Bツリーを理解する前に、Bツリーを簡単に紹介しましょう。
** Bツリー:**データベースデザイナー、ノードにデータを格納し、ツリーの形式でデータを格納し、ノードのサイズをページに設定します。取得に4つのアクセスが必要な場合、ノードの読み取りにはI / O操作が必要です。各ノード、ルートノードはメモリに常駐しているため、この取得を完了するには3つのioが必要です。
次に、データが小さいほど、各ページに格納されるデータが多くなり、ツリーの高さが低くなり、IOが少なくなり、検索が速くなります。
インデックスは上記のプロパティを使用し、B +ツリーとして設計されています。
** B +ツリー:**非リーフノードはキーのみを格納し、リーフノードはデータを格納し、リーフノードは隣接するリーフノードへのポインターを持ちます。
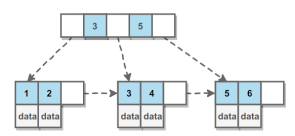
一方で、非リーフノードはより多くのレコードを格納でき、ツリーは短くなりますio一方、インターバルクエリのパフォーマンスは、シーケンシャルポインターを使用して改善できます。
MySQLは通常、インデックスとしてB +ツリーを使用しますが、クラスター化インデックスと非クラスター化インデックスによって実装が異なります。
-
クラスター化インデックス(主キーインデックスツリー)
いわゆるクラスター化インデックスは、B +ツリーのリーフノード上のデータを指し、データ自体がキーであり、キーが主キーです。一般的なインデックスの場合、データは対応するプライマリインデックスを指します。 -
非クラスター化インデックス(非主キーインデックスツリー)
非クラスター化インデックスは、B +ツリーのリーフノード上のデータを指します。データ自体ではなく、データが格納されているアドレスを指します。
非クラスター化インデックスには、クラスター化インデックスよりもデータを読み取るためのIO操作が1つ多いため、検索パフォーマンスが低下します。
主キーインデックスツリーのリーフノードは、直接クエリするデータの行全体だからです。主キーのインデックスではないリーフノードは、主キーの値です。主キーの値が見つかった後、主キーの値を介して別のクエリを実行する必要があります。このプロセスは、テーブルにコールバックされます。
