分類モデル(分類器)は、ターゲット変数が離散的である教師機械学習モデル、(すなわちカテゴリ)です。機械学習モデルを評価し、モデルがちょうど重要ようです。私たちの目的は、堅牢なモデルを確立するために、そのため、新しい目に見えないデータ処理のためのモデルを確立することである、我々は、包括的かつ綿密な評価をモデル化する必要があります。それは分類モデルになると、評価プロセスは少しトリッキーになります。
この記事では、私は長所とモデルを評価するために使用されるさまざまな指標の一連の欠点を含め、分類器を評価する方法についての詳細な紹介を行います。
私はコンセプトをご紹介します含まれます:
-
分類精度(分類精度)
-
混同行列(混同行列)
-
精度とリコール(プレシジョン&リコール)
-
F1尺度(F1スコア)
-
感度と特異性(感度&特異性)
-
ROC曲線とAUC(ROC曲線とAUC)
分類精度(分類精度)
分類精度のショーは、我々が持っているか、どのくらいの予測が正しいです。
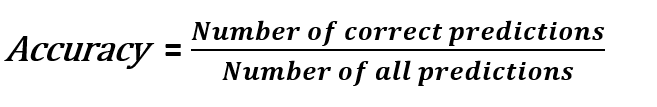
多くの場合、それはどのように良いパフォーマンスモデル示していますが、いくつかのケースでは、精度が十分ではありません。例えば、我々は正確に100のサンプル93を予測93%の手段の分類精度。以下の場合には許容されると思われる、タスクの詳細を知りません。
私たちは不均衡なデータセットのバイナリ分類を実行するためにモデルを作成していると仮定します。クラスAに属するデータの93%、およびクラスBに属する7%
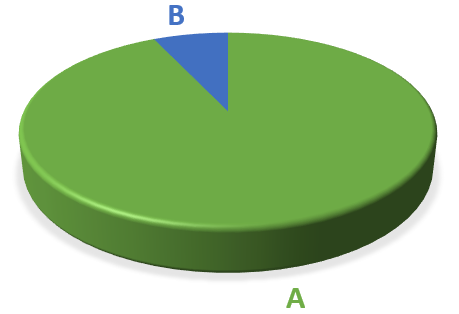
我々は唯一のサンプルAモデルクラスの見通しを持って、実際には、「モデル」それだけでクラスAを予測することができるので、推論のない計算はありません呼び出すことは困難です。サンプルの93%がクラスAに属しているので、我々のモデルの分類精度は93%です。
正しいクラスBの検出が重要な場合は、私たちは、クラスBに余裕がないことができ、誤ってクラスAのコストを予測する(例えば癌予測として、通常の結果として、癌患者の予測は考えられない)、実行する方法?これらのケースでは、我々は我々のモデルを評価するための他の指標を必要としています。
混同マトリックス(混乱マトリックス)
数値行列は、インデックスの評価モデルを混同されていないが、それは、私たちは深く理解している分類器の結果を予測することができます。精度と再現率が他の分類指標を理解することが非常に重要であるような、混同マトリックスをご覧ください。
私たちはモデルを評価するために道路上の道の深い一歩を踏み出した混同行列の手段を用いて、分類精度を比較しました。混同マトリックスショー各クラスの予測が正しいか間違っています。二値タスクの場合、混同行列は2×2行列です。3つの異なるクラスがある場合、それは、3×3の行列で、というように。
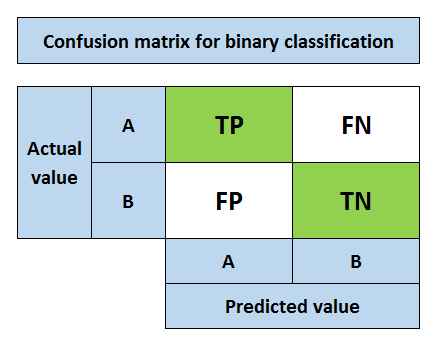
クラスは、n型、Bは次のようであると仮定する。次のように混同マトリックスは、主要な用語に関連付けられています:
-
真陽性(TP):正のクラス(問題なし)のためのポジティブ・クラスの予測
-
偽陽性(FP):負のクラス予測が正カテゴリ(悪い)であります
-
偽陰性(FN):正のクラス予測はマイナスカテゴリ(悪い)であります
-
真のネガティブ(TN):負のクラス予測は陰性クラス(問題なし)であります
私たちは、その結果は、我々は予測に真のカテゴリを一致させることができますということであると思います。これらの用語は、めまい、一部の人々に表示されますが、あなたはそれらを覚えているのに役立ついくつかのヒントをすることもできます。次のように私のトリックは、次のとおりです。
第2のワードは、予測モデルの結果を表します
最初の単語表現モデルの予測が正しいですか
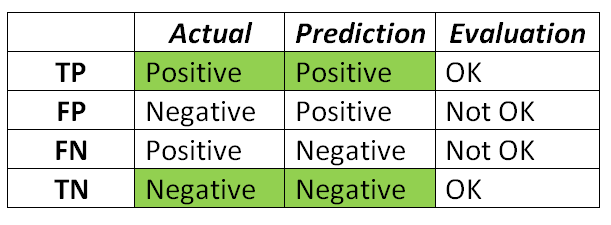
また、また、偽陰性タイプIIエラーとして知られているタイプIエラーとして知られている偽陽性、。
混同行列は、精度と再現率を計算することで使用してください。
記事全文は、オリジナルまたは社会的関心号を参照してください。
オリジナル住所:https://imba.deephub.ai/p/a5768cf073bb11ea90cd05de3860c663
