DDLステートメントの一般的に使用されるメソッド
はじめに
DML(データ操作言語)データ操作言語:データベースレコードのデータの整合性を追加、削除、変更、クエリ、およびチェックするために使用されます。一般的に使用されるキーワードは、挿入(挿入)、削除(削除)、更新(更新)、選択(クエリ)などです。
具体的な手順
レコードを挿入
INSERT INTO tablename(field1、field2、…、fieldn)VALUES(value1、value2、…、valuen);
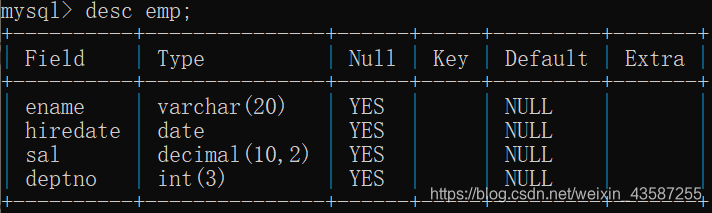
テーブルのフィールド:
たとえば、次のレコードをテーブルempに挿入します。enameはllw1、hiredateは2020-01-01、salは20000で、コマンドの実行は次のようになります。
mysql>insert into emp (ename, hiredate, sal, deptno) values('llw1', '2020-01-01', '20000', 1);
フィールド名を指定する必要はありませんが、値の順序はフィールドの順序と一致している必要があります。次に例を示します。
mysql>insert into emp values('lw', '2018-01-01', '30000', 2);
テーブルに「ename」フィールドと「sal」フィールドのみを明示的に挿入することもできます。
mysql>insert into emp (ename, sal) values('llw2', '20000');
結果は、
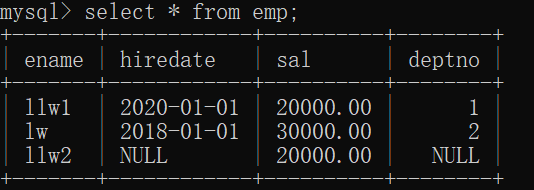
これらの書き込まれていないフィールドが自動的にデフォルト値のNULLに設定され、次の数値が増加することを示しています。これにより、SQLステートメントの複雑さを大幅に軽減できる場合があります。
一度に複数のアイテムを挿入する:
INSERT INTO tablename(field1、field2、…、fieldn)
VALUES
(record1_value1、record1_value2、…、record1_valuesn)、
(record2_value1、record2_value2、…、record2_valuesn)、
…
(recordn_value1、recordn_value2、…、recordn_valuesn);
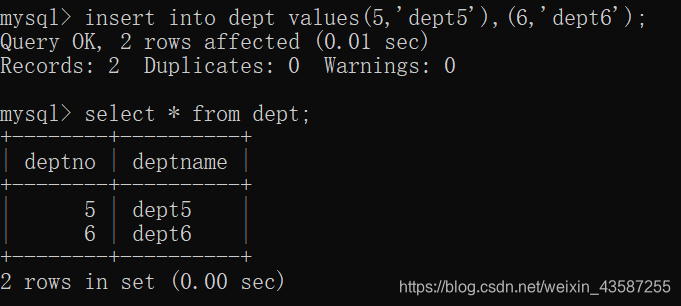
たとえば、次のとおりです。
mysql>insert into dept values(5,'dept5'),(6,'dept6');
結果は次のとおりです。
レコードを更新する
テーブルのレコード値はupdateコマンドで変更できます。構文は次のとおりです。
UPDATE tablename SET field1 = value1、field2。= value2、…、fieldn = valuen [WHERE CONDITION]
たとえば、テーブルempのename "llw1"の給与(sal)を20000から10000に変更します。
mysql> update emp set sal = 10000 where ename='llw1';
結果
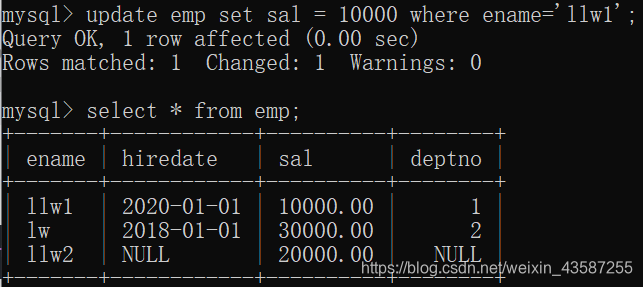
は次のとおりです。updateコマンドは、同時に複数のテーブルのデータも更新できます。構文は次のとおりです。
UPDATE t1、t2、…、tn set t1.field1 = expr1、tn.fieldn = exprn [WHERE CONDITION]
たとえば、次のとおりです。
mysql>update emp a,dept b set a.sal=a.sal*2, b.deptname=a.ename where a.deptno=2;
結果は次のとおりです。
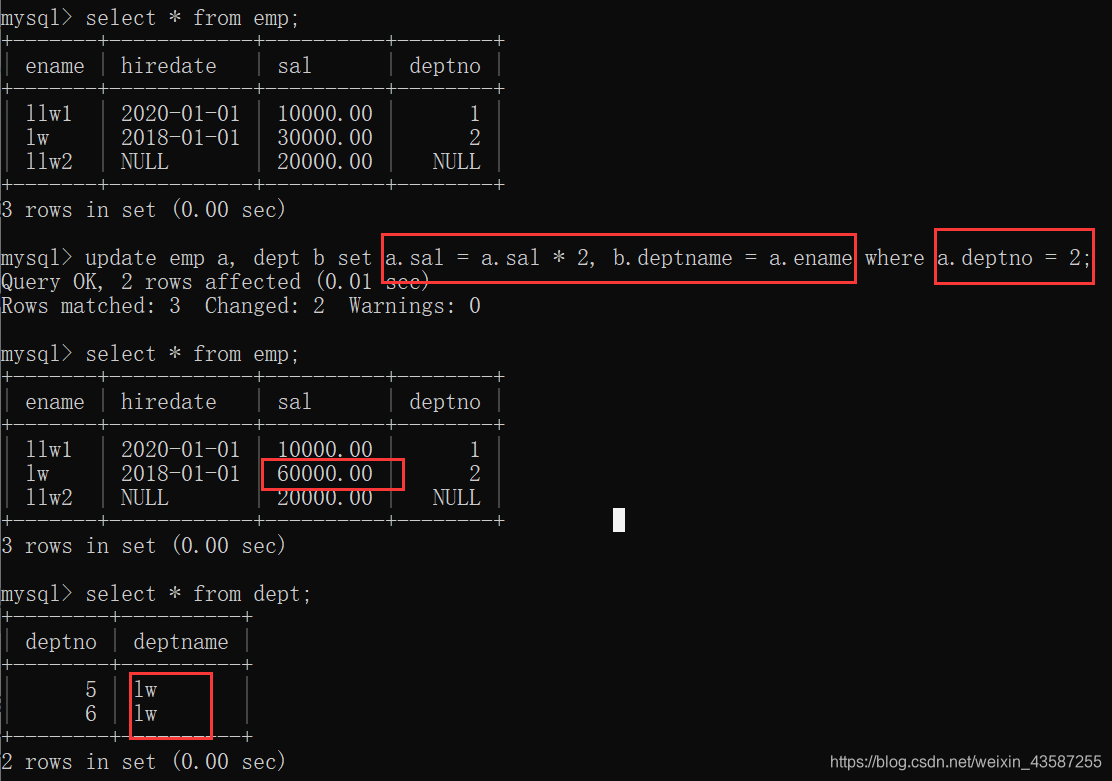
レコードを削除
レコードが不要になった場合は、deleteコマンドを使用して削除できます。構文は次のとおりです。
DELETE FROM tablename [WHERE CONDITION]
たとえば、次のとおりです。
mysql>delete from emp where ename='llw2';
MySQLでは、複数のテーブルから一度にデータを削除できます。構文は次のとおりです。
DELETE t1、t2、…、tn FROM t1、t2、…、tn [WHERE CONDITION]
mysql>delete a,b from emp a,dept b where a.deptno=2 and b.deptno=6;
結果は次のとおりです。
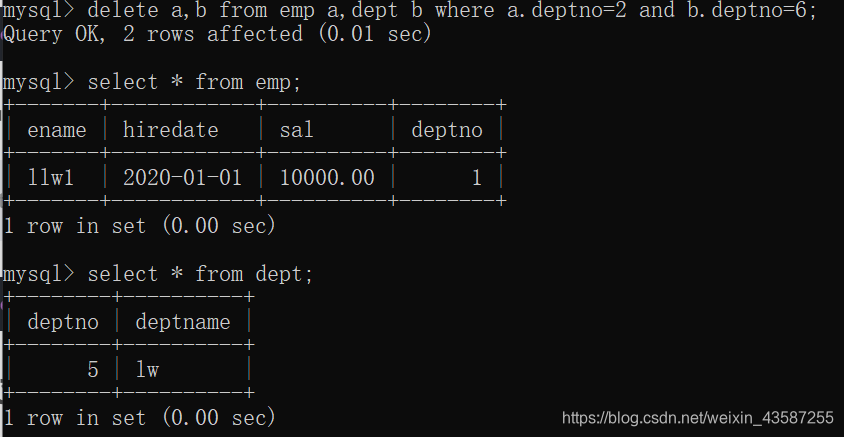
クエリレコード
SELECTの構文は非常に複雑です。ここでは、最も基本的な構文のみを紹介します。
SELECT * FROM tablename [WHERE CONDITION]
mysql>select * from emp;
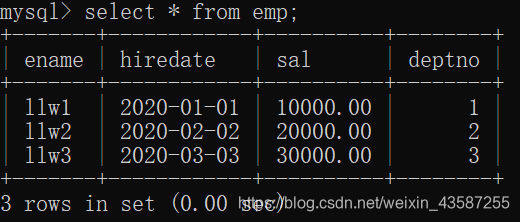
これは“*”すべてのレコードが表示されていることを示し、すべてのフィールドも代わりに使用することができるカンマ区切り、例えば:
mysql>select ename,hiredate,sal,deptno from emp;
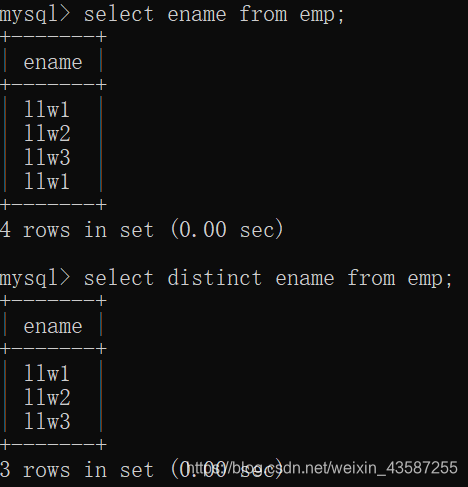
一意のレコードをクエリする
明確なキーワードを繰り返し記録は、例えば、なしに達成することができます。
mysql>select distinct ename from emp;
結果は次のとおりです。
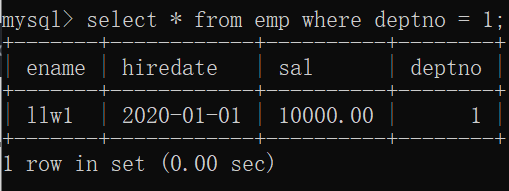
条件付きクエリ
「deptno」が「1」のレコードを表示します。
mysql>select * from emp where deptno = 1;
:結果は、
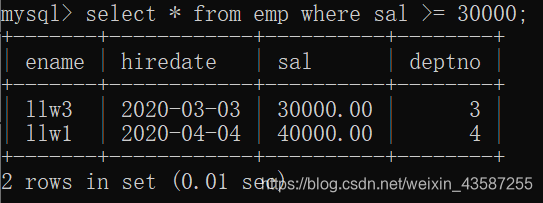
上記の例では、後者の条件は、に加えて、=フィールド比較である=を、も使用することができる>、<、> =、 <= 、!=、等の比較演算子は、複数の条件の中あってもよいですまたは、などの論理演算子を使用して、複数条件の共同クエリを実行します。
結果は次のとおりです。
並べ替えと制限
フィールドでソートした結果を表示したい場合は、キーワードorder byを使用して実現できます。構文は次のとおりです。
SELECT * FROM tablename [WHERE CONDITION] [ORDER BY field1 [DESC | ASC]、field2 [DESC | ASC]、…、fieldn [DESC | ASC]]
このうち、DESCとASCはソート順のキーワード、DESCはフィールドに従って降順、ASCは昇順を意味します。このキーワードを記述しない場合、デフォルトは昇順です。ORDER BYの後には複数の異なる並べ替えフィールドを続けることができ、各並べ替えフィールドは異なる並べ替え順序を持つことができます。
たとえば、次のとおりです。
mysql>select * from emp order by sal desc;
レコードはsalの降順で表示され、結果は次のようになります。
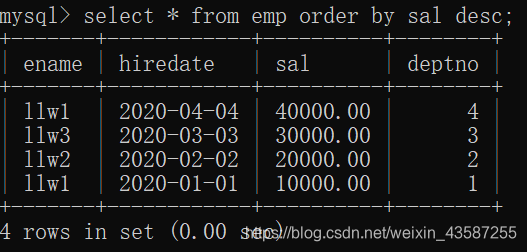
並べ替えフィールドの値が同じである場合、同じ値のフィールドは2番目の並べ替えフィールドに従って並べ替えられます。ソートフィールドが1つしかない場合、同じフィールドを持つレコードはランダムに配置されます。
レコードがソートされた後、レコードの一部のみを表示したい場合は、limitキーワードを使用して実現できます。構文は次のとおりです。
SELECT…[LIMIT offset_start、row_count]
たとえば、次のとおりです。
mysql>select * from emp order by sal desc limit 3;
最初の3つのレコードのみが
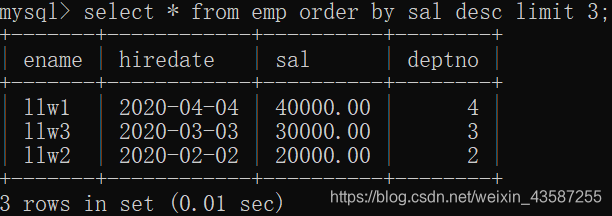
表示され、結果は次のようになります:m番目からn番目のレコードが表示されます。
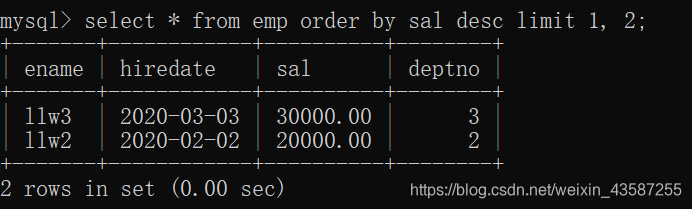
たとえば、レコード2から3を表示します。
mysql>select * from emp order by sal desc limit 1, 2;
結果は次のとおりです。
総計
多くの場合、ユーザーは会社全体の人数のカウントや各部門の人数のカウントなど、いくつかのサマリー操作を実行する必要があります。このとき、SQL集計操作が使用されます。
集計操作の構文は次のとおりです。
SELECT [field1、field2、…、fieldn]
fun_name FROM tablename
[WHERE here_contition]
[GROUP BY field1、field2、…、fieldn [WITH ROLLUP]]
[HAVING where_contition]
パラメータの次の説明:
fun_nameは、実行される集計操作、つまり集計関数を表します。一般的に使用されるのは、合計(合計)、カウント(*)(レコード数)、最大(最大値)、最小(最小値)です。
GROUP BYキーワードは、フィールドを分類して集計することを示します。たとえば、部門の分類に従って従業員数をカウントするには、部門をgroup byの後に記述します。
WITH ROLLUPは、分類集計後に結果を再集計するかどうかを示すオプションの構文です。
HAVINGキーワードは、分類された結果を条件付きでフィルタリングすることを意味します。
注:
whereとwhereの違いは、withingは集計結果の条件付きフィルタリングであり、whereは集計前にレコードをフィルタリングすることです。ロジックで可能な場合は、whereを使用して、結果セットが削減されるため、可能な限りレコードをフィルタリングします、集約の効率を大幅に向上させ、最後に、フィルタリングを使用して再フィルタリングするかどうかを確認するロジックに従います。
現在のテーブルのレコードは次のとおりです。
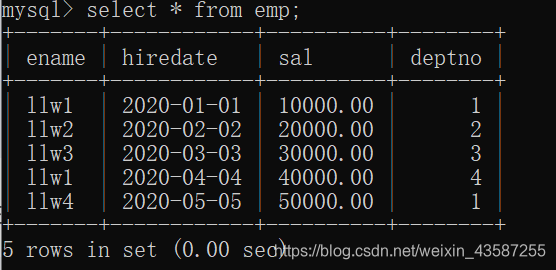
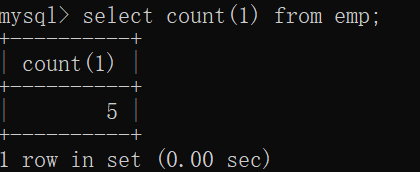
たとえば、empテーブルの会社の総数がカウントされます。
mysql>select count(1) from emp;
各部門の人数を数えます:
mysql>select deptno,count(1) from emp group by deptno;
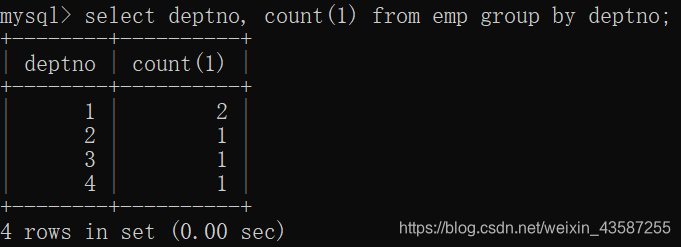
各部門の人数と総人数を数える必要があります:
mysql> select deptno, count(1) from emp group by deptno with rollup;
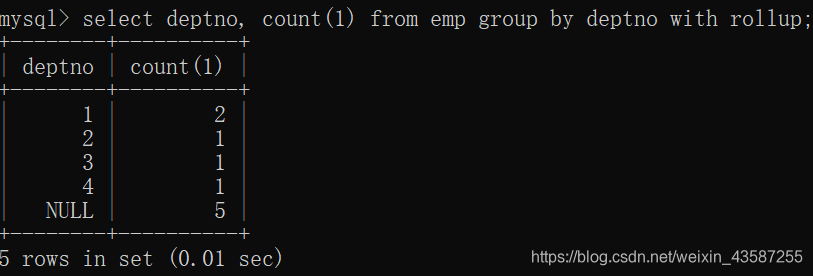
複数の統計を持つ部門:
mysql> select deptno,count(1) from emp group by deptno having count(1) > 1;

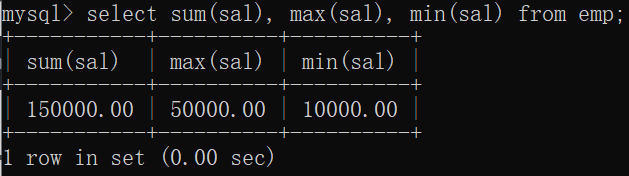
会社の全従業員の総給与、最高および最低給与を計算します。
mysql> select sum(sal), max(sal), min(sal) from emp;
テーブル接続
複数のテーブルのフィールドを同時に表示する必要がある場合は、テーブル接続を使用してこのような機能を実現できます。カテゴリに関しては、テーブル結合は内部結合と外部結合に分けられます。これらの主な違いは、内部結合は2つのテーブルで互いに一致するレコードのみを選択し、外部結合は他の一致しないレコードを選択することです。
現在のテーブルのレコードは次のとおりです
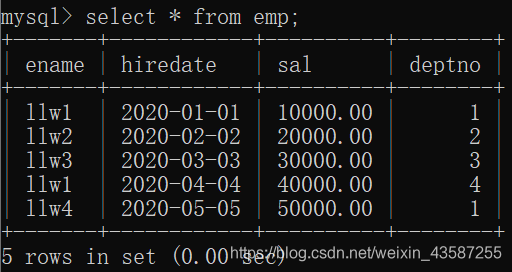
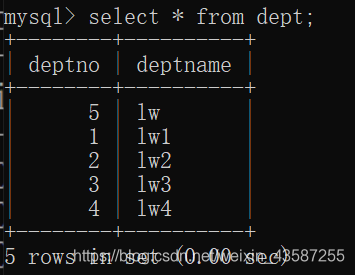
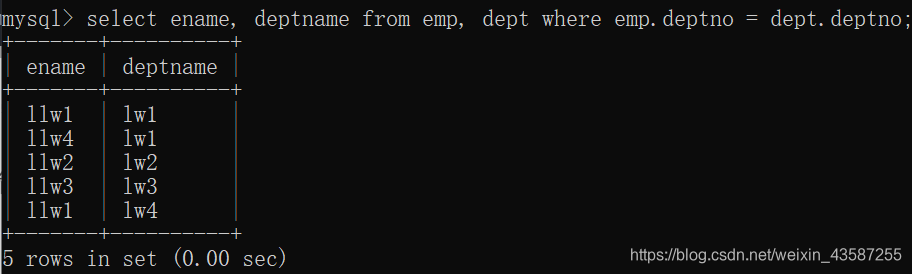
。最も一般的に使用されるのは内部接続です。たとえば、すべての従業員の名前と部門の名前をクエリします。
mysql> select ename, deptname from emp, dept where emp.deptno = dept.deptno;
外部接続は、左と右の接続に分けられ、次のように定義されます。
左結合:左のテーブルのすべてのレコードと、それに一致しない右のテーブルのレコードも含まれます。
右結合:右テーブルのすべてのレコード、および左テーブルのそれに一致しないレコードも含まれます。
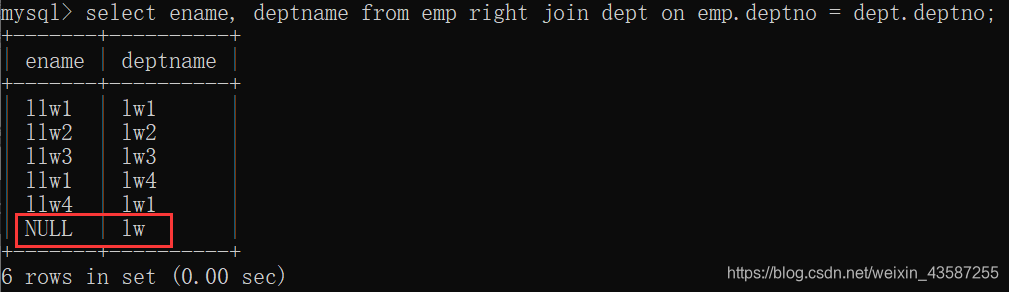
たとえば、dept内のすべての部門名と対応する従業員名を照会するには、次のようにします。
mysql> select ename, deptname from emp right join dept on emp.deptno = dept.deptno;
empレコードのどの従業員も「lw」部門に対応しておらず、結果は次のように表示されます。
サブクエリ
場合によっては、クエリを実行するときに、必要な条件が別のselectステートメントの結果である場合があります。このとき、サブクエリが使用されます。サブクエリに使用されるキーワードには、主に、in、not in、= 、! =、Exists、not existsなどがあります。
現在のempテーブルのすべてのレコード:
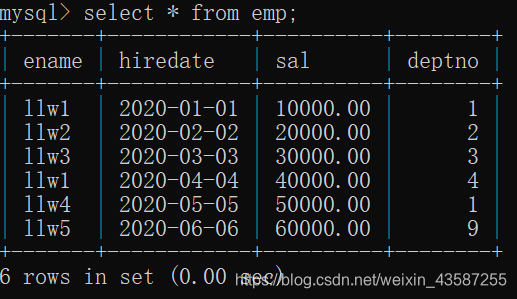
deptテーブルのレコード:
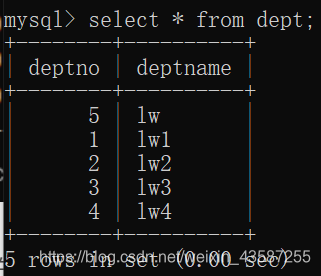
たとえば、empテーブルから、deptテーブルのすべての部門のすべてのレコードがクエリされます。
mysql> select * from emp where deptno in(select deptno from dept);
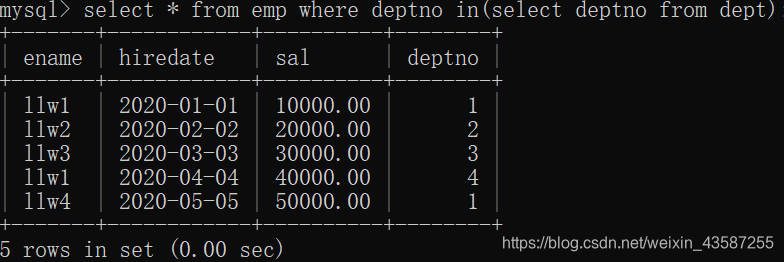
「llw5」が存在する部門は、deptテーブルにレコードがないため、表示されません。
サブクエリはテーブル結合に変換できます。たとえば、上記のステートメントはテーブル結合として表現できます。
mysql> select emp.* from emp ,dept where emp.deptno=dept.deptno;
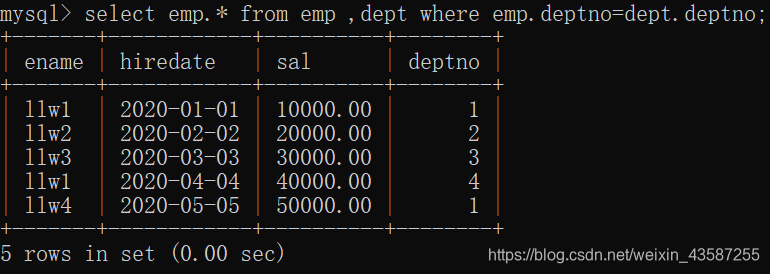
注:サブクエリとテーブル結合の間の変換は、主に2つの方法で使用されます。
4.1より前のMySQLバージョンはサブクエリをサポートしていません。サブクエリを実装するには、テーブル結合を使用する必要があります。
多くの場合、テーブル結合はサブクエリを最適化するために使用されます。
組合の記録
特定のクエリ条件に従って2つのテーブルのデータをクエリした後、結果がマージされて一緒に表示されます。このとき、このような関数を実現するには、unionおよびunion allキーワードを使用する必要があります。具体的な構文は次のとおりです:
SELECT * FROM t1
UNION | UNION ALL
SELECT * FROM t2
…
UNION | UNION ALL
SELECT * FROM tn;
UNION ALLとUNION ALLの主な違いは、UNION ALLが結果セットを直接マージし、UNIONがUNION ALLの後に結果のDISTINCTを実行して削除することです繰り返し録音後の結果。
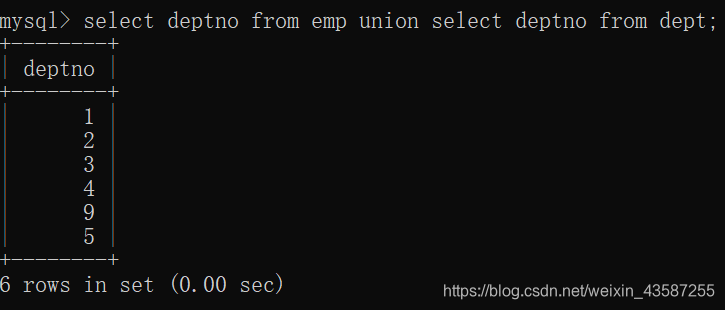
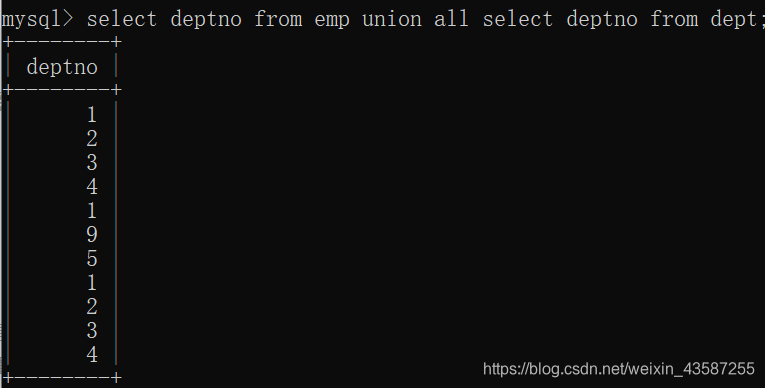
次の例を使用して、empテーブルとdeptテーブルに部門番号のセットを表示します。
mysql> select deptno from emp union all select deptno from dept;
結果は次のとおりです。
重複するレコードを削除します。
mysql> select deptno from emp union select deptno from dept;
結果は次のとおりです。