1.実験目的
この実験では、2つの方法を使用して勾配降下アルゴリズムを実装し、パラメーターを出力して勾配降下プロセスを視覚化します。最初の方法はsklearnライブラリを利用する方法で、2番目の方法は手書きの勾配降下関数です。
データリンク
パスワード:faxo
2.勾配降下
2.1。sklearnライブラリの助けを借りて
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression #调用线性回归模型
def predict_using_sklearn():
df = pd.read_csv('test_scores.csv') #读取数据
model = LinearRegression() #实例化
model.fit(df[['math']],df.cs) #训练
return model.coef_, model.intercept_ #返回模型系数和截距
m_sklearn, b_sklearn = predict_using_sklearn() #调用函数
print("Using sklearn: Coef {} Intercept {}".format(m_sklearn,b_sklearn)) #打印模型系数和截距
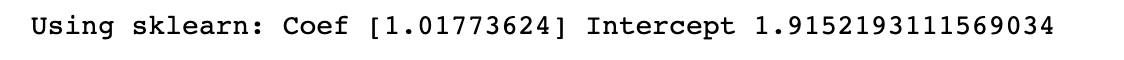
2.2。手書きの勾配降下関数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import math
def gradient_descent(x,y):
m_curr, b_curr = 0, 0 #初始化系数m、截距b
iterations = 100 #迭代次数
n = len(x) #数据总数
lr = 0.00001 #学习率
cost_previous = 0 #初始化损失
for i in range(iterations):
y_predicted = m_curr*x + b_curr #预测当前迭代的y
plt.plot(x,y_predicted,color='green') #打印预测直线
cost = (1/n)*sum([val**2 for val in (y-y_predicted)]) #计算当前迭代损失
dm = -(2/n)*sum(x*(y-y_predicted)) #求m的偏导数
db = -(2/n)*sum(y-y_predicted) #求b的偏导数
m_curr = m_curr - lr*dm #求当前m
b_curr = b_curr - lr*db #求当前b
if i==99:
plt.plot(x,y_predicted,color='red',linewidth=1) #画最后一次迭代预测直线
if math.isclose(cost,cost_previous,rel_tol=1e-20): #用于判断相邻两个迭代误差是否在容差范围内
break
cost_previous = cost
print ("m:{}|b:{}|cost:{}|iteration:{}".format(m_curr,b_curr,cost, i))
return m_curr, b_curr #返回最终m,b
df = pd.read_csv('test_scores.csv')
x = np.array(df.math)
y = np.array(df.cs)
m, b = gradient_descent(x, y)
print("Using sklearn: Coef: {} Intercept: {}".format(m,b))

実験中は、エラーをできるだけ小さくするためにパラメーター(反復数や学習率など)を継続的に調整し、最終的なモデルパラメーターとして比較的エラーの少ないハイパーパラメーターを選択する必要があります。
