MapReduceのにHQL / SQLのHadoop上で実行されている、と見ることができます:ハイブは本質である
SQLの構文解析エンジン
HadoopのHiveのが基づいている
データ・ウェアハウス・
ツールは、テーブルにデータファイルの構造をマップし、SQLに似たクエリを提供することができます。
ハイブの表は
、その後、サブディレクトリに対応するパーティション値パーティションがある場合は、HDFSファイルディレクトリ、ディレクトリ名にテーブルの対応です。
ハイブチュートリアル:ハイブウィキ
二、ハイブアーキテクチャ:
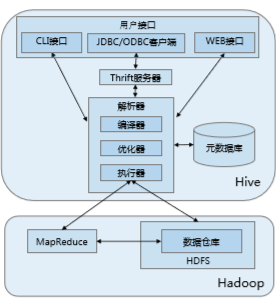
1.ユーザインタフェース:
(1)CLI:あなたが起動したときにハイブにもコピーを開始します
(2)JDBCクライアントは:スリフト、javaアプリケーションをカプセル化し、サーバがで指定されたホストとポートで動作しているハイブ別のプロセスに接続することができます
(3)ODBCクライアント:: ODBCドライバは、アプリケーションハイブに支持ODBCプロトコル接続することを可能にします。
2.Thriftサーバー:ソケットベースの通信、クロス言語サポート
3.パーサ(実行される文を解析):
(1)コンパイラ:文を解析し、解析、コンパイル、作業計画の照会を開発
(2)オプティマイザ:進化アセンブリルール:カラムの構成を、圧力下述
(3)アクチュエータ:すべてのジョブの順序を実行します。
4.元のデータベース:
データファイルとメタデータ:ハイブデータは、2つの部分からなります。メタデータは、基本的な情報ハイブリポジトリを格納するために使用され、それは、MySQLの、ダービーとして、リレーショナルデータベースに格納されています。メタデータが含まれています:列属性情報データベース、テーブル名、および表パーティションとその属性、テーブルを、内容やその他のデータのテーブルが配置されています。
三、ハイブ操作機構
1. Aのユーザ
のユーザへのインタフェースは、
ハイブ、公開されたハイブSQLを接続し、
2.Hive
クエリを解析
し、
クエリプランを策定
。
クエリを回し3.Hive
MapReduceジョブへ
。
4.Hive
のHadoopのMapReduceでの実装
の仕事。
四、ハイブの長所と短所
位置データウェアハウス、データ分析及び偏向の方向の計算
1.利点:
(1)大量のデータを扱うのに適し
(2)クラスタのCPUコンピューティングリソース、記憶リソース、並列コンピューティングを活用
(3)クラスSQLは、自動的に生成されたMapReduce
(4)。スケーラビリティ
2.短所:
(1)有限HQL発現.Hive
低い(2).Hive効率:ハイブMRジョブは通常インテリジェントない、自動的に生成され、HQLチューニング困難、粗い粒径;乏しい制御性。
非効率性を示します。SQLのSparkSQL出現を効果的にHadoop上の分析の業務効率を向上させます。
五、ハイブ該当シーン
1.大容量データ記憶装置およびデータ分析
2.データマイニング
リアルタイム問合せに適していない複雑なアルゴリズムや計算、には適していません3。
第六に、ハイブの使用
(A)接続ハイブ
使用HiveServer2、ビーライン、CLI接続
(II).Hiveデータタイプ
|
分類
|
タイプ
|
説明
|
例
|
|
プリミティブ型
|
BOOLEAN
|
真/偽
|
TRUE
|
|
|
TINYINT
|
127 -128整数符号付き1バイト
|
1Y
|
|
|
SMALLINT
|
-32768〜32767の整数の符号付き2バイト
|
1S
|
|
|
INT
|
4バイトの符号付き整数と
|
1
|
|
|
BIGINT
|
8バイトの符号付き整数
|
1L
|
|
|
浮く
|
4バイトの単精度浮動小数点数1.0
|
|
|
|
ダブル
|
8バイトの倍精度浮動小数点
|
1.0
|
|
|
DEICIMAL
|
任意精度の符号付き10進数
|
1.0
|
|
|
ストリング
|
文字列、可変長
|
「」、 'B'
|
|
|
VARCHAR
|
可変長文字列
|
「」、 'B'
|
|
|
CHAR
|
固定長文字列
|
「」、 'B'
|
|
|
バイナリ
|
バイト配列
|
表現することはできません。
|
|
|
TIMESTAMP
|
タイムスタンプ、ナノ秒の精度
|
122327493795
|
|
|
日付
|
日付
|
「2016年3月29日」
|
|
複合型
|
アレイ
|
同じタイプの順序集合
|
アレイ(1,2)
|
|
|
地図
|
キー値、キーがプリミティブ型である必要があり、値は任意の型を指定できます
|
マップ( ''、1、 'B'、2)
|
|
|
STRUCT
|
フィールドセットは、異なるタイプであってもよいです
|
構造体( '1'、1,1.0)、named_stract( 'COL1'、 '1'、 'COL2'、1 'clo3'、1.0)
|
|
|
連合
|
の限られた範囲内の値
|
create_union(1、 ''、63)
|
(C).Hive手術台と
データ格納されたメタデータ構成+
ハイブはまた、データベースは、CREATE DATABASEでデータベースを作成することができました。デフォルトのライブラリがデフォルトのライブラリです。
1は、2つのホスティングの種類と外側テーブルを含みます
(1)データストレージ
マネージド表:倉庫内のディレクトリデータストレージ。
外部表:任意のディレクトリデータストレージHDFS。
(2)データを削除しました
マネージド表:削除メタデータとデータ。
外部表:削除のみ
メタデータ
。
(3)テーブルを作成します。
表をホスティング:テーブルtable_name(ATTR1 STRING)を作成します。
外部表:CREATE
EXTERNAL
表table_name(ATTR1列)
LOCATION
'パス';
データ分割アプローチは、クエリをスピードアップすることができます。表 - >パーティション - >バレル。
2.パーティション(フォルダレベルの分類を行います)
(1)パーティション列データが実際に格納されていませんが、パーティションテーブルは、ディレクトリの下のディレクトリをネストされました。
例:
データ:

(2)の表は、様々な寸法に(上記例に係るIDファンを分割することである)に分配されてもよいです。
(3)パーティションができ
、効率を改善するために、検索クエリを絞り込みます。
パーティションが持つテーブルを作成することである(4)
BY PARTITION
定義句。
(5)
パーティションにデータをロードするには、
パーティションの値は、文の負荷を使用して表示されるように指定されました。
(6)使用
SHOWパーティション
文はどのような次のハイブのパーティションテーブルを参照します。
(7)を使用して
SELECT
指定されたパーティション内のビューデータに文を、ハイブは、指定されたパーティションのデータをスキャンします。
(8)ハイブテーブルは2つのパーティション、パーティション静的および動的なパーティションに分割されています。静的および分割ダイナミックパーティション
の時間差は、(通常はヘルプをパーティションでハイブにしたがって命名規則を通して私たちは、ハイブインポートデータ、パーティション名を手動で入力された、またはデータパーティションを決定するためのデータにある
自動的に生成されたパーティションを
)。
大バルクインポートデータのために、あることは明らかである
動的分割の使用が
より簡便です

3.バレル(ファイルに分類分割)
(1)バレルは、テーブル付加的な構造上に取り付けられている、ことができ
、クエリパフォーマンスを向上させる、
操作をマップ側にジョインすることが有益。
(2)より便利で効率的なサンプリングを使用します
(3)を使用し
て、クラスタ
の列を、分割されるバケットの数は、浴槽が使用句の指定に分割されます。
4つのバケットに(ID)によってクラスタ化されたテーブルbucketed_user(ID int型、名前の文字列)を作成します。
(4)あなたがソートに行うことができ、データバケット。使用
SORTED BYの
句。
(ID)4つのバケットに(識別ASC)でソートすることによって、クラスタ化テーブルbucketed_user(ID int型、名前の文字列)を作成します。
(5)
当社独自のポイントの樽を推奨していませんが、ハイブがバレルを分けてみましょうすることをお勧めします。
第1の分割バレルがあり、データで埋めバケットに下ります。
バケットが必要なデータが充填される(6)分前に提供することが
trueにセットhive.enforce.bucketing
。(他のテーブルからのデータを照会するバレル槽内に挿入された作成、動的プロセス)
ユーザーからの選択*上書きテーブルbucket_usersを挿入します。
(7)が実質的に桶のMapReduce出力パーティション・ファイルに対応する:
バレルの同じ数とジョブによって生成されたタスクを減らします。
ハイブはまた、列の値を使用してハッシュした、
そして次にバケットに格納されなければならない決定のこのレコード以上を取る方法の樽の数で割ます。
これは、MRの原則HashPartitionerは同じです。
詳細部分バレルについては、以下の要素を指します。
4.ストレージ・フォーマット
「ライン形式」(行形式)と「ファイル形式」(ファイル形式):ハイブが2次元からストレージ・テーブルを管理します。
(1)ラインフォーマット:
行形式でデータを格納します。ハイブの観点によれば、
定義はSerDeライン形式によって定義され
、すなわち、シリアライゼーションおよびデシリアライゼーション。すなわち、クエリデータ内SerDeファイル
の形式のデータのバイト
列
デシリアライズ
使用する内部動作ハイブのデータ行の形で目的とします。テーブルにデータを挿入するときハイブ、工具の配列の形式で出力ファイルに書き込まれたバイトのシーケンスに内部データ線表現をハイブて行くであろう。
(2)ファイル形式
最も単純なファイル形式は、プレーンテキストファイルですが、あなたはまた、列指向と行指向のバイナリファイル形式を使用することができます。バイナリファイルは、シーケンシャルファイル、アブロ、のrcfile、ORC、寄木細工のファイルとすることができます。
デフォルトのストレージ形式は
:区切りテキスト、区切りのテキストはLazySimpleSerDeのデフォルトを使用して処理します。
5.データのインポート
データのインポート(1)挿入モード:
マルチテーブル挿入、動的分割を挿入します。
導入された(2)ロード・モード
(3)CATS方式:(CREATE TABLEの... AS SELECT)
基本的な考え方は、テーブルを作成し、データをチェックアウトすることです
6.変更、および削除テーブル
、「読み取りモード」を用いてハイブのでテーブルを作成した後、
それはテーブル定義に非常に柔軟な支持修飾です
。しかし、一般的に、我々は警戒する必要がある、多くの場合、データは新しい構造に沿ったものであることを保証するために、ユーザーによって変更されます。
(1)リネームテーブル
ALERT TABLEの
テーブル名の
TO RENAME
new_tablename
。
(2)列の定義を変更(列のみを追加する例を引用し、あなたは公式文書の多くの例を見に行くことができます)
警告テーブルの
テーブル名の
ADDカラム(
COLNAMEの
列)。
(3)削除テーブル
DROP TABLE;(削除メタデータ・テーブルをホストするためには、テーブルデータ+であり、外部の削除メタデータ・テーブルのみ)
表切断(4)(記憶されたテーブル構造、データテーブルが空)
削除(削除)とスペースを再利用しますTRUNCATE(カット)は、データ、および関連する指標で占領しました。テーブル所有者だけがテーブルを切り捨てることができます。
TRUNCATE TABLEの
テーブル名
[パーティション
partition_spec
]。
7.開発:
ソリューションアブロ、のrcfile、ORC、寄木細工のストレージ構造、類似点と相違点を比較します。
次のブログは、ハイブのファイル形式について説明し、これらのまとめた
特性ファイル形式を
ハイブ共通保存形式で、次のブログを比較した(主に用
収納スペースと、クエリの効率を
試験しました)
