I.背景
スレッドセーフなのHashMap
使用のHashMapのput操作のための複数の環境では、100%のCPU使用率に近い、その結果、サイクルを引き起こす可能性がありますので、HashMapの同時実行で使用することはできません。
非効率的なコンテナのHashTable
ハッシュテーブルコンテナがスレッドの安全性を確保するために、同期が、使用して高度にスレッド化競争のハッシュテーブルの効率が非常に、非常に下部に、同期方法1つのスレッドがハッシュテーブルにアクセスするとき、あなたはブロックされた状態に入る可能性があるため、このようプットの追加要素を使用して、スレッド1のように、スレッド2は、使用に置く要素を追加することはできません、と要素を取得するにはgetメソッドを使用することはできません、より競争、より非効率的なので。
ロックセグメンテーション
すべてのアクセスハッシュテーブルのスレッドが同じロックのために競争しなければならないので、それがどのようにコンテナのデータの各部分は、コンテナをロックした場合のHashTableコンテナは、効率の原因を根本的により複雑に競争の激しい環境の中で明らかに複数のスレッドがコンテナにアクセスすると、何のスレッド間ロックの競合はありません。有効ConcurrentHashMapのロック分割技術、スレッドは、前記データアクセスロックを保持しているときに、データ毎に、ロックして、格納することによって最初のデータセグメント、他のデータ・セグメントであるアクセス効率を向上させることができますまた、他のスレッドによってアクセスされることができる、いくつかの方法は、そのようなサイズ()とのcontainsValue()は、彼らはむしろ単にセグメントロックよりも、テーブル全体をロックすることができるような断面を必要操作が完了した後、すべてのセグメントが、注文に必要ロック、及び順序すべてのセグメントのロックを解除します。ここで順番に非常に重要である、またはそうConcurrentHashMapの内側にデッドロックされ、データセットの最後のセグメントであり、実際に最後のメンバ変数である、しかし、配列の唯一の最後の文は、データメンバーを保証するものではありませんです順番は、ロックが固定取得するので、そのデッドロックがないことを確認しており、必要が達成することを確実にするためである、最終的です。
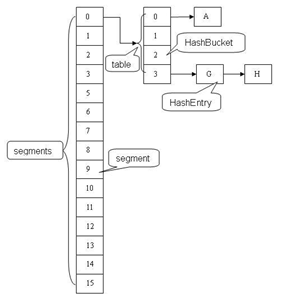
ConcurrentHashMapのセグメントデータ構造は、構造体の配列とHashEntry、リエントラントセグメントロックReetrantLock、ロックにおけるConcurrentHashMapの役割、鍵データを格納するためのHashEntry、セグメントを含んConcurrentHashMapの配列セグメントでありますリスト構造とセグメントHashEntry配列を含む配列、などのHashMap構造と、リストの各要素はHashEntry構造です。各セグメントHashEntryデータアレイがHashEntry変更されるガーディアン素子アレイは、最初に対応するロッキングセグメントを取得しなければなりません。
第二に、アプリケーションのシナリオ
複数のスレッドのシェアは複数のノードにそれを置くかどうかを検討することができたときに、必要に応じて大規模な配列がある場合、大きなロックを避けます。モジュールのいくつかを検討し、ハッシュアルゴリズムによって配置することができます。実際には、より多くのスレッドよりも、ときに、トランザクションの設計データテーブル同期の配列は、必要に応じて、テーブルのデータ操作は問題を考慮することが多すぎる(また感総務同期メカニズムを反映する)、機器は、表示することができます(分離あなたは、このようなデータフィールドスプリットレベルのサブリストなど、)大きなテーブルを避けたい理由です。
第三に、ソースコードの解釈
ConcurrentHashMapの三つの主要なクラスが間に見ることができる上記の関係に対応する、ConcurrentHashMapの(全体のハッシュテーブル)、セグメント(バレル)、HashEntry(ノード)に実装されています
/**
* The segments, each of which is a specialized hash table
*/
final Segment<K,V>[] segments;
一定(不変)と可変(揮発性) `
のConcurrentHashMapのに十分同時に複数の動作を可能にする従来の技術を使用している場合のHashMapに実装されることが可能ハッシュチェーンを追加または削除することが許可されている場合、読み出し動作は、ロックを必要としません要素、読み出し動作は、結果の一貫性のないデータをロックしません。ConcurrentHashMapの実装技術は、構造が下に示されている各ノードHashEntryハッシュチェーン、代わって保証です。
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
また、あなたは他の値の最終値が最終的なものではなく、見ることができます。真ん中や尻尾から追加することはできませんまたは削除ノードのハッシュ・チェーンを、それはすべてのノードが唯一の頭から変更することができ、次の基準値を変更する必要があるので、入れていることをこの意味、すべての値のハッシュヘッドを追加するリストが、ためにすることができます操作操作を削除し、あなたが全体のレプリケーションノード側を削除する必要があり、中央からノードを削除する必要があり、次のノードへの最後のノードポイントは削除されます。削除について話すとき、これは、読み取り操作がロックを回避する、値が揮発性に設定されている、最新の値を見ることができることを確実にするために、詳細に説明します。
他の
セグメントハッシュ溝セグメントの速度および位置決めを促進するため、各スロットの長さがハッシュである2^n位置算出部とセクション缶ハッシュスロットを配置することによって位置を行い、。高4である16並行性レベルのデフォルト値は、セグメントの数、そのセグメントに割り当てられたハッシュ値を決定するが、我々は忘れてはならない場合:ハッシュスロットの数につながる可能性が2 ^ nは、あってはなりませんハッシュで再ハッシュ値に必要なハッシュ偏在溝、。
ポジショニング操作:
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
プロテクトデータセグメントセグメントセグメントへのConcurrentHashMapの使用が異なっているので、その後、挿入時間とは、要素を取得し、あなたが最初のセグメントにハッシュアルゴリズムを通じて見つける必要があり、あなたはConcurrentHashMapのは、最初のハッシュアルゴリズム再びハッシュコードのさまざまな要素を使用します見ることができますハッシュ。
再ハッシュ、その目的は、ハッシュ衝突を低減することであるハッシュ極端な低品質のレベルならば、素子は均一にすることにより、コンテナのアクセス効率を向上させる、異なるセグメント上に分配されます。だから、すべての要素は、セグメント、遅いアクセス要素だけでなく、ステージング領域、それが意味は同じです。私は、テスト、直接ではなく再ハッシュされたハッシュによってをしました。
System.out.println(Integer.parseInt( "0001111"、2)&15);
のSystem.out.println(Integer.parseInt( "0011111"、2)&15);
のSystem.out.println(Integer.parseInt( "0111111"、2)&15);
のSystem.out.println(Integer.parseInt( "1111111"、2)&15);
なくなった場合に出力15を計算したハッシュ値は、この例により、一杯になったが見つけることができます長い数が多いものを関係なく、限り低くとして、それは常に同じハッシュ値であるので、ハッシュ、ハッシュ衝突は、非常に深刻になります。読みやすくするために、次のように我々は、次に、再ハッシュ結果後のバイナリデータ上に実行、上位32ビットは0以上、垂直バーはすべての4つの分割されて構成します。
0100 | 0111 | 0110 | 0111 | 1101 | 1010 | 0100 | 1110
1111 | 0111 | 0100 | 0011 | 0000 | 0001 | 1011 | 1000年
0111 | 0111 | 0110 | 1001 | 0100 | 0110 | 0011 | 1110
1000年| 0011 | 0000 | 0000 | 1100年| 1000年| 0001 | 1010
あなたは、データのすべてのビットが開かハッシュ化されている見つけることができ、そしてこの再ハッシュで一人一人は、それによってハッシュ衝突を減らし、デジタルハッシュそれらを作るために参加することができます。ハッシュ位置決めセグメント別のConcurrentHashMap。
SegmentShiftデフォルトは28であり、segmentMask 15は、次にハッシュバイナリデータの最大数は32ビット、どのシンボルが右28に移動されていないが、上位4ビットは、ハッシュ演算、(ハッシュ>>> segmentShiftを意味関与ないこと)計算結果segmentMask 4,15,7及び8とは、それぞれ、ハッシュ値が競合しないことがわかります。
データ構造
のすべてのメンバーがsegmentMaskとsegmentshfitは主にセクションを配置するために、ハッシュテーブルの構造に基づいて、segmentFor方法上記参照ところ、最終的ですが、程度は、ここで探索するには、ハッシュテーブルは重要な側面は、紛争のハッシュを解決する方法をです、ハッシュ・チェーン内のノードの同じハッシュ値であり、ConcurrentHashMapののハッシュマップ同様、。そしてConcurrentHashMapのサブハッシュテーブル、即ちセグメント(セグメント)の複数を使用して、そのハッシュマップを除いて、。
各サブセグメントは、以下のようにデータ・メンバーであり、非常にハッシュテーブルです。
/**
* Stripped-down version of helper class used in previous version,
* declared for the sake of serialization compatibility
*/
static class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
//loadFactor表示负载因子。
final float loadFactor;
Segment(float lf) { this.loadFactor = lf; }
}
削除のremove(キー)
/**
* {@inheritDoc}
*
* @throws NullPointerException if the specified key is null
*/
public V remove(Object key) {
hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
}
全体の動作は、セグメントを見つけ、その後、操作部に委託除去することです。同時に削除操作が複数限り、それらが配置されるセグメントが同じでない場合、それらは同時に行ってもよいです。
ここで達成するセグメントremoveメソッドは次のとおりです。
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
*for (HashEntry<K,V> p = first; p != e; p = p.next)
*newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}
全体の動作を保有セグメントロックの場合に行われる、行の前に空白行は、主にノードeを削除する対象としています。次に、直接的なリターンヌルが存在しない場合、ノードは、それ以外の場合は、ノードE、ノードE内の次のノードへのエンドポイントの手前で再びそれをコピーする必要があります。レプリケーションの背後にある電子のノードが必要とされていない、彼らは再利用することができます。
forループの真ん中には、それをどうするかですか?コードから(*印)、その全てのエントリポジショナルクローニング及びバック後の正面に戦うことであるが、必要?すべての要素は、再びそのクローンの前に要素を除去する必要がありますか?これは、実際に意思決定への不変のエントリで、注意深い観察項目の定義は、それがもはや次のドメイン最初のセット後に変更することができた意味、他のすべての属性が最終的に変更するために使用され、値に加えましたノードのクローンを作成する前にそれをすべて置き換えます。エントリは、このように約時間を節約アクセスの不変性との同期を必要としない不変に設定されている理由については
ここでの概略図である

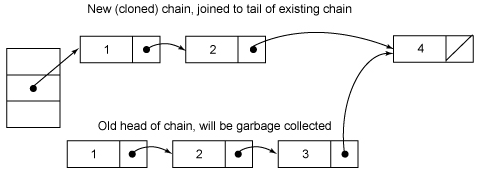
ノードの複製は、フロント、価値のノード2の値である必要があり、2番目の図は、実際に問題がありますノード1は正確に元のノードの逆順でバックであるが、幸い、これは我々の議論に影響を与えません。
全体の実装を削除する複雑ではないですが、以下の点に注意が必要です。まず、削除するノード、最後のステップ数マイナス1を削除するには価値があります。これは、操作の最後のステップでなければならない、または読み出し動作がセグメントの前に作られた構造的修飾を表示しないことがあります。変数テーブルは揮発性であるため、第二に、削除は、実行はローカル変数テーブル]タブを割り当てます始まり、読み書き揮発性の変数を大きなオーバーヘッド。コンパイラは、任意の読み取りを行うことができず、揮発性の変数の最適化を書いて、不揮発性の複数のインスタンス変数への直接アクセスはほとんど影響を与えなかった、コンパイラはそれに応じて最適化します。
操作を取得
ConcurrentHashMapのget操作は、デリゲートのセグメント、getメソッドを直接見のセグメントを取得するための直接的な方法です。
V get(Object key, int hash) {
if (count != 0) { // read-volatile 当前桶的数据个数是否为0
HashEntry<K,V> e = getFirst(hash); 得到头节点
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
/**
*
/
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
returnnull;
}
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
それはノード欲望を見つけた場合、それは、もし、その非空の戻り値が直接決定されるか、またはロック状態で再びそれを読み取ること。彼は我々がNullPointerExceptionが空で投げる必要があるかどうかを判断するために置かれているときので、それは理解しにくい見えるかもしれませんが、ノードの理論値は、空にすることはできません。ソースのみHashEntry値は最終ではないので、HashEntryにヌル値のデフォルト値であり、非同期読み出しがヌル値に読み取ることができます。慎重に置く操作文を見て:タブ[インデックス] =新しいHashEntry <K、V>(キー、ハッシュ、まず、値)、 この文では、HashEntryコンストラクタやタブの値の割り当て[インデックス]割り当ては、ノードが空になる恐れがある、再注文したことがあります。vが空になったときにここで、それはスレッドがこの電子にそうで、ここで再び、書き込みや一貫性のないデータの原因となります読み書きを読んだ後、ロックの前の操作のGETなしのに対し、ノードを変更する条件をバーンスタインによるものであるかもしれロックは、正しい値を保証する、もう一度それを読んで。
プット動作
同じ通常動作セグメントは、次のような方法が置かれていることを置く方法を委託されています。
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
方法がそのようにスレッド安全にするために、操作共有変数にロックする必要があり、共有変数の書き込み動作を置くために必要であったので、最初のセグメントの方法を配置入れ、次いでセグメントで動作します。インサートは、第一の配列膨張HashEntryセグメントの必要性は、第2のステップは、アレイのHashEntryに添加元素の位置に配置されているか否かを判断し、二つのステップを経る必要があります。
操作containKeyの方法
//判断是否包含key
boolean containsKey(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key))
return true;
e = e.next;
}
}
returnfalse;
}
サイズ()操作
グローバル変数の数で、我々は全体ConcurrentHashMapの要素のサイズでカウントされる場合、要素の総和のサイズのすべてのセグメントをカウントする必要があり、セグメントはマルチスレッドのシナリオでは、揮発性の変数であり、我々は、直接ではありません数あなたのすべてのセグメントの合計が全体のConcurrentHashMapのサイズを得ることができますか?いいえ、取得後に蓄積する可能性、使用の変更の前にセグメントの最新のカウント値へのアクセスを追加しますが、カウント値が、結果は許可された統計です。プットのセグメントのサイズ、削除、クリーンな方法は、すべてのロックされたときに、セキュリティのアプローチは、統計であるが、この方法の効率が特に低いです。
ConcurrentHashMapのアプローチは、統計的プロセス場合は、セグメントのセグメントサイズをロックしないことによって、2回道をカウントする最初の試みにコンテナであるので、カウント累積カウント動作プロセスの変化の確率は、前の蓄積に、非常に小さなを持っていたので、すべてのセグメントの大きさに統計的手法を用いて再びロック、その後、変更を数えます。
だから、ConcurrentHashMapのは、ときに船が統計に変更されているかどうかを判断する方法ですか?使用modCount変数、変数modCount前部要素は、統計は、血管のサイズが変更されたのでことを、運転中に、削除し、クリーンな方法を置く前と後に続いサイズの変化かどうかmodCountを比較し、1に追加されます。
