーに結合するだけです。同時に、GroupByフィールドを削減キーとして使用し、LastKeyを削減フェーズで保存して、重複排除を完了します。次のSQLなどの

個別のフィールドが複数ある場合:
取引グループを選択して、取引IDごとに注文グループからカウント(個別のuid)、カウント(個別の日付)を選択します。
実装には2つの方法があります。
- 1)上記の個別フィールドの方法、つまり下の図に示す実装に従う場合は、uidと日付に従って個別にソートすることはできず、LastKeyによる重複排除はできません。それでも、reduceフェーズ中にメモリ内のハッシュによる重複排除を行う必要があります。
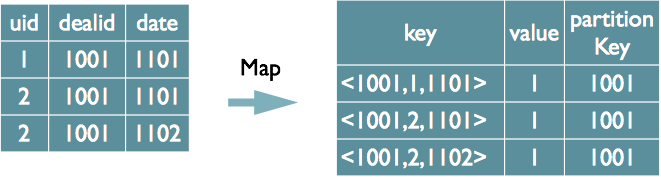
- 2)2番目の実装では、すべての個別のフィールドに番号を付けることができます。データの各行はn行のデータを生成し、同じフィールドが個別にソートされます。この場合、重複を削除するために、削減フェーズ中にLastKeyのみを記録する必要があります。
この実装はMapReduceの並べ替えをうまく利用して、reduceフェーズでの重複排除のメモリ消費を節約しますが、欠点はシャッフルデータの量が増えることです。
リデュース値を生成するとき、他の個別のデータ行の値フィールドは、最初の個別のフィールドが配置されている行を除いて、空である可能性があることに注意してください。

SQLをMapReduceに変換するプロセス
SQLを実装するためのMapReduceの基本的な操作を理解した後、HiveがSQLをMapReduceタスクに変換する方法を見てみましょう。コンパイルプロセス全体は6つの段階に分かれています。
- Antlrは、SQL文法規則を定義し、SQL字句解析、文法分析を完了し、SQLを抽象構文ツリーASTツリーに変換します
- ASTツリーをトラバースして、基本的なクエリユニットQueryBlockを抽象化します。
- 操作ツリーOperatorTreeに変換されたQueryBlockをトラバースします
- 論理レイヤーオプティマイザーは、OperatorTree変換を実行し、不要なReduceSinkOperatorをマージし、シャッフルデータの量を削減します
- OperatorTreeをトラバースし、MapReduceタスクに変換します
- 物理層オプティマイザはMapReduceタスクを変換して、最終的な実行計画を生成します
MapReduceへのSQL変換のプロセスを詳細に説明するために、例として単純なSQLを示します。SQLにはサブクエリが含まれ、最後にデータがテーブルに書き込まれます
FROM
(
SELECT
p.datekey datekey,
p.userid userid,
c.clienttype
FROM
detail.usersequence_client c
JOIN fact.orderpayment p ON p.orderid = c.orderid
JOIN default.user du ON du.userid = p.userid
WHERE p.datekey = 20131118
) base
INSERT OVERWRITE TABLE `test`.`customer_kpi`
SELECT
base.datekey,
base.clienttype,
count(distinct base.userid) buyer_count
GROUP BY base.datekey, base.clienttype
SQLで生成されたASTツリー
最終的に生成されたASTツリーを下の図の右側に示します(Antlr Worksを使用して生成され、Antlr WorksはAntlrが提供する文法ファイルを作成するためのエディターです)図はスケルトンのいくつかのノードのみを展開し、完全には展開していません。
サブクエリ1/2は、右側の最初の2つの部分に対応しています。

ここで、内部サブクエリもTOK_DESTINATIONノードを生成することに注意してください。上記のSelectStatementの文法規則を参照してください。このノードは、特に文法の書き換えで追加されたノードです。その理由は、HiveでクエリされたすべてのデータがHDFS一時ファイルに格納されるためです。中間サブクエリでも、クエリの最終結果でも、Insertステートメントは最終的に、テーブルが配置されているHDFSディレクトリにデータを書き込みます。
Hiveとmysqlの違い
類似点
HiveはSQLに似たクエリ言語HQL(hiveクエリ言語)を使用しています。動作言語は似ており、テーブルの作成、データベースの作成、基本的なチェックの追加、削除、変更を行います。
それ以外は基本的に類似点はありません。
違い
hqlの同様の構文に加えて、カーネル、ストレージの場所、それを更新できるかどうか、インデックスがあるかどうか、実行遅延、スケーラビリティ、およびデータサイズが異なります。
- Hiveはデータウェアハウス用に設計されています。
- 保存場所:HiveはHadoop上にあり、Mysqlはデバイスまたはローカルシステムにデータを保存します
- データの更新:Hiveはデータの再書き込みと追加をサポートしていません。ロード時に決定されます。データベースはCRUDにすることができます
- インデックス:インデックスなしのハイブ、毎回すべてのデータをスキャン、最下層はMR、並列計算、大量のデータに適しています; MySQLにはオンラインクエリデータに適したインデックスがあります
- 実行:Hiveの最下層はMapReduce、MySQLの最下層は実行エンジンです。
- スケーラビリティ:Hive:大量のデータ、スケーラビリティは非常に優れています; MySQL:比較的少ない
ため、Mysqlはオンラインビジネスを実行でき、Hiveはオフライン分析ビジネスしか実行できません。
参照:https://www.cnblogs.com/csguo/p/7553022.html
