衝突および溶液.Hash
オブジェクトに等しい()とhashCode()を実装する2つの方法がある前提のハッシュを、ハッシュコード()のその後の役割は、オブジェクトが一意のハッシュ値を返すことを保証することであるが、二つのオブジェクト計算値、としての衝突競合
溶液:
1.開口アドレス方式は、
公然と施行は、式:のHi =(H(キー) + DI)MOD MI = 1,2、...、K(K <= M-1)で
あり、mがハッシュテーブルの長いテーブル。紛争のディ増分シーケンス時間。値Diは1,2,3、...、M-1とすることができる場合、再ハッシュをプロービング線形言います。
1つのジ、各競合を、服用後後退位置が値1であってもよい場合であれば、ジ、-1,2、-2,4、-4,9、-9,16、-16、... K Kは、-k K(K <= M / 2)、二次プローブの再ハッシュ述べ。
ディ値は擬似乱数として挙げることができる場合。彼は、擬似ランダム再ハッシュを検出すると述べました。
そしてその後2をハッシュ
衝突が発生した場合に第二、第三、無競合までハッシュ関数計算アドレスを使用して、。デメリット:計算時間の増加。
例えば、初めてハッシュに従って姓の最初の文字上、競合が遠くなくなるまで競合は、姓の第二の手紙、次いで衝突、及び第三の最初の文字に応じてハッシュすることができれば
3.チェーンアドレス方式(方式ジッパー)
同じレコード同義語線形リストに保存されているすべてのキーワード。次のように:
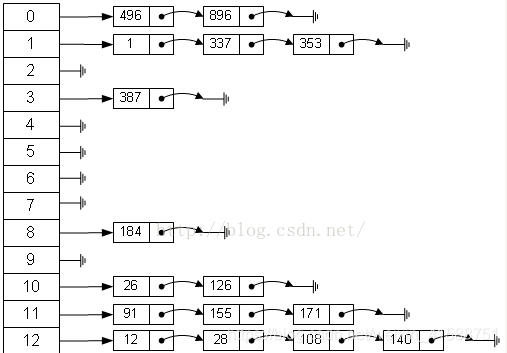
4は、共通オーバーフロー領域を確立する
ハッシュ関数は、範囲[0、M-1]は、ベクトルのハッシュテーブルを生成してみましょうとする[0 ... M-1]基本的な形態、追加の記憶空間ベクトルOverTable [0 ... Vの確立として]ストレージの競合を記録します。
方法ジッパー短所:
長所:
①簡単な方法ジッパー競合、無蓄積現象、すなわち、非同義決して衝突、平均検索長さより短いので、
②ファスナー方法ので、リストの空間上の各ノードは動的ですアプリケーション、それはより適切なテーブル長テーブルの状況を作る前に決定されていないので、
③オープン・アドレス指定衝突を減らす、α-充填率が小さいので、大きなノード・サイズは、多くのスペースを無駄にする時期が必要です。好ましくは、ファスナー方法α≥1、より大きなノード、ファスナー法ポインタフィールドを増加させるとこのようにスペースを節約する、ごくわずかである。
④ジッパー、削除ノード動作および実装が容易で、ハッシュテーブルを構築する方法。単にノードに対応するリストを削除します。ハッシュテーブルの構築の開口アドレス方式は、削除ノードは、単にそれが同義語・ノードのリストを散乱人々を埋めた後、それ以外の場合は、切り捨てパスを見ていきます、空きスペースにノードポイントを削除することはできません。オープンアドレス法は、空のアドレス位置(すなわち開口部アドレス)の様々な検索条件の失敗があるからです。そのため、オープンアドレス法で競合を処理バルクのリストの削除操作だけで削除されたノード上で削除のためにフラグを立てることができますが、できない本当に削除ノード。
短所:
ポインタは、追加のスペースを必要とするので、小規模ノードは、オープンアドレス指定方法がある場合に、より省スペース、およびポインタは、ハッシュテーブルのサイズを拡張するスペースを保存した場合順番にオープンを減少させる、因子が小さくなる充填することができコンフリクト・アドレス指定は、それによって平均検索速度を向上させることができます。
なぜ2 .HashMapは、スレッドセーフですか?
エントリは、ハッシュマップは、の使用である場合に、ハッシュ衝突が発生し、底HashMapのアレイであるリンクリスト、解決するためのアプローチの配列位置に対応するリンクされたリスト内の最初のノードを格納します。リストには、新しいノードがヘッドノードに参加します
1.ハッシュマップは、次のメソッドを呼び出します動作時間を置けばいい。
// 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K,V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小
if (size++ >= threshold)
resize(2 * table.length);
}
ハッシュマップは、運転中に入れない時には、上記メソッドの呼び出し。もし今スレッド後にAと2つのスレッドが今最初のノードを取得し、新しいヘッドAノードBはまた、新しいヘッドノードに書き込まれる書き込みする一方B addEntryは、同一の配列位置に同時に呼び出すスレッド、その書き込み操作がが失わA書き込み動作は、動作Bが上書きされます
コード2. Deleteキー
final Entry<K,V> removeEntryForKey(Object key) {
// 获取哈希值。若key为null,则哈希值为0;否则调用hash()进行计算
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
// 删除链表中“键为key”的元素
// 本质是“删除单向链表中的节点”
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
複数のスレッドが同時に同じアレイ位置を操作する場合だけでなく、現在の状態で第一の記憶場所の最初のノードを取得し、結果を行くアレイ位置に書き込まれた後、次いで、その後、実際には、ライトバックの各オペレーションを計算します他のスレッドがこの位置に置くように変更された可能性がありますとき、それは他のスレッドを修正カバーします。
次のようにコールの総数は、サイズ変更操作の閾値を超えた鍵の新しいキーと値のペアに組み込ま3.addEntry。
// 重新调整HashMap的大小,newCapacity是调整后的容量
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//如果就容量已经达到了最大值,则不能再扩容,直接返回
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 新建一个HashMap,将“旧HashMap”的全部元素添加到“新HashMap”中,
// 然后,将“新HashMap”赋值给“旧HashMap”。
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
このアクションは、すべてオリジナルの配列のキー値の、新しい容量の新しい配列を生成して再計算し、新しい配列を書き、その後、点の配列が新たに生成します。
複数のスレッドが同時に検出量が総閾値時間を同時にサイズ変更操作を呼び出し超え、各々が焼き直した後にアレイに割り当てられた新たな配列テーブルを生成する際に基本となる地図、新しいアレイの最後のスレッドの唯一の最終結果が生成されますテーブル変数に割り当てられ、他のスレッドが失われます。そして、いくつかのスレッドはほんの始まり割り当てと、他のスレッドが完了したとき、私たちはテーブルを使用しますが、元の配列として割り当てられているので、問題があるでしょう。
?三.concurrenthashmapスレッドセーフ達成するためにどのように
セグメント内部クラス、コードを見て定義するのConcurrentHashMapを:
//Segment继承了ReentrantLock重入锁(这个概念这次先不看)
static final class Segment<K,V> extends ReentrantLock implements Serializable {
//HashEntry与HashMap中类似,可以理解为一个单向链表元素,作为存放相同hash值,不同key的键值对,因为:ConcurrentHashMap通过数组形式存放多个Segment,用key的hash值做一次再hash,当做下标,识别当前键值对存放在segments数组中的哪个segment里。
//这样一个Segment就相当于一个HashMap
transient volatile HashEntry<K,V>[] table;
V put(K key, int hash, V value, boolean onlyIfAbsent) {
//在对Segment进行操作时,对当前对象Segment加锁
lock();
try {
//数据操作
} finally {
unlock();
}
}
}
他の現在のキーと値のペアは、セグメントに格納されているように再びキー識別子のハッシュのハッシュ値と次回を行うには、アレイを介して複数のセグメントを格納するのConcurrentHashMap。
final Segment<K,V>[] segments;
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
//用key的hashCode再做一次hash
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value, false);
}
ときにロック要素セグメントの操作なので、動作電流スレッドConcurrentHashMapのその他のオブジェクト、長いハッシュ値(ハッシュ(())key1.hashCode)ほどとKEY2の値(KEY1ハッシュ(key2.hashCode()をロックことを))異なる、あなたは直接他の要素のセグメントを操作することができます。
ConcurrentHashMapの16個のセグメントは、その理論的には、この時点では、限り、その操作が異なるセグメントに分散されているように、書き込みに16個の同時スレッドをサポートすることができます。この値は、他の値の初期化時に設定することができますが、初期化後は、それが拡張ではありません。
インタビューの質問:
なぜ文字列、Interger(パッケージ)のラッパー、このようなAクラスのキーとして?
A:文字列は不変であるため、最終的なもの、とequalsを書き換えた()とhashCode()メソッドを持っています。他のラッパークラスには、この機能を持っています
ハッシュマップ?の作品
のHashMapに基づくハッシュ原理は、私たちの店へのアプローチとは、スループットがオブジェクトを取得()とget()は。この方法は、我々は(置くために、キーと値のペアをお届けしますする場合)、それがキーオブジェクトのハッシュコードを計算するのhashCode()メソッドを呼び出して、オブジェクトの値を保存する場所を見つけるために、バケツをしましょう。正しいキー値を見つけるためにオブジェクトを取得する場合()メソッドは、オブジェクトがオブジェクトをキーに等しく、値を返します。衝突が発生したときの衝突の問題を解決するためのHashMap LinkedListの使用、オブジェクトは、LinkedListのノードに格納されます。HashMapのオブジェクトキーは各ノードのLinkedListに格納されています。
二つの異なるハッシュコードキーオブジェクトは、何が起こるか同じである場合には?これらは、バケットLinkedListの同じ場所に格納されています。キーオブジェクトのequals()メソッドは、ペアを見つけるために使用されます。
