1.スパークの基本的な動作原理
主にメモリ
反復計算に基づいて分散
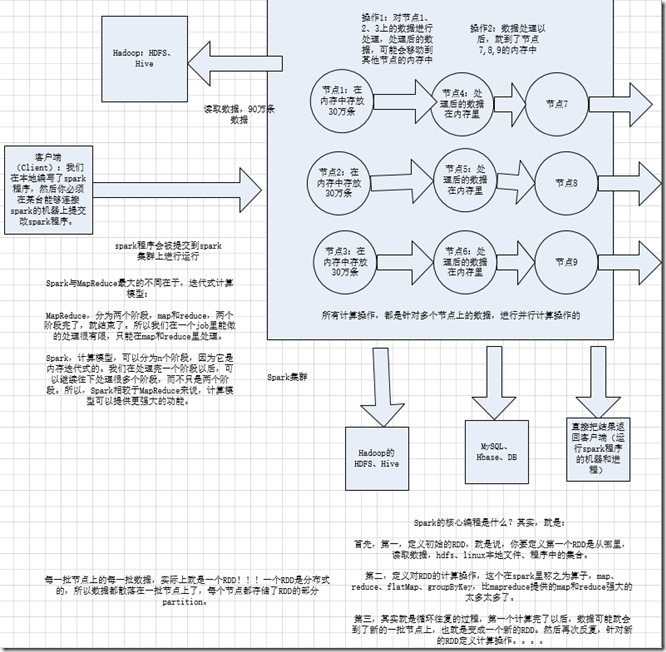
2.RDDとその特性
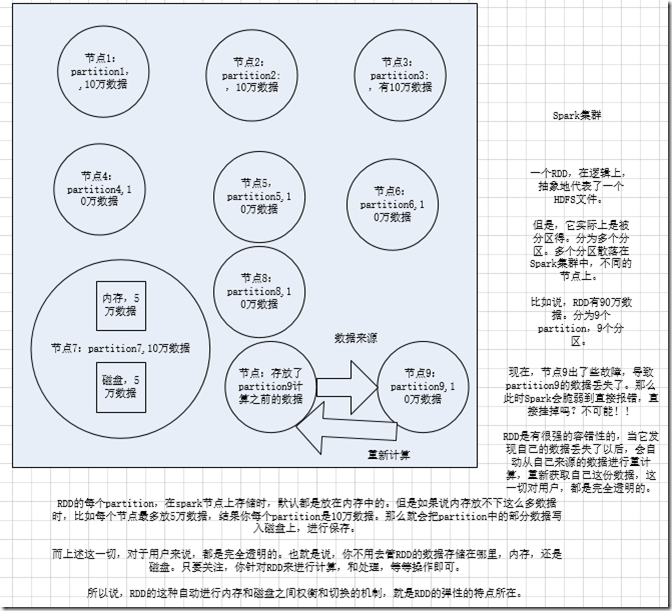
RDDは、抽象的にはデータを含む要素のコレクションです。これはパーティション化され、複数のパーティションに分割され、各パーティションはクラスター内の異なるノードに分散されるため、RDD内のデータを並行して操作できます。(分散データセット)
RDD の最も重要な機能は、フォールトトレランスを提供し、ノード障害から自動的に回復できることです。つまり、ノードの障害が原因でノード上のRDDパーティションが失われた場合、RDDは独自のデータソースを通じてパーティションを自動的に再計算します。これはすべてユーザーに対して透過的です。
RDDデータはデフォルトでメモリに保存されますが、メモリリソースが不十分な場合、Sparkは自動的にRDDデータをディスクに書き込みます。(柔軟性)
3.spark開発
a。コア開発:オフラインバッチ処理/インタラクティブデータ処理の遅延
b。SQLクエリ:最下層はRDDおよび計算操作
c。リアルタイム計算:下層はRDDおよび計算操作