開発の文字エンコーディング:
開発プロセスをコード文字:
フェーズ1:
コンピュータは数字のみを認識し、当社のすべてのデータは、制限のため、英語の看板を、コンピュータであることを示すために、図に基づいています
。各バイトは0〜127の間である0を使用する必要の最上位バイトので、数字は、例えば65に対応し、表現するために、対応97.
これは、情報交換-ASCII用米国標準コードです。
フェーズ2:
世界のコンピュータの人気が、多くの国や地域では、このような漢字として、コンピュータを導入した文字で自分自身を参照してください。
この場合、バイトはすべての漢字の後、規定を含むには小さすぎる数値の範囲を表すことがわかっ文字を表現するために2つのバイトを使用しています。
ことを提供する:オリジナルのASCII文字コードが変更されないまま、バイトを使用する2つのASCII文字と漢字を区別するために、
中国語の文字の最大の各バイト(バイナリ中国語が負である)1ビットとして定義される。本明細書はGB2312符号化、されて
以降、このような漢字などGB2312に基づいて、より漢字を加え、またGBK登場。
フェーズ3:
中国における新たな問題が中国語の文字を認識することであるが、他の国に渡された文字は、国コード表を文字に含まれていない場合、実際には、別の記号を表示したり、文字化け。
なぜならローカライズされた文字の様々な国を解決するためにコーディング、すべてのシンボルをコーディング統一。世界的-unicodeをコード化している入れによってもたらされる影響
この時点で、世界で一つの文字のどこかが固定され、このような「兄弟」として、進のどこかに基づいています54E5は表現するために作られた。
Unicode文字コードのサイズは2つのバイトを占めています。
一般的な文字セット:
ASCII:1バイトのみ128文字を含めることができますが、シンボルを表現することはできません。
ISO-8859-1:(ラテン-1):1バイト、西ヨーロッパ言語のコレクションは、漢字を表現することができません。..
ANSI: 。簡体字中国語オペレーティング・システムは、ANSI GB2312を指す2バイト、
GB2312 / GBK / GB18030:2バイト、中国の支持を
UTF-8:Unicode文字符号化のための可変長であります、それはUnicodeの実装の一つであり、ユニコードと呼ばれます。
最初のバイトを符号化することは、まだ必要はありませんか変更のみの小さな部分は、あなたが使用し続けることができ、元のASCII文字を扱うソフトウェアを作るASCIIと互換性があります。
したがって、それは徐々にエンコードされた電子メール、Webページや他の保存または送信されたテキストアプリケーション、優先順位の使用となっています。IETF(Internet Engineering Task Force)は、すべてのインターネットプロトコルはUTF-8エンコーディングをサポートするために必要とされる必要です。
UTF-8 BOM:MSは、デフォルトでは、コードの実行に従事され、3つのバイトが、これを使用しないでください。
文字、数字、文字の保存:
保存する文字と数字1つのバイトで何文字セットに関係なく。
ストレージ文字:家族GBK 2バイト、3バイトのUTF-8家族。
あなたは、単一のバイトを使用することはできません中国を格納するための文字セット(ASCII / ISO-8859-1)。
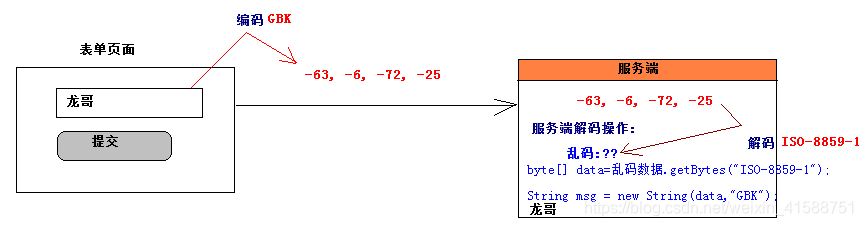
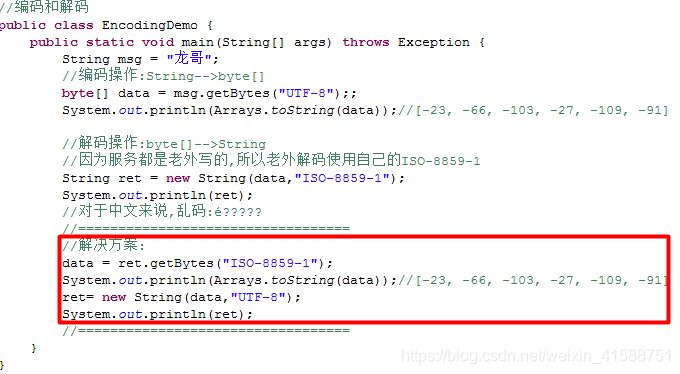
二つの文字エンコードとデコードの操作:
コード:バイト配列に文字列に変換
デコードを:文字列にバイト配列は、
同じエンコードとは、文字をデコードする、または文字化けしていることを確認する必要があります。
3つのツールを。
import java.io.UnsupportedEncodingException;
/**
* 字符编码工具类
*/
public class CharTools {
/**
* 转换编码 ISO-8859-1到GB2312
* @param text
* @return
*/
public static final String ISO2GB(String text) {
String result = "";
try {
result = new String(text.getBytes("ISO-8859-1"), "GB2312");
}
catch (UnsupportedEncodingException ex) {
result = ex.toString();
}
return result;
}
/**
* 转换编码 GB2312到ISO-8859-1
* @param text
* @return
*/
public static final String GB2ISO(String text) {
String result = "";
try {
result = new String(text.getBytes("GB2312"), "ISO-8859-1");
}
catch (UnsupportedEncodingException ex) {
ex.printStackTrace();
}
return result;
}
/**
* Utf8URL编码
* @param s
* @return
*/
public static final String Utf8URLencode(String text) {
StringBuffer result = new StringBuffer();
for (int i = 0; i < text.length(); i++) {
char c = text.charAt(i);
if (c >= 0 && c <= 255) {
result.append(c);
}else {
byte[] b = new byte[0];
try {
b = Character.toString(c).getBytes("UTF-8");
}catch (Exception ex) {
}
for (int j = 0; j < b.length; j++) {
int k = b[j];
if (k < 0) k += 256;
result.append("%" + Integer.toHexString(k).toUpperCase());
}
}
}
return result.toString();
}
/**
* Utf8URL解码
* @param text
* @return
*/
public static final String Utf8URLdecode(String text) {
String result = "";
int p = 0;
if (text!=null && text.length()>0){
text = text.toLowerCase();
p = text.indexOf("%e");
if (p == -1) return text;
while (p != -1) {
result += text.substring(0, p);
text = text.substring(p, text.length());
if (text == "" || text.length() < 9) return result;
result += CodeToWord(text.substring(0, 9));
text = text.substring(9, text.length());
p = text.indexOf("%e");
}
}
return result + text;
}
/**
* utf8URL编码转字符
* @param text
* @return
*/
private static final String CodeToWord(String text) {
String result;
if (Utf8codeCheck(text)) {
byte[] code = new byte[3];
code[0] = (byte) (Integer.parseInt(text.substring(1, 3), 16) - 256);
code[1] = (byte) (Integer.parseInt(text.substring(4, 6), 16) - 256);
code[2] = (byte) (Integer.parseInt(text.substring(7, 9), 16) - 256);
try {
result = new String(code, "UTF-8");
}catch (UnsupportedEncodingException ex) {
result = null;
}
}
else {
result = text;
}
return result;
}
/**
* 编码是否有效
* @param text
* @return
*/
private static final boolean Utf8codeCheck(String text){
String sign = "";
if (text.startsWith("%e"))
for (int i = 0, p = 0; p != -1; i++) {
p = text.indexOf("%", p);
if (p != -1)
p++;
sign += p;
}
return sign.equals("147-1");
}
/**
* 判断是否Utf8Url编码
* @param text
* @return
*/
public static final boolean isUtf8Url(String text) {
text = text.toLowerCase();
int p = text.indexOf("%");
if (p != -1 && text.length() - p > 9) {
text = text.substring(p, p + 9);
}
return Utf8codeCheck(text);
}
}
