高可用性のHadoopクラスタのセットアップ
高可用性クラスタを構築し、8つのプロファイルを関与させる必要性
1.zookepperは、ファイルディレクトリをMYIDノードzkdata
zoo.cfgファイルディレクトリノード2.zookepper zkdata下
など/ディレクトリの下/ 3.hadoopインストールディレクトリ内のHadoop hadoop-env.sh
インストールディレクトリの下に4.hadoopなど/ Hadoopの/ディレクトリの下にあるコア- site.xmlの
5.hadoop HDFS-site.xmlのインストールディレクトリにあるなど/ Hadoopの下に/ディレクトリの
下に/ディレクトリなど/のHadoop 6.hadoopのインストールディレクトリにあるスレーブが
インストール7.hadoop糸-site.xmlの/ディレクトリ内など/ Hadoopのディレクトリの
下に/ディレクトリ8.hadoop mapred-site.xmlのインストールディレクトリにあるなど/ Hadoopの
`集群策略:
zk 1 、2 、3为 zookapper
hadoop4、5为 namenode
hadoop6、7为``resourcemanager
hadoop 8、9 、10为 namdnode 、journalnode 以及 nodemanager
クラスタセットアップアイデアやプロファイルの詳細
zookepperのクラスタの設定
目的:(、少なくとも3奇数)クラスタ環境で自動フェイルオーバーを確実にするために
①myid
1
上のシステムを作成zkdata MYIDという名前のファイルに触れるするファイルのディレクトリ、
それぞれが独自のアイデンティティを持っているZK確保するために。
②zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/root/zkdata
clientPort=3001
server.1=主机名:3002:3003
server.2=主机名:4002:4003
server.3=主机名:5002:5003
内容上、CFGファイルに示すように、zkdataファイルディレクトリの動物園を作成します。
DATADIRファイルディレクトリ
CLIENTPORT 3001ポートZKサーバ(クライアント・プロセスのポート)
3002:データのアトミックブロードキャスト内部ポート
3003:選挙トレラントポート用の内部
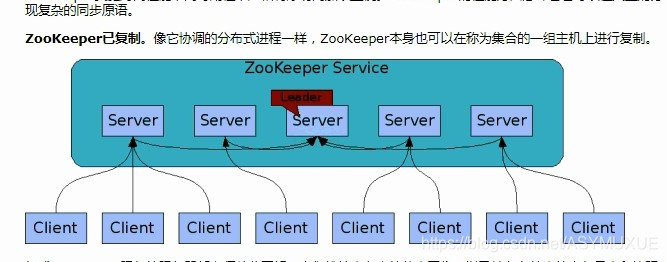
原子がブロードキャスト:仲間のサーバーのいずれかの中で、クライアントからの要求を書くことすべてのサーバ間の同期。
これまでのところ、zookepperクラスタの準備作業が完了しました。
ZKクラスタコマンド:
インストールディレクトリ下のbinディレクトリに実行ZK
./zkServer.shスタート/root/zkdata/zoo.cfg(スタート)
./zkServer.sh状態/root/zkdata1/zoo.cfg(ビューステータス)
クラスタHDFSアップ2セット
前の作品:
:静的IPアドレス変更vim /etc/sysconfig/network-script/ifcfg-ens37
ホスト名:vim /etc/hostname
IPマッピング:vim /etc/hosts
SSHの構成フリー密集ログイン:ssh-keygen -t rsa(生成した秘密鍵)、 ssh-copy-id 主机名(分散秘密鍵)
③hadoop-env.sh
環境変数JDK目的を変更します。環境変数が無効なリモートアクセスを、リモートアクセスを確保するために、正常に動作することができます。
export JAVA_HOME=/自己的安装目录
④core-site.xmlに
Hadoopのコア・コンフィギュレーション・ファイル
<!-- 高可用集群的配置 -->
<!-- 文件系统的入口 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!-- 文件系统的目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-2.9.2/data</value>
</property>
<!-- ZK系统的IP及Port -->
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1:3001,zk2:4001,zk3:5001</value>
</property>
代わりに、NS *** ***それはクラスタなので、エントリがカスタム名にファイル・システムを指定していないので。
⑤hdfs-site.xmlに
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop4:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop4:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop5:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop5:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop8:8485;hadoop9:8485;hadoop10:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,如果ssh是默认22端口,value直接写sshfence即可 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 可视化界面可写操作 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
⑥slaves
hadoop8
hadoop9
hadoop10
データノードとしてノードマネージャとの両方3つのホストの構成。
⑦yarn-site.xmlに
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop24</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop25</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop6:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop7:8088</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zk:3001,zk:4001,zk:5001</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
⑧mapred-site.xmlに
<!--配置计算框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--配置历史服务器的TCP端口-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop10:10020</value>
</property>
<!--配置历史服务器的web端口-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop10:19888</value>
</property>
注:なしmapred-site.xmlファイルの下のデフォルトのディレクトリのHadoopので。手動でコピーする必要があるので、次のコマンドを実行します。
cp hadoop-2.9.2/etc/hadoop/mapred-site.xml.template hadoop-2.9.2/etc/hadoop/mapred-site.xml
文書を作成することができますMapred
クラスタ構成を構築するために、これまでに完了しています
3. [スタート]高可用性クラスタのHadoop
コマンド(シーケンシャル)
☆☆☆☆ yum install psmisc -y(すべてのノードが依存centos7.xクラスタ構造を設置しました)
☆☆☆☆ hdfs zkfc -formatZK(ZKをフォーマット、任意の名前ノード上で実行)
☆☆☆☆ hadoop-daemon.sh start journalnode(すべてjournalNodeノードで開始し、実行)
最初のスタートjournalNodeは、データの同期を確実にするために、前にフォーマット名前ノード(自身のデータ)を保証することです。
☆☆☆☆ hdfs namenode -format ns(名前ノードのアクティブ[選択]を実行開始)
☆☆☆☆ start-dfs.sh(HDFSファイルシステムを起動します)
☆☆☆☆ hdfs namenode -bootstrapStandby(名前ノードの待機フォーマット)
☆☆☆☆ hadoop-daemon.sh start namenode(名前ノード待機ノードの開始)
☆☆☆☆ start-yarn.sh(実行上のアクティブノードはresourcesNodeのヤーン[選択]を開始します)
☆☆☆☆ yarn-daemon.sh start resourcemanager(resourcesManagerスタンバイノードの開始)
4.テストクラスタ
アクセス
ip:50070、ファイルシステムのWebインターフェースHDFS
ip:8088ヤーン糸resourcesManager Webインターフェイス
その他のコマンド:
☆☆☆☆ mr-jobhistory-daemon.sh start histroyserver(履歴サーバを起動します)
☆☆☆☆ hadoop jar 包名(JARパッケージを実行している、仕事の作業を行います)
ip:19888 歴史ServerのWebインターフェイス
