I.背景
MySQLでは、ほとんどすべてのデータテーブルは主キーを持つことになり、マスターキーは、各データテーブルのIDが同じではない、繰り返すように許可されていません。
ID主キーは、数、または文字列であり、一般的に主キーIDとして番号を選択し、数値型、テーブルを作成するには、int型、長い、フロート、ダブルこれらのカテゴリ(細分化)に分けることができますデータ型は、データの見込額に基づいて選択されるとき。
新しいレコードを挿入するときに、プライマリ数字キーのこのタイプの、2つのオプションがあります:1、IDインクリメント、データ挿入、IDフィールドは無視される(またはセットヌル、自動的にインクリメントIDに); 2を、データ挿入場合、IDの値を手動で指定。二つの方法は長所と短所があります。
II。インクリメントの主キーのID長所と短所
:長所と短所は、オンラインのブログを参照することができますhttps://www.jianshu.com/p/f5d87ceac754
さておき、上記のブログ記事の欠点にもかかわらず、(これまでのところ、私はこのような問題が発生していないので)、私は通常より多くの問題を抱えている、これは以下の通りであります:
1は、データが複数のシステムを共有することになり、そこにあります。
図2に示すように、データが生成される場合、関連するすべてのシステムは、データ・レコードを見つけるための識別(ID)に基づくことができます。
データ保存後の主キーのID(インクリメント)があるので、あなたは、その後、私はデータうち、主キーIDチェックが含まれ、その後、他のシステムに分散データ生成後、私は最初のストレージに入れ、と思うかもしれないので、すべてのシステム、方法あなたは、このデータのIDを知ることができます。
しかし、問題は、ストレージは、データのどれを見つけるためにどのようにあなたの前に、保存した後、ここにあるのでしょうか?多くの場合、唯一の方法を行うには、データのみの主キーのこの時期に署名しますか?データの正確な部分を検索する方法、特に高周波を挿入する場合は特に?それはほとんど不可能です!ない限り、データの挿入時に、IDを指定します。
III。Idは、手動でプライマリキーの長所と短所を指定します
手動ID(インクリメントせずID)の主重要な利点は、上記の問題を解決することができ指定。
明らかな欠点は、周波数に挿入された競合しやすい主キーIDは、特定のレベルに達すると、この問題が発生すると、記憶データの消失をもたらす、失敗し、そのような多くの問題が存在することになるで(アプリケーションレベルの例外処理をするために行うことができます回避のデータの損失)。
実際には、我々は右のみ、重複する主キーのID OKの問題を解決する必要があります。
それでは、どのメイン生成重複する主キーIDはいますか?特に分散型アーキテクチャの現在の有病率で、異なるノードから生成された大量のデータは、どのようにこれが問題であり、データの各部分が固有のIDを割り当てることができることを確実にします。
様々なアルゴリズムは、いくつかのミドルウェア、RedisのとZKがあり、そのようなUUID、雪片アルゴリズムとして、既に存在するにも、独自のユニークなIDの生成アルゴリズムを持っています。
あなたはを参照できます。
四。UUIDアルゴリズム
アルゴリズムはUUID導入について、Baiduの百科事典を参照してください。https://baike.baidu.com/item/UUID
(java.util.UUID)は、Java UUIDツールでは、進ストリング128ビット(32バイト)を生成してもよい、4「 - 」進列部5、ルールに分割します4ab1416b-CAFC-4932-b052-cd963aff22eb:8-4-4-4-12は、36の合計、各セクションは、以下のような特別な意味を有しています。
次に例を示します。
java.util.UUIDインポート;
publicクラスUuidDemo {
パブリック静的無効メイン(文字列[] args){
最終UUID.randomUUID UUID = UUID();
のSystem.out.println(UUID);
// 4ab1416b-CAFC-4932-B052 -cd963aff22eb
//合計128ビット(32バイト)を加えた4 -セパレータ、36のルールの合計8-4-4-4-12あります
}
}
ファイブ。スノーフレークアルゴリズム
オープンソースさえずりスノーフレークは、グローバルにユニークなIDを生成することができますアルゴリズムです。
IDは64ビットによって生成され、図に示すように4つの64ビットの部分に分けることができ、各部分は、特別な意味を持ちます。
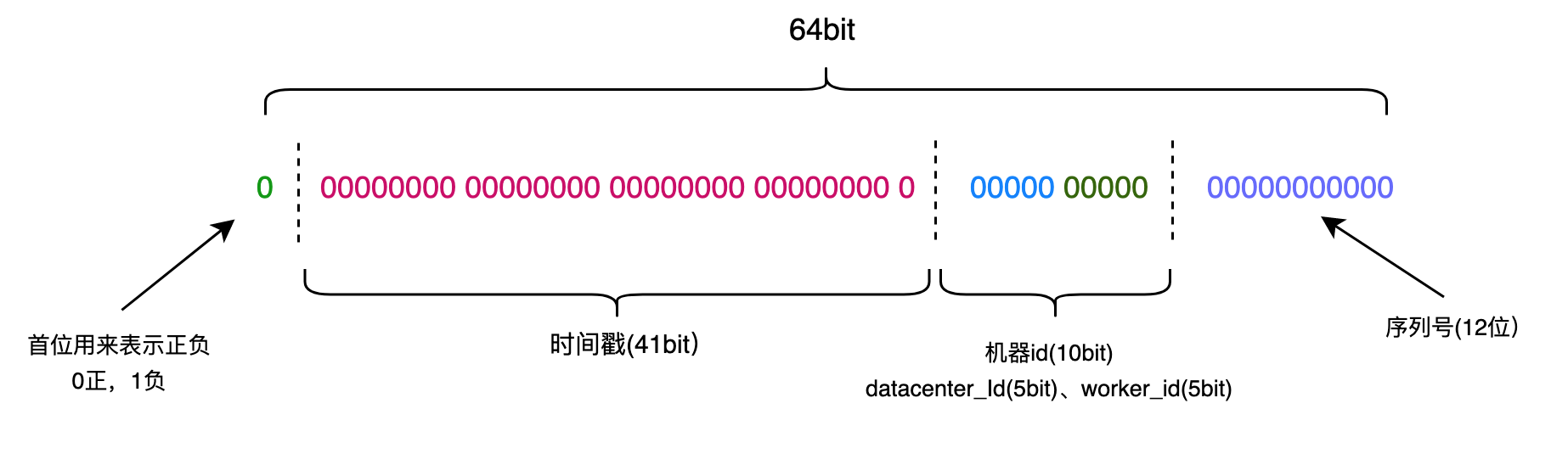
次のように実装したアルゴリズムであることスノーフレークコード:
cn.ganlixin.ssm.util.commonパッケージ;
パブリッククラスSnowFlakeIdGenerator {
//切り捨て初期時刻(2017年1月1日)
プライベートロングINITIAL_TIME_STAMP =最終静的1483200000000L;
ビット//数は、マシンIDによって占有
最終プライベート静的長いWORKER_ID_BITS = 5L、
ビット数を識別するためのデータは、IDによって占有//
プライベート静的最終ロングDATACENTER_ID_BITS = 5L;
//最大サポートされているマシンIDを、結果は31である(このシフトアルゴリズムを迅速にいくつかの2進数を計算することができ表すことができます。小数点以下の最大数)
プライベートロング最終静的MAX_WORKER_ID =〜(-1L << WORKER_ID_BITS);
最大データ識別ID //サポート、結果は31である
プライベートロング最終静的MAX_DATACENTER_ID =〜(-1L << DATACENTER_ID_BITS);
//配列IDは、ビットを占め
、民間最終長いSEQUENCE_BITS = 12L
機// ID(12)オフセットを
民間最終長いWORKERID_OFFSET = SEQUENCE_BITS、
データセンタのオフセット// ID(12 + 5である。)
プライベートロングDATACENTERID_OFFSET =ファイナルSEQUENCE_BITS + WORKER_ID_BITS;
(。5 + + 12であり、5)時間オフセットは//切り捨て
プライベートロングTIMESTAMP_OFFSET =ファイナル+ + SEQUENCE_BITS WORKER_ID_BITS DATACENTER_ID_BITS;
//マスクシーケンスを生成する、ここで4095(0b111111111111 = 0xFFF = 4095)
プライベートロングSEQUENCE_MASK =ファイナル〜(-1L << SEQUENCE_BITS);
//データセンタID(〜31 0)
プライベートロングdatacenterId;
//ワーキングノードID(〜31 0)
プライベートロングworkerId;
// MS配列(〜4095 0)
プライベートロング配列= 0L;
最後の世代ID断面の//時間
プライベートロングLastTimestamp = -1L;
/ * *
*コンストラクタ
*
* @Param datacenterIdデータセンターのIDが(〜31は0)
* @param workerId作業ID(〜31 0である)
* /
公共SnowFlakeIdGenerator(datacenterId長い、長いworkerId){
IF(workerId> MAX_WORKER_ID || workerId <0){
新しい新しいIllegalArgumentExceptionをスローし(String.Formatの()は、MAX_WORKER_ID "WorkerID%dはない以上0未満である");
}
(datacenterId> MAX_DATACENTER_ID || datacenterId <0){IF
スロー新しい新しいはIllegalArgumentException(String.Formatの(「%D dataCenterID以上でない0未満」MAX_DATACENTER_ID));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/ **
*)同期ロックと次ID(スレッドセーフを取得
*
* @return SnowflakeId
* /
長いNEXTID同期パブリック(){
//ミリ秒のタイムスタンプ(13)
長いタイムスタンプ=にSystem.currentTimeMillis();
//現在の時刻を通って送出されなければならないより少ないシステムクロックバックオフ時間を示す最後の世代のIDのタイムスタンプよりも大きい場合異常な
IF(タイムスタンプ<LastTimestamp){
スロー新新のRuntimeException(「現在の時間が少ない記録された最後のタイムスタンプよりです!」);
}
//それが同時に発生した場合、シーケンスミリ秒
IF(LastTimestamp ==タイムスタンプ){
シーケンス=(+配列1)&SEQUENCE_MASK;
//配列は、配列が最大に増加することが記載されている0ミリ秒に等しい
(配列== 0){IF
//次ミリ秒ブロッキング、新しいタイムスタンプ取得する
タイムスタンプ= tilNextMillisを(lastTimestamp)を;
}
シーケンス= 0L。
}他{
//タイムスタンプの変更、リセットシーケンスミリ秒
}
// ID生成時刻、最後のカット
LastTimestamp =タイムスタンプ;
//論理和とを用いて、64ビットのIDからなる戦うためにシフト
リターン((タイムスタンプ- INITIAL_TIME_STAMP)<< TIMESTAMP_OFFSET)
|(datacenterId << DATACENTERID_OFFSET)
|(workerId << WORKERID_OFFSET)
|シーケンス;
}
/ **
*新しいタイムスタンプまで、次のミリ秒に閉塞、
*
* @param ID LastTimestamp前回発生切り捨て
* @戻り現在のタイムスタンプ
* /
保護ロングtilNextMillis(ロングLastTimestamp){
ロングタイムスタンプ=にSystem.currentTimeMillis();
一方、(タイムスタンプ<= LastTimestamp){
タイムスタンプ=のSystem.currentTimeMillis();
}
タイムスタンプを返します。
}
}
テスト使用:
パッケージcn.ganlixin.ssm.util;
輸入org.junit.Test;
パブリッククラスSnowFlakeGeneratorTest {
@Test
公共ボイドtestGen(){
SnowFlakeIdGenerator idGenerator =新しいSnowFlakeIdGenerator(1、1)。
System.out.println(idGenerator.nextId())。// 429048574572105728
}
}