1. La recherche en texte intégral
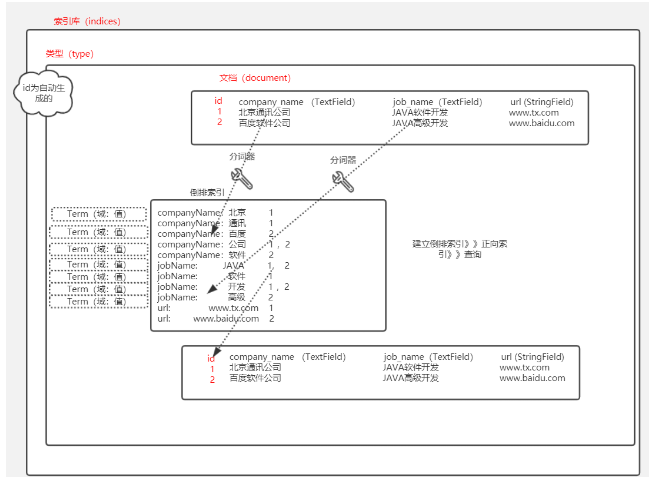
1.1 Classification des données
Des données structurées:
MySQL: Le champ de type et la taille sont fixés
Les données non structurées:
Recherche:
1.2 Comparaison de la recherche générale et recherche en texte intégral
| récupération normale (MySQL) (ajouts et suppressions) | Recherche plein texte (recherche) | |
|---|---|---|
| Types de données | Les données structurées | Des données structurées et les données non structurées |
| processus | Créer un index, puis fondé sur une requête sur l'ID | Créer un index inversé , puis en fonction de l' index inversé requête |
| vitesse requête | Parfois rapide, parfois lent | certains rapide |
| Les résultats vont | ordinaire | large |
| affaires | soutien | Il ne supporte pas les transactions |
1.3. Scénario de recherche plein texte
L'intérieur (1) Recherche
Par exemple: le recrutement micro patron Primus United engagé directement
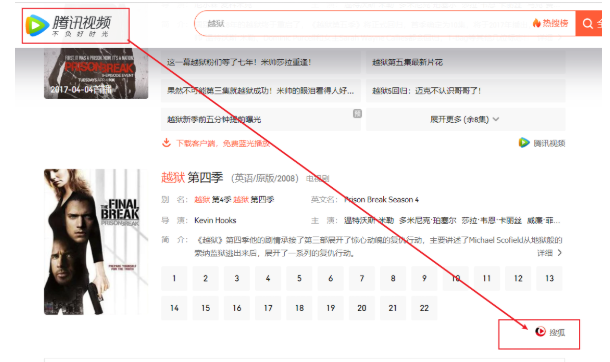
(2) la recherche verticale
Par exemple, la vidéo Tencent se trouve à Sohu vidéo
(3) moteur de recherche
Baidu Google

2.lucene (comprendre)
Lucene: la base de toute recherche populaire texte intégral du cadre sont Lucene, pour obtenir un dépôt de paquets jar (bibliothèque) site officiel de recherche en texte intégral: https: //lucene.apache.org/
solr: Ce package de base de données cadre de la bibliothèque de package jar Lucene
recherche élastique: paquet cadre pot Lucene package cette bibliothèque, plus forte, plus professionnelle que solr, plus simple
2.1 Recherche texte intégral
(1) Créer un projet vide:
Nommé: plein texte recherche

(2) créer un nouveau module, lucene

(3) l'addition d'une dépendance pom:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.shenyian.demo</groupId>
<artifactId>lucene</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 版本锁定-->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.7.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- lucene 依赖-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>4.10.3</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>4.10.3</version>
</dependency>
<!-- mybatis plus 的起步依赖-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>2.3</version>
</dependency>
<!-- mysql 依赖-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!-- 单元测试的起步依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<!-- ik分词器 -->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
</dependencies>
</project>:( scripts SQL dossier dans le fichier de code)
(4) modifier le fichier de configuration application.yml
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.176.109:3306/elastic_search?useUnicode=true&characterEncoding=UTF8&useSSL=false&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: ****(5) créer une classe de démarrage, ajouter des annotations MapperScan
package com.shenyian;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.shenyian.mapper")
public class LuceneApplication {
public static void main(String[] args) {
SpringApplication.run(LuceneApplication.class, args);
}
}(6) créer la classe d'entité JobInfo
package com.shenyian.domain;
import com.baomidou.mybatisplus.annotations.TableId;
import com.baomidou.mybatisplus.annotations.TableName;
import lombok.Data;
@Data
@TableName("job_info")
public class JobInfo {
@TableId
private Long id;
//公司名称
private String companyName;
//职位名称
private String jobName;
//薪资范围,最小
private Integer salaryMin;
//招聘信息详情页
private String url;
}
(7) créer mappeur
package com.shenyian.mapper;
import com.baomidou.mybatisplus.mapper.BaseMapper;
import com.shenyian.domain.JobInfo;
public interface JobInfoMapper extends BaseMapper<JobInfo> {
}
(8) les classes de test unitaire:
Créer une base de données d'index, ajouter des documents:
@Test
public void test() throws Exception {
List<JobInfo> jobInfos = jobInfoMapper.selectList(null);
//Directory d, IndexWriterConfig conf
Directory directory = FSDirectory.open(new File("H:\\lucene\\index"));//指定索引库保存的地址
//Version matchVersion, Analyzer analyzer
Analyzer analyzer = new IKAnalyzer();//中文分词器
//Analyzer analyzer = new StandardAnalyzer();//标准分词器 对于英文识别,不识别中文
//Analyzer analyzer = new CJKAnalyzer();//中日韩分词器 分词的不准
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LATEST, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig); //用来创建索引库的工具
for (JobInfo jobInfo : jobInfos) {
Document document = new Document();
document.add(new TextField("companyName", jobInfo.getCompanyName(), Field.Store.YES));
document.add(new TextField("jobName", jobInfo.getJobName(), Field.Store.YES));
document.add(new DoubleField("salaryMin", jobInfo.getSalaryMin(), Field.Store.YES));
document.add(new StringField("url", jobInfo.getUrl(), Field.Store.YES));
indexWriter.addDocument(document);//添加document 文档
}
indexWriter.close();//io关闭
}Voir la base de données de l'index par les outils luke:

Sélectionnez le dossier dans lequel le code d'index:


Cliquez sur OK:
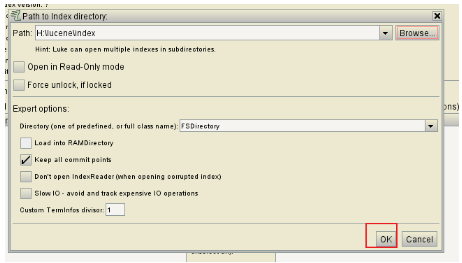
Bibliothèque Index:
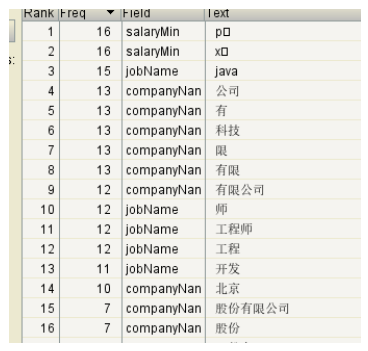
(9) Le système d'interrogation
@Test
public void search() throws Exception {
IndexReader indexReader = DirectoryReader.open(FSDirectory.open(new File("H:\\lucene\\index")));//用来读取索引库的信息
IndexSearcher indexSearcher = new IndexSearcher(indexReader);//是用来检索
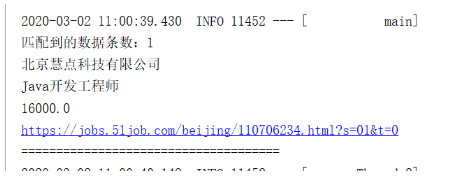
TopDocs topDocs = indexSearcher.search(new TermQuery(new Term("jobName", "java")), 10);//通过term查询,最多显示10条
int totalHits = topDocs.totalHits;
System.out.println("匹配到的数据条数:" + totalHits);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;//通过倒排索引查询到的id数组
for (ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc;//文档的id
Document document = indexSearcher.doc(doc);//通过id查询到文档
System.out.println(document.get("companyName"));
System.out.println(document.get("jobName"));
System.out.println(document.get("salayMin"));
System.out.println(document.get("url"));
System.out.println("=====================================");
}
}mot de mot étendu 2.2.IK et arrêt des mots
Créez un fichier dans les ressources: IKAnalyzer.cfg.xml
Ensuite, créez un fichier ext.dic de ressources et stopword.dic
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的停止词字典-->
<entry key="ext_stopwords">stopword.dic</entry>
</properties> (1) l'addition d'un des mots d'extension et arrêter mots Profils
(2) ajouter un mot d'extension

(3) créer à nouveau une bibliothèque d'index, vous pouvez effacer avant la base de données d'index

Après (4) configuration, vous devez recharger le document (pour enlever l'ancien chargement avant):

(5) qui se trouve dans le terme étendu, les mots d'arrêt découvrir
2.3. PPC (code clé ci-dessous)
Le tri par défaut est basé Match: Si un match est le même degré, puis selon id
PPC priorité plus élevée que le degré de correspondance, en définissant les attributs du champ: textField.setBoost (10000); // Taux
@Test
public void test() throws Exception {
List<JobInfo> jobInfos = jobInfoMapper.selectList(null);
//Directory d, IndexWriterConfig conf
Directory directory = FSDirectory.open(new File("H:\\lucene\\index"));//指定索引库保存的地址
//Version matchVersion, Analyzer analyzer
Analyzer analyzer = new IKAnalyzer();//中文分词器
//Analyzer analyzer = new StandardAnalyzer();//标准分词器 对于英文识别,不识别中文
//Analyzer analyzer = new CJKAnalyzer();//中日韩分词器 分词的不准
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LATEST, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig); //用来创建索引库的工具
indexWriter.deleteAll();//清除原先的索引库
for (JobInfo jobInfo : jobInfos) {
Document document = new Document();
document.add(new TextField("companyName", jobInfo.getCompanyName(), Field.Store.YES));
document.add(new TextField("jobName", jobInfo.getJobName(), Field.Store.YES));
document.add(new DoubleField("salaryMin", jobInfo.getSalaryMin(), Field.Store.YES));
document.add(new StringField("url", jobInfo.getUrl(), Field.Store.YES));
indexWriter.addDocument(document);//添加document 文档
}
//单独添加一个给钱的公司
Document document = new Document();
TextField textField = new TextField("companyName", "给钱的随便写的给了排名第一的有限公司", Field.Store.YES);
textField.setBoost(10000); //打分
document.add(textField);
document.add(new TextField("jobName", "java", Field.Store.YES));
document.add(new DoubleField("salaryMin", 30000, Field.Store.YES));
document.add(new StringField("url", "www.suibian.com", Field.Store.YES));
indexWriter.addDocument(document);
indexWriter.close();//io关闭
}Recherche 3.Elastic
es a deux ports: 9200 (accessible via un protocole navigateur http) 9300 (clusters es rendent visite, accès protocole tcp)
Installation: node.js "6.2.4 Version es" Version 6.2.4 de l'outil de visualisation Kibana « Google navigateur plug-es
1, le noeud d'installation:
(1) tout le chemin à côté, l'installation intelligente
(2) vérifier la fenêtre d'entrée de commande cmd: Si versioning installation réussie
2, l'installation es et Kibana:
(1) es et Kibana compressés, décompression
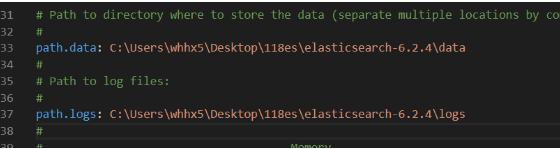
(2) trouvé dans les solutions logicielles de répertoire config es après compression, puis modifié comme suit:

1) elasticsearch.yml: sauver la conservation des données du journal et l'adresse d'adresse
2) jvm.options: mémoire de configuration de démarrage occupée

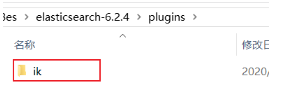
(3) ajouter le plug-ins dossier dans es ik plug-in mot, si vous avez déjà, puis diriger la quatrième étape:
(4) Début es:

(5) a lancé deux ports 9200 est accessible via un navigateur, 9300 pour le cluster.

(6) Vérification: Si le navigateur affiche les informations suivantes ont été installé avec succès au nom es

(6) Si le démarrage es d'erreur, le message d'erreur:

(7) dans le répertoire bin du logiciel d'installation Kibana, commencez Kibana:
(8) Si la console est imprimée comme suit:

(9) page Kibana ouvert dans un navigateur, cliquez sur Outils Dev: http: // localhost: 5601
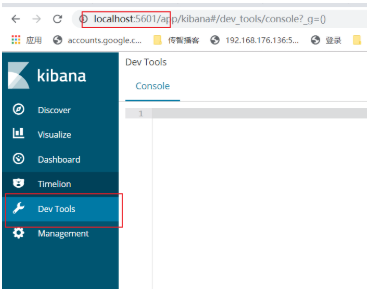
(9) plug-in Google navigateur installé:
1) Google Plug-Adresse: google --- "Autres outils ----" extension

2)
Décompressez le fichier;
3) S'il n'y a pas d'extension de cette charge comprimée, puis cliquez sur le mode développeur

4) Ajouter extension

5) Vérification du navigateur Google

6) Après avoir cliqué sur:
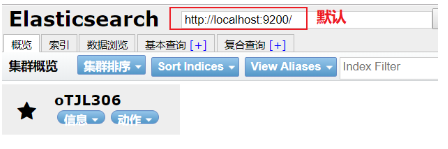
3.1. Vérifiez si l'entrée en vigueur mot ik
GET /_analyze
{
"text": "我是一个好学生",
"analyzer": "ik_smart"
}
或者
GET /_analyze
{
"text": "我是一个好学生",
"analyzer": "ik_max_word" 推荐的
} 
Kibana soutien reposant Style:
PUT généralement créer une base de données d'index, le type
POST ajouter et modifier des documents en général
Les données obtenues au nom de GET
Supprimer pour supprimer le général
3.2. Index des opérations Bibliothèque
Créer un index Bibliothèque: PUT / shenyian

index requête Bibliothèque: GET / shenyian

Supprimez l'index Bibliothèque: SUPPRIMER / shenyian
3.3. Création d'une bibliothèque de types d'index (type) (non recommandé)
PUT /shenyian
PUT /shenyian/_mapping/goods //创建索引库中的类型
{
"properties": { //固定写法
"goodsName":{// 类型中的字段
"type": "text", //字段的field类型
"index": true, //是否会检索
"store": true, //是否在文档中保存
"analyzer": "ik_max_word" //用哪个分词器
}
}
}3.4. En même temps, la bibliothèque et de créer un type d'index (type) (recommandé)
PUT /shenyian
{
"mappings": {
"goods":{
"properties": {
"goodsName":{
"type": "text",
"index": true,
"store": true,
"analyzer": "ik_max_word"
},
"price":{
"type": "double", //double的field类型
"index": true,
"store": true
},
"image":{
"type": "keyword", //和lucene的stringField一样,保存字符串,但是不分词
"index": true,
"store": true
}
}
}
}
}
Créer un modèle (comprendre)
PUT /shenyian2
{
"mappings": {
"goods":{
"properties": {
"goodsName":{
"type": "text",
"index": true,
"store": true,
"analyzer": "ik_max_word"
}
},
"dynamic_templates":[
{
"myStringTemplate":{ //自定义的模板名称
"match_mapping_type": "string", //匹配到的字段类型
"mapping":{
"type": "text",//如果匹配的是字符串,那么自动textfiled类型
"analyzer": "ik_max_word" //默认的ik_max_word分词器
}
}
}
]
}
}
}3.5. Le fonctionnement du document
Ajout de documents:
POST /shenyian/goods
{
"goodsName": "小米9手机",
"price": 2999,
"image": "www.xiaomi9.com/9.jpg"
}
或
POST /shenyian/goods/1 如果自己给id,那么es会用我们给的id
{
"goodsName": "小米9手机",
"price": 2999,
"image": "www.xiaomi9.com/9.jpg"
}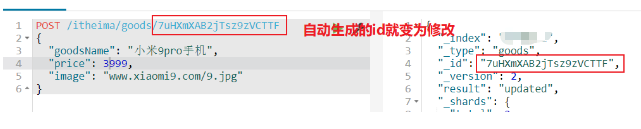
Modifier le document par id:
POST /shenyian/goods/7uHXmXAB2jTsz9zVCTTF //通过自动生成的id进行修改
{
"goodsName": "小米9pro手机",
"price": 3999,
"image": "www.xiaomi9.com/9.jpg"
}En identifiant la requête:
GET /shenyian/goods/7uHXmXAB2jTsz9zVCTTFEn supprimant id:
DELETE /shenyian/goods/7uHXmXAB2jTsz9zVCTTF3.7. Diverses requêtes (mise au point)
Préparation des données:
PUT /shenyian
{
"mappings": {
"goods":{
"properties": {
"goodsName":{
"type": "text",
"index": true,
"store": true,
"analyzer": "ik_max_word"
},
"price":{
"type": "double",
"index": true,
"store": true
},
"image":{
"type": "keyword",
"store": true
}
}
}
}
}POST /shenyian/goods/1
{
"goodsName": "小米9 手机",
"price": 2999,
"image":"www.xiaomi.9.jpg"
}
POST /shenyian/goods/2
{
"goodsName": "华为 p30 手机",
"price": 2999,
"image":"www.huawei.p30.jpg"
}
POST /shenyian/goods/3
{
"goodsName": "华为 p30 plus",
"price": 3999,
"image":"www.huawei.p30plus.jpg"
}
POST /shenyian/goods/4
{
"goodsName": "苹果 iphone 11 手机",
"price": 5999,
"image":"www.iphone.11.jpg"
}
POST /shenyian/goods/5
{
"goodsName": "苹果 iphone xs",
"price": 6999,
"image":"www.iphone.xs.jpg"
}
POST /shenyian/goods/6
{
"goodsName": "一加7 手机",
"price": 3999,
"image":"www.yijia.7.jpg"
}(1) Recherche
POST /shenyian/goods/_search 如果不通过id来查询,那么需要添加_search固定语法
{
"query": { 也是固定语法
"match_all": {}
}
}(2) durée requête
(Selon le terme d'index inversé à la requête)
POST /shenyian/goods/_search
{
"query": {
"term": {
"goodsName": "手机"
}
}
}(3) correspondent à la requête
(Mot de données de requête, et chaque terme de requête de mot, entraînera la collecte)
POST /shenyian/goods/_search
{
"query": {
"match": {
"goodsName": "手机 小米"
}
}
}(4) la portée de l'enquête
Selon une plage intervalle de champ
POST /shenyian/goods/_search
{
"query": {
"range": {
"price": { //通过price这个字段
"gte": 2000, gte:greate than equals
"lte": 4000 lte:less than equals
}
}
}
}(5) recherche floue
(Requête à tolérance de pannes, vous pouvez autoriser le mauvais mot, un maximum de deux)
POST /shenyian/goods/_search
{
"query": {
"fuzzy": { 容错查询关键字
"goodsName": {
"value": "iphoww",
"fuzziness": 2 容错率,最多是2
}
}
}
}(6) Booléen requête
(Combinaison de requête, les combinaisons de requête mentionné ci-dessus)
POST /shenyian/goods/_search
{
"query": {
"bool": {
"must": [ //下面的match查询的结构和range查询的结果的交集
{
"match": {
"goodsName": "手机 小米"
}
},
{
"range": {
"price": {
"gte": 2000,
"lte": 4000
}
}
}
]
}
}
}POST /shenyian/goods/_search
{
"query": {
"bool": {
"should": [ //下面的match查询的结构和range查询的结果的并集
{
"match": {
"goodsName": "手机 小米"
}
},
{
"range": {
"price": {
"gte": 2000,
"lte": 4000
}
}
}
]
}
}
}POST /shenyian/goods/_search
{
"query": {
"bool": { must中查询出来的结果然后排除must_not中的结果
"must": [
{
"match": {
"goodsName": "手机 小米"
}
},
{
"range": {
"price": {
"gte": 2000,
"lte": 4000
}
}
}
],
"must_not": [
{
"term": {
"goodsName": "华为"
}
}
]
}
}
}Mots-clés sont les suivants:
L'intersection de la correspondance && gamme combinée terme, match, plage, floue et ainsi sur les résultats de la requête: doit
Selon les résultats des résultats de la requête doit, ou devrait, puis retirer la requête must_not: must_not
devrait: une combinaison de terme, match, plage, etc. Résultat de la requête set et match || plage
En général: en même temps que le moût et must_not, ou en même temps que le doit et must_not
filtre (ce filtre est un terme de filtre, la même fonction et est donc considérée comme égale ...... MUST MUST)
3.8. Filtrer
Filtrer le champ d'affichage, vous ne voulez pas afficher ces champs peuvent être filtrés ....
comprend:
POST /shenyian/goods/_search
{
"query": {
"match": {
"goodsName": "华为"
}
},
"_source": {
"includes": ["goodsName","price"]
}
}ne comprend pas:
POST /shenyian/goods/_search
{
"query": {
"match": {
"goodsName": "华为"
}
},
"_source": {
"excludes": ["image"] 不想显示的字段
}
}3.8. Le tri, la pagination
POST /shenyian/goods/_search
{
"query": {
"match": {
"goodsName": "手机"
}
},
"sort": [ 排序
{
"price": {
"order": "desc"
}
}
],
"from": 0, 分页
"size": 2
}3.9. Mettez en évidence (mot-clé recherché décoloration)
POST /shenyian/goods/_search
{
"query": {
"match": {
"goodsName": "手机"
}
},
"highlight": {
"fields": {
"goodsName": {} //需要高亮的字段和上面的查询字段要一致
},
"pre_tags": "<font color=red>", //前置html标签
"post_tags": "</font>" //闭合html标签
}
}3.10. Polymérisation (paquet)
champ champ polymérisée doit être de type: mot - clé
| elasticsearch | mysql | |
|---|---|---|
| Polymérisation (paquet) | Pail (godet) | par groupe |
| moyen, max, min, count (*) est calculé à la suite d'un paquet | mesure | fonction d'agrégation |
polymérisation mysql:

Préparer les données:
PUT /car
{
"mappings": {
"orders": {
"properties": {
"color": {
"type": "keyword"
},
"make": {
"type": "keyword"
}
}
}
}
}POST /car/orders/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "红", "make" : "本田", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "红", "make" : "本田", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "绿", "make" : "福特", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "蓝", "make" : "丰田", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "绿", "make" : "丰田", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "红", "make" : "本田", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "红", "make" : "宝马", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "蓝", "make" : "福特", "sold" : "2014-02-12" }GET /car/orders/_search
{
"from": 0,
"size": 0, //为了不显示查询结果,不影响聚合
"aggs": {
"my_aggs_color": {//聚合起名
"terms": {//固定写法
"field": "color", //用什么字段来进行分组
"size": 10 //最多显示多少组
},
"aggs": {
"my_avg": {//给聚合函数起个名字
"avg": { //根据什么聚合函数来计算:avg max min
"field": "price" //什么字段来进行计算
}
}
}
}
}
}
(Cet article a provoqué Xiewang Hao, j'admire en particulier le grand Dieu, frère ho.)